JVM 运行时数据区域示意图如下所示:
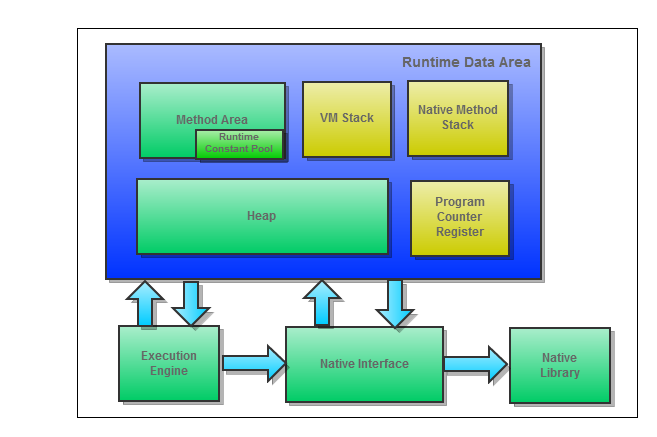
共享数据区域:Method Area、Heap
私有数据区域:VM Stack、Native Method Stack、Program Counter
Register
1)方法区(Method Area)
用于存储已被虚拟机加载的 class
信息、常量、静态变量、即时编译后的代码等数据。
Exception:OutOfMemoryError
2)Java 虚拟机栈(JVM Stack)
每个方法被执行时都会创建一个 Stack Frame
用于存储局部变量表、操作栈、动态链接、方法出口等信息。每个方法被调用直至执行完成,就对应着一个
Stack Frame 在虚拟机栈中从入栈到出栈的过程。
Exception:StackOverflowError、OutOfMemoryError
3)本地方法区(Native Method)
为使用 Native 方法服务的。
Exception:StackOverflowError、OutOfMemoryError
4)Java 堆(Java Heap)
JVM 中最大的一块区域。Java Heap 是被所有线程所共享,在 JVM
启动时创建。
在 JVM 规范中的描述如下:The heap is the runtime data area from
which memory for all class instances and arrays is allocated.
5)程序计数器(Program Counter Register)
用于指示当前线程所执行的字节码行号指示器。
Exception:None
6)运行时常量池(Runtime Constant Pool)
是方法区的一部分。用于存放编译时生成的各种字面变量和常用符号
Exception:OutOfMemoryError