概述
与 LLM 互动或开发 Agent 时,我们常常期望获得特定的输出结果。尤其在编程领域,生成的代码片段很可能直接被用作函数的输入。然而,有时无论 Prompt 多么明确,LLM 都可能偏离预定任务,甚至可能长篇大论。
本文将探讨常见的 LLM 结构化输出技术方案,讨论 LLM 结构化输出实践,以及如何确保大模型 100% 生成符合我们 schema 的结果。
什么是结构化输出
所谓结构化输出(Structured Outputs)指的是让 LLM 按照预先定义的 Schema 输出符合要求的结果。这种 Schema 不仅限于 JSON Schema,还可以是正则表达式(例如电子邮件、电话号码,甚至简单的 Y/N),甚至是代码。
例如,我们要生成一个包含 name 和 age
两个字段的 JSON 数据,其中 age 必须是一个数字。
{ |
实现结构化输出的方法有多种,包括:
- 提示设计(Prompt Design):最简单的方法是在提示中明确描述所需输出的结构。这也可以包括少样本提示(few-shot prompting),即在提示中提供输入和输出的示例。
- 微调(Fine-Tuning):通过使用示例输入和输出对,对模型进行任务专门的训练。这会使模型在推理时倾向于生成类似结构的响应。
- 多阶段提示(Multi-Stage Prompting):与其让模型直接生成结构化输出,不如让模型响应一系列提示,然后将生成的结果在外部组装成结构化输出。
- 专用服务(Specialized Services):OpenAI 提供了一种可选的 JSON 模式,确保 API 响应以有效的 JSON 格式返回,但它并不强制确保 JSON 架构和内容的准确性。不过,该功能目前已经被 OpenAI 废弃,转向了 Structured Outputs 功能(详见:https://platform.openai.com/docs/guides/structured-outputs#json-mode)。
这些技术的效果因任务的复杂度和模型的能力而异。然而,还有一种更强大的方法,即使在处理复杂任务的相对较弱模型时,也能保证精确的输出:Constrained Decoding(受限解码)。
Constrained Decoding 介绍
Constrained Decoding(受限解码)是一种通过操控 LLM 的 token 生成过程,将模型的下一个 token 预测限制为仅生成那些不违反所需输出结构的 token。可以简单理解为:
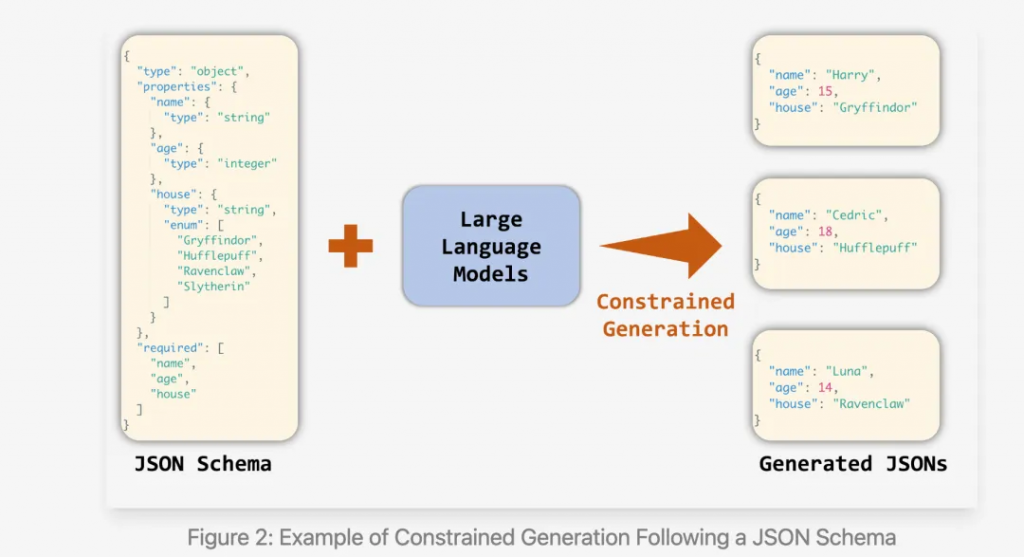
Constrained Decoding 的一般步骤如下:
- 定义约束规则:首先,我们需要定义约束规则。这些规则可以是正则表达式、上下文无关文法(CFG)等形式化的语法规则,或者是一些自定义的逻辑规则。
- LLM 生成候选 Token:基于当前上下文(即已经生成的 Token 序列),LLM 会生成一个候选 Token 列表,并为每个 Token 赋予一个概率值。
- 约束检查(Mask Gen):根据预定义的约束规则,检查候选 Token 列表中的每个 Token,确保它们符合设定的规则。
- 过滤(Apply Mask):将不符合规则的 Token 的概率值设置为 0(或极小值),从而排除这些 Token。
- 采样:根据过滤后的概率分布,从剩余的候选 Token 中随机采样一个 Token,作为下一个生成的 Token。
- 重复步骤 2-5,直到生成完整的文本序列。
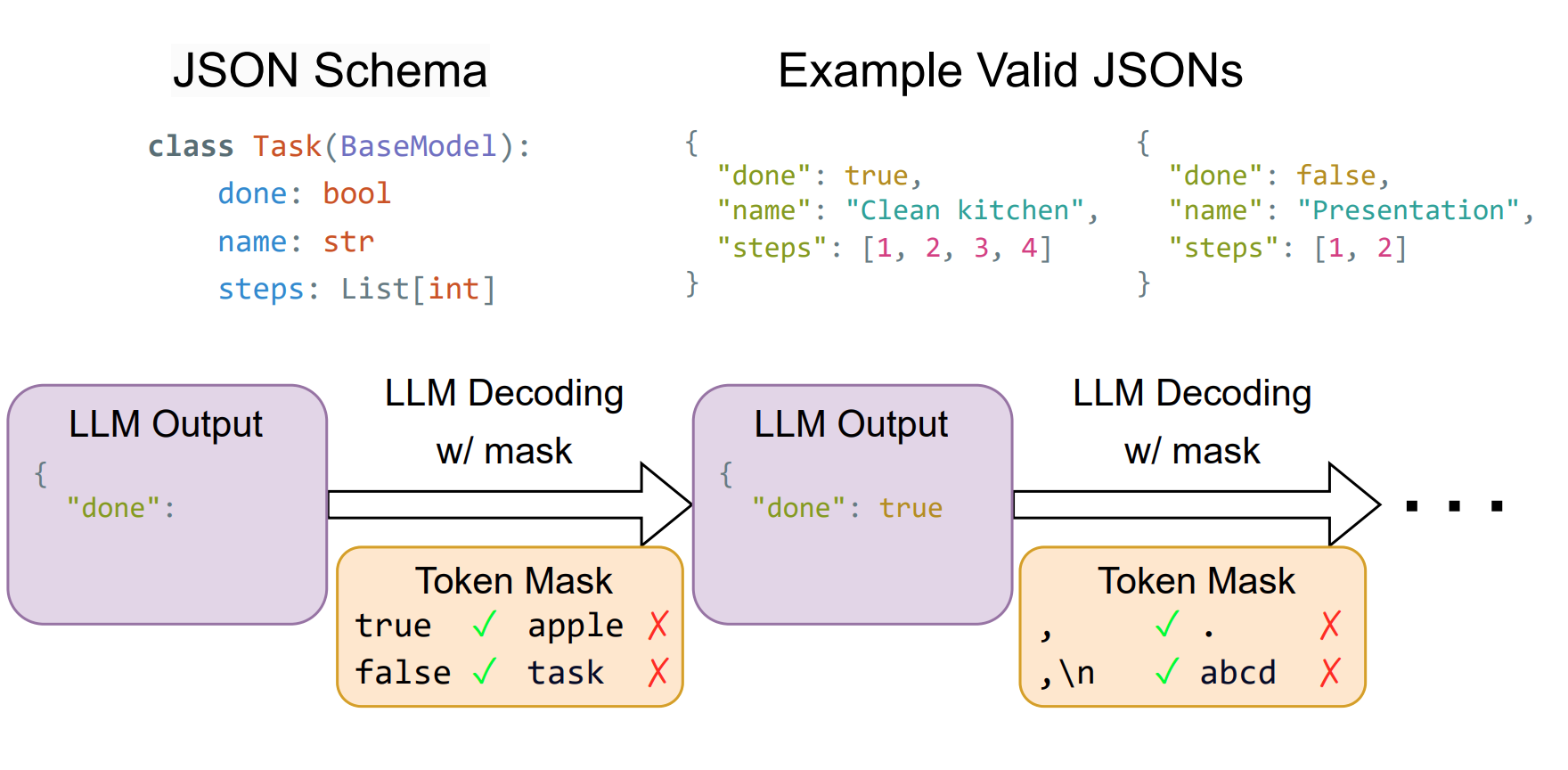
常见 Constrained Decoding 实现思路
Outlines:基于有限状态机解码
Outlines 通过将 JSON Schema 转换成正则表达式,然后基于该正则表达式构建有限状态机(FSM, Finite State Machine),引导 LLM 的生成。在 FSM 的每个状态下,我们可以计算允许的转换,并确定可接受的下一个 Token。这样,我们可以在解码过程中跟踪当前状态,并通过对输出应用 logit 偏置来过滤掉无效的 Token。具体可以参见论文:《Efficient Guided Generation for Large Language Models》。
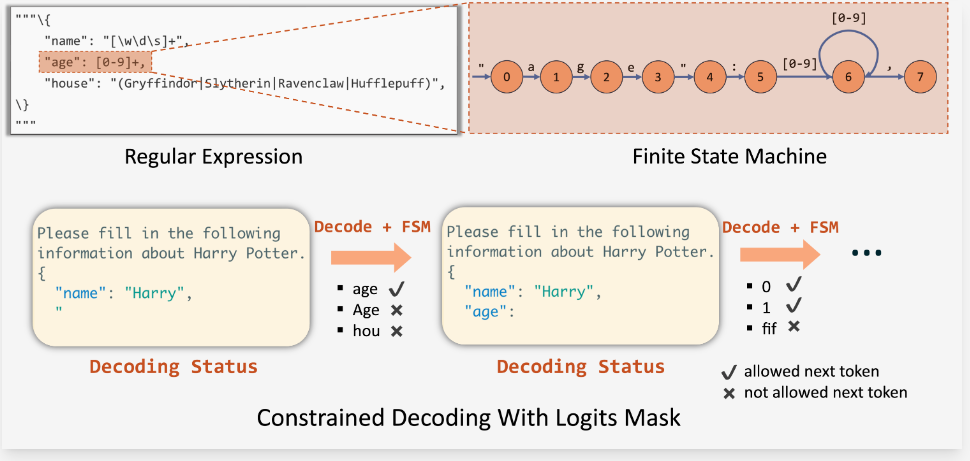
基于 FSM 的方法利用广义正则表达式来定义低层次的规则,这些规则可以应用于多种语法,如 JSON 架构、IP 地址和电子邮件等。
局限性:
由于有限状态机是在 Token 级别构建的,它在每一步只能通过一个 Token
来转换状态。因此,它一次只能解码一个 Token,这导致解码过程较为缓慢。
Guidance:基于交错解码
Guidance 提供了一组基于交错解码(Interleaved-based Decoding)的语法规则,并以 llama.cpp 作为后端。在这种方法中,给定的 JSON Schema 可以拆分成多个部分,每个部分包含一个分块的预填充部分(chunked prefill)或一个受限解码部分(constrained decoding)。这些部分交替执行。由于分块预填充可以在一次前向传递中处理多个 Token,因此它比逐个 Token 解码更为高效。
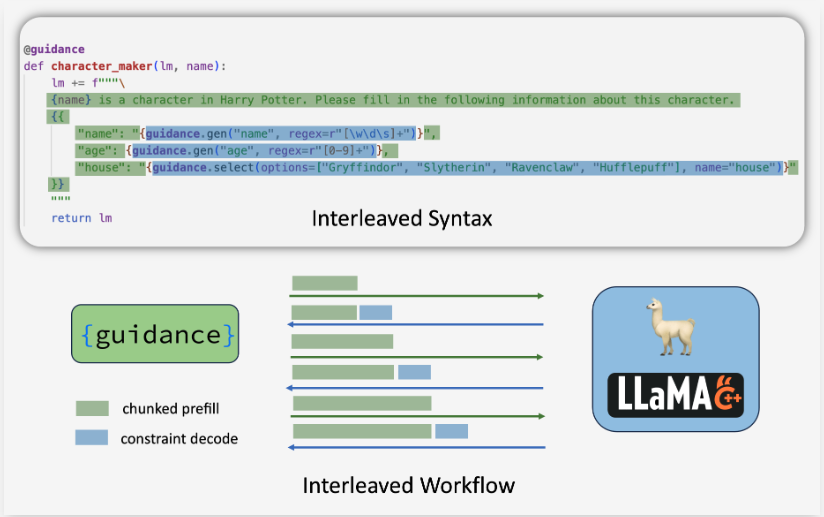
局限性:
- 交错解码方法需要自定义语法,因此比单独的正则表达式更具局限性,且表达能力较弱。
- 解码部分与分块预填充部分之间可能存在冲突,难以正确处理 Token 边界。
- 解释器与后端之间的频繁通信会带来额外的开销。
SGLang:基于压缩有限状态机的跳跃式解码
SGLang 提出的基于压缩有限状态机的跳跃式解码方法(Jump-Forward Decoding With a Compressed Finite State Machine)相较于原始 FSM,压缩了状态,合并了一些无需生成的状态,因此速度更快。
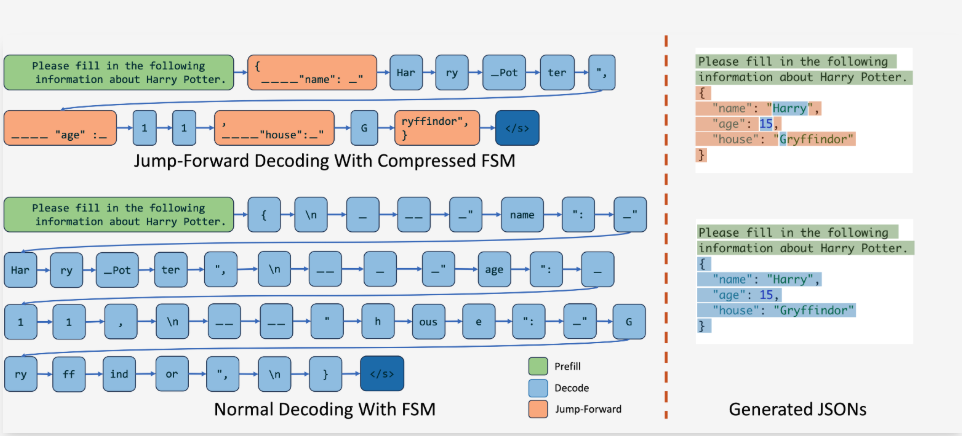
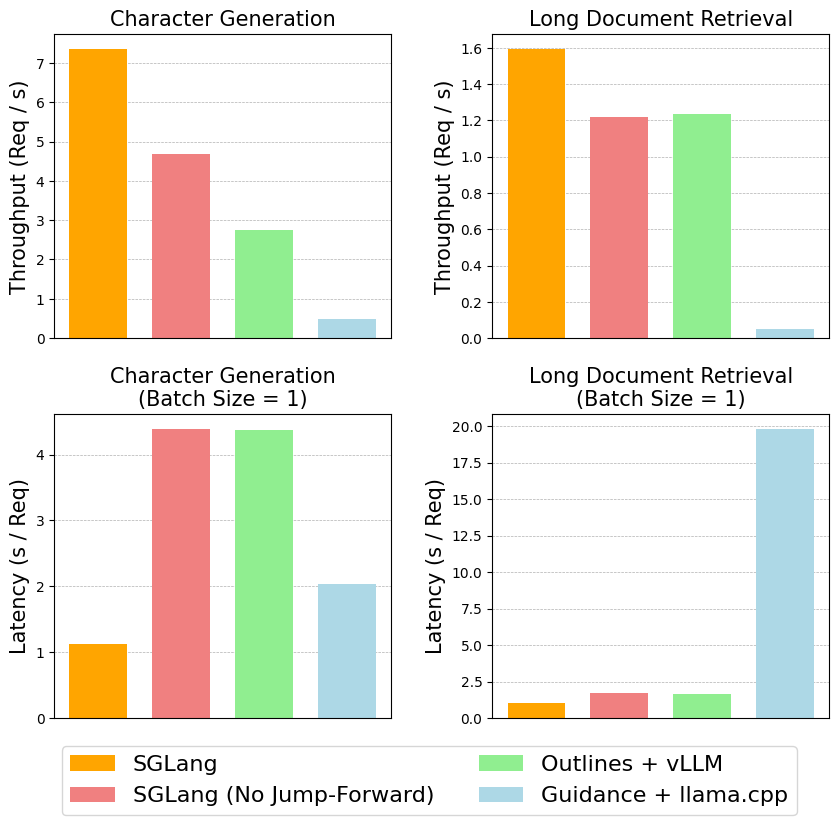
SGLang 相比 Outlines+vllm 和 Guidance+llama.cpp 速度提升 2.5 倍。
XGrammar:基于上下文无关语法解码
XGrammar 是 CMU 陈天奇团队的开源软件库,出自论文《XGrammar: Flexible and Efficient Structured Generation Engine For Large Language Models》。它采用上下文无关语法(CFG)解码,通过一组规则来定义结构。每条规则包含一个字符序列或其他规则,并允许递归组合来表示复杂结构。相比于正则表达式等其他格式,CFG 由于支持递归结构,能够提供更大的灵活性,适合描述 JSON、SQL 和领域特定语言(DSL)等常见语言。
下图展示了一个用于数组和字符串的 CFG,可以清晰看到其中的递归结构:
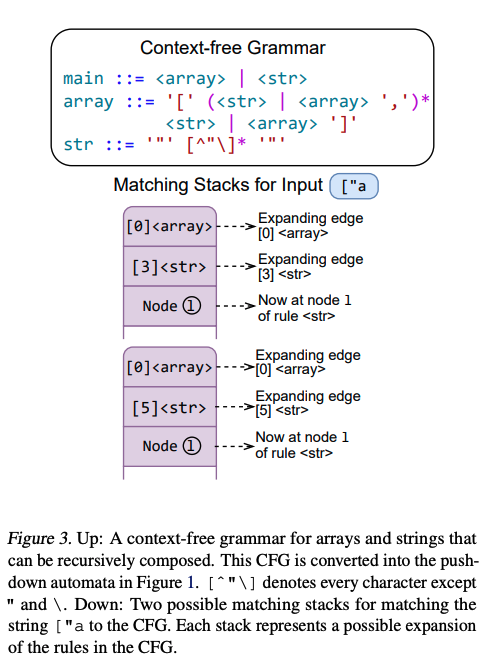
XGrammar 的核心思想是在下推自动机(Pushdown Automation)的每个位置,将词汇表划分为与上下文无关和与上下文相关的 Token。预先计算并缓存与上下文无关的 Token,存储在自适应 Token 掩码缓存中,并在运行时进行检索。其他与上下文相关的 Token 则在运行时动态检查。
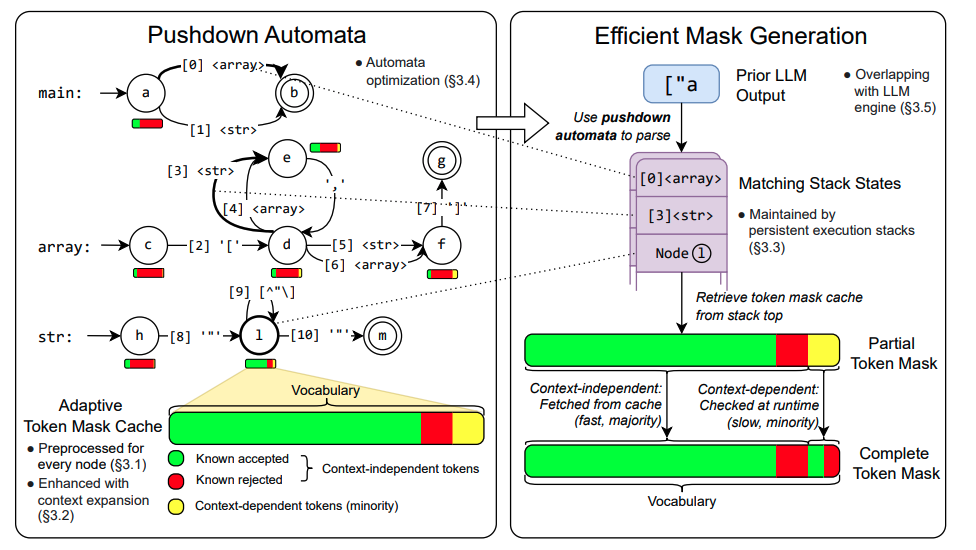
与 Outlines 和 llama.cpp 相比,XGrammar 的性能显著提升。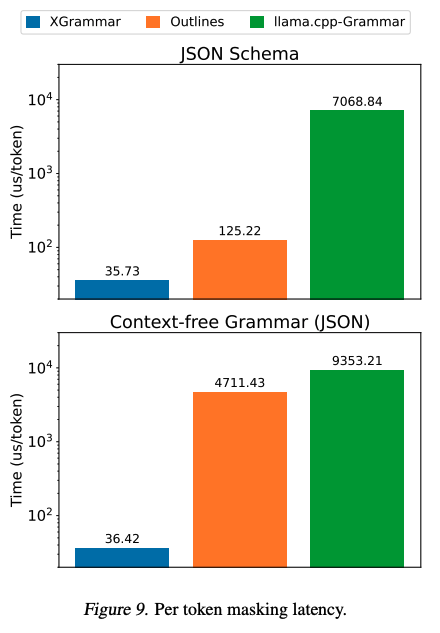
OpenAI: Only OpenAI Knows
无论是 Outlines 还是 SGLang,思路都是围绕 FSM,而 FSM 或正则表达式的表达能力有限,无法处理复杂的 Schema。今年 8 月,OpenAI 发布了 Structured Outputs 功能,从官方给出的部分例子来看,这种复杂的 schema 很难通过 FSM 表示,比如 UI Generation。因此,个人猜测 OpenAI 很可能采用了类似 XGrammar 的 CFG 解码方案。
总结
Constrained Decoding 虽然不是 LLM 领域的主流技术,但它对于 AGI 的落地具有巨大的推动作用。与早期通过提示词反复交互或模型微调相比,它代表了一个巨大的进步。
参考资料
- A Guide to Structured Outputs Using Constrained Decoding
- OpenAI Structured Outputs
- How to return structured data from a model
- Fast JSON Decoding for Local LLMs with Compressed Finite State Machine | LMSYS Org
- 浅谈约束解码(Constrained Decoding):一、如何让 LLM 乖乖听话
- MLC | Achieving Efficient, Flexible, and Portable Structured Generation with XGrammar
- GitHub - mlc-ai/xgrammar: Efficient, Flexible and Portable Structured Generation