论文原文:Hidden Technical Debt in Machine Learning Systems
在文章的开篇,Google 工程师们就指出:虽然开发和部署机器学习系统相对快速并且成本低廉,但是持续的维护比较困难且成本高昂。这是由于:
首先,机器学习系统本质上也是一种软件系统,所以它具有其它软件系统中存在的技术债务。更复杂的是,机器学习系统又有很多机器学习相关的技术债务。而这些问题往往存在于系统级别 (system level),而不是代码级别 (code level)。
基于上面的判断,作者们给出了基于他们实践经验的技术债务总结。
复杂模型侵蚀边界 (Complex Models Erode Boundaries)
作者们指出的是:在传统的软件工程中,人们往往需要用封装、模块化等等手段来定义一些抽象边界,以达到改善软件系统的可维护性的目的。然而,在机器学习系统中,由于其依赖于大量的外部数据,这样的边界变得难以准确描述和定义了。
举个例子,如果一个机器学习系统中的模型使用了特征 x1, x2, ..., xn。当 x1 的分布情况变化时,原有模型的其他特征的权重也会发生改变,这就给系统的管理带来了很大的挑战。作者们把这种影响叫做 CACE 原则:
这个问题称做 Entanglement,作者们给出了两个方案来改善这一问题:隔离模型和专注检测模型预测中的变化。
数据依赖比代码依赖成本更高(Data Dependencies Cost More than Code Dependencies)
在传统的软件工程中,人们往往可以借助于静态分析(Static Analysis)来发现和分析代码依赖关系。然而在机器学习系统中数据的依赖关系要更难以分析。
第一个问题就是数据的依赖关系可能很不稳定(Unstable data dependencies)。一个简单的例子就是一个机器学习系统可能把另一个系统的输出作为一个输入。然后,这种输入是不稳定的,并且变化是难以觉察的。作者们给出了一个可行的方案是对输入进行版本控制。
另一个问题就是不必要的数据依赖(Underutilized data dependencies),比如随着系统的变化不再需要的软件包。作者们建议用 leave-one-feature-out 的方法,来定期的检查和去除非必要的软件包。
由于数据依赖方面静态分析(Static analysis of data dependencies)工具的缺失,作者们也建议开发相应的工具来帮助分析数据依赖。
反馈循环(Feedback Loops)
对于在线学习系统而言,一个非常重要的特性就是模型需要持续更新。一种常见的实践是建立一个反馈循环,用于持续更新模型。
机器学习系统的反模式(ML-System Anti-Patterns)
在一个实际的机器学习系统中,仅仅一小部分代码是用于学习和预测的。随着时间的推移,一个机器学习系统中会出现各种各样系统设计中的反模式。
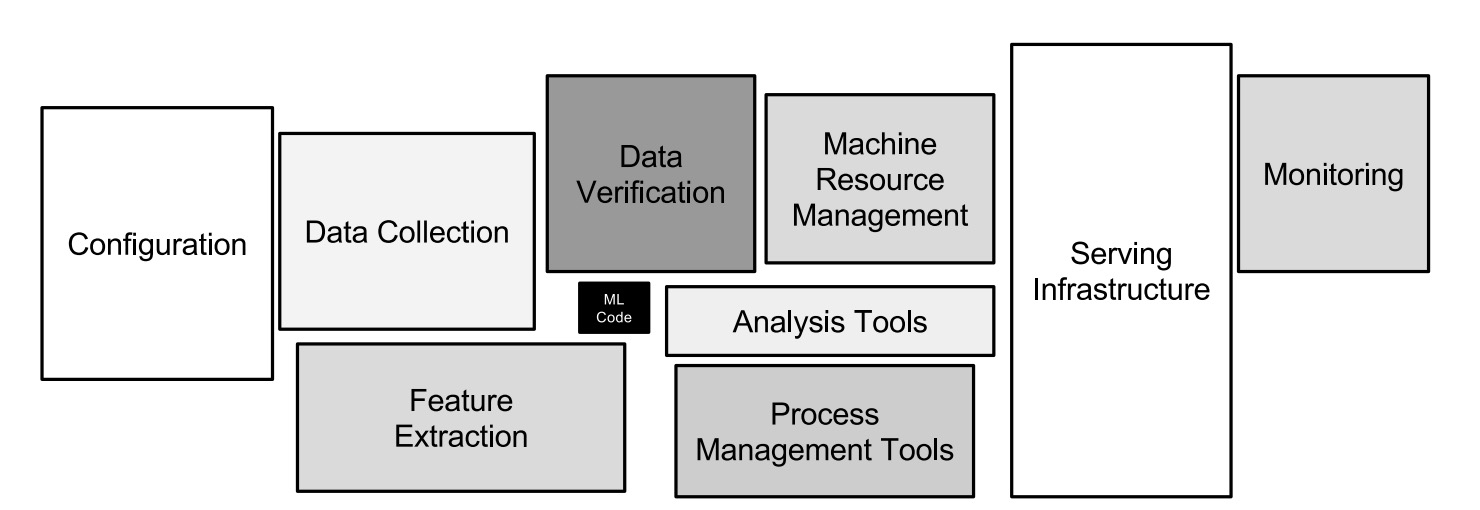
胶水代码(Glue Code)
作者们发现机器学习工程师们倾向于使用各种通用的机器学习库来编写代码,这就导致了系统中存在着大量的来自于庞大的通用机器学习库的代码。作者们的建议是把这些胶水代码用相同的 API 封装起来。
管道丛林(Piepline Jungles)
这里主要指的是数据准备(data preparation)阶段可能存在的问题。如果不加以注意,随着时间的推移,越来越多的输入信号加入到数据准备中,导致其变成一个混杂着各种爬虫、连接、取样等各种数据操作的丛林。有意思的是,作者们给出的解决方案是让工程师和科研工作者更多的合作,譬如在一个团队中,来帮助减少这种问题。
无用的实验代码路径(Dead Experimental Codepaths)
机器学习常常伴随着大量的试验,很容易导致在原有代码中产生各种条件分支。而后,随着条件分支越来越多,系统的技术债务也随之增加。作者们建议定期检查并删除这些无用的代码路径。
抽象债务(Abstraction Debt)
那么为什么会有这么多的技术债务问题呢?作者们的观点是我们目前还是缺乏用来描述机器学习系统的强抽象。无论是 MapReduce 还是 pramater-server 都达不到需要的抽象描述。
常见味道(Common Smells)
在软件工程中,有一个词语常常用来描述可能的代码结构问题,叫做坏的代码味道(bad code smell)。那么这里呢,作者们也列举了几个他们发现的可能的机器学习系统的坏的代码味道。
- 基础数据类型(Plain-Old-Data Type Smell)
- 多种语言(Multiple-Language Smell)
- 原型(Prototype Smell)
配置债务(Configuration Debt)
由于机器学习系统和算法的复杂性,一个大型的机器学习系统中常常存在着大量的配置,譬如使用哪些特征、数据如何选取、具体算法的参数设置、预处理的方式等等。作者们强调了配置的可维护性和易读性。譬如,配置也应该经过代码评审并提交到代码库中。
处理外部环境的变化(Dealing with Changes in the External World)
一个机器学习系统常常要和外部世界交互。然而,一个不容忽视的问题就是外部环境常常存在着各种变化。这无疑给机器学习系统的维护带来了极大的挑战。比如,一个机器学习系统应该如何监测呢?我们知道一个模型上线后,随着时间的推移以及新的数据的注入,常常会发生概念偏移(Concept drift),模型的准确率可能会有较大的变化。所以持续的监控和预警也就是非常必要的了。