概述
ReAct 设计模式首次提出于 2022 年的论文《ReACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS》。当时 ChatGPT 还没有出现,这一设计模式让大型语言模型(LLM)能够学会使用工具,具有一定的开创性。
工作原理
ReAct 的原理非常简单。在 ReAct 出现之前,推理(Reasoning)和行动(Acting)是分开的。ReAct 方法的核心是让模型生成交替的推理和行动步骤。这种方法允许模型在推理过程中制定、跟踪和更新行动计划,并处理例外情况。同时,模型可以通过行动与外部信息源(如知识库或环境)进行交互,以获取更多信息来支持推理过程。
例如,在一个复杂的问答任务中,ReAct 模型可以先通过推理确定需要搜索的信息,再通过行动进行搜索,获取结果后继续推理。
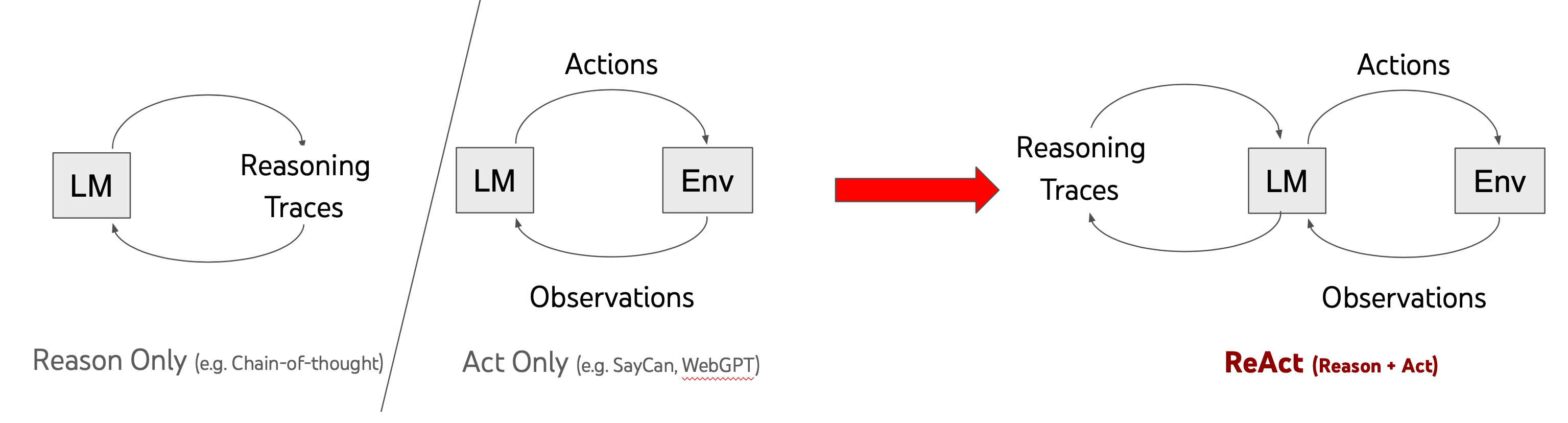
创新点
ReAct 方法的创新点包括:
- 减少幻觉和错误传播:通过与外部信息源(如维基百科 API)的交互,ReAct 模型在问答和事实验证任务中有效减少了幻觉和错误传播问题。
- 提高可解释性和可信度:ReAct 生成的任务解决过程更具可解释性,使人类更容易理解模型的决策基础。
- 超越单一方法:在交互决策任务中,ReAct 模型表现优于模仿学习和强化学习方法,展示了更高的成功率。
ReAct 设计模式举例
问题:在这座城市中,我可以去哪里找到一家评价好的日料店?
ReAct 模型的工作流程:
- 推理:
- 思考:“我要找一家评价好的日料餐厅。我可以先搜索一下这座城市中所有日料店的列表。”
- 行动:
- 行动:“搜索‘这座城市的日料店’。”
- 观察:“结果显示了一些日料店的名称和地址。”
- 推理:
- 思考:“接下来,我需要查看这些餐厅的评价。可以在搜索结果中选择一个餐厅,然后查找它的评价。”
- 行动:
- 行动:“搜索‘餐厅 A 的评价’。”
- 观察:“餐厅 A 的评价是 4.5 星,评价内容提到了食物美味,服务好。”
- 推理:
- 思考:“餐厅 A 的评价很好,但我还需要多比较几家餐厅。继续查看其他餐厅的评价。”
- 行动:
- 行动:“搜索‘餐厅 B 的评价’。”
- 观察:“餐厅 B 的评价是 4.0 星,评价内容提到了价格合理,但服务稍差。”
- 推理:
- 思考:“综合来看,餐厅 A 的评价更高,评价内容也更好。”
- 行动:
- 行动:“决定去餐厅 A。”
通过 ReAct 模型,你找到了一个评价很好的日料店,并且通过交替使用推理和行动的步骤,确保了决策的可靠性和信息的准确性。