1)Math.round(x)
round() 方法可把一个数字四舍五入。
2)Math.floor(x)
floor()
方法执行的是向下取整计算,它返回的是小于或等于函数参数,并且与之最接近的整数。
3)Math.ceil(x)
ceil()
方法执行的是向上取整计算,它返回的是大于或等于函数参数,并且与之最接近的整数。
1)Math.round(x)
round() 方法可把一个数字四舍五入。
2)Math.floor(x)
floor()
方法执行的是向下取整计算,它返回的是小于或等于函数参数,并且与之最接近的整数。
3)Math.ceil(x)
ceil()
方法执行的是向上取整计算,它返回的是大于或等于函数参数,并且与之最接近的整数。
1)删除左右两端的空格
function trim(str){ |
2) 删除左边的空格
function ltrim(str) { |
3) 删除右边的空格
function rtrim(str) { |
安装自动选择最快镜像插件
安装插件 fastestmirror,可以让 yum 管理器自动搜索最快源下载
sudo yum -y install yum-fastestmirror |
添加 rpmfusion 源
sudo yum rpm -ivh http://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-stable.noarch.rpm |
安装 GNOME-tweak-tool
sudo yum install gnome-tweak-tool |
标题栏添加“最大化/最小化/关闭”按钮
可以通过安装 gnome-tweak-tool 来设置。打开
gnome-tweak-tool,“shell"-> Arrangement of buttons on the
titlebar”可选择"All"
安装 gconf-editor:
sudo yum install gconf-editor |
让桌面显示文件,激活右键功能
打开 gnome-tweak-tool,"Desktop","Have file manager handle the
desktop","开启"
安装鼠标右键“在终端中打开”
sudo yum install nautilus-open-terminal |
安装 Gnome Do
sudo yum install gnome-do |
安装 Compiz
sudo yum install compiz-manager |
安装 Docky
sudo yum install docky |
安装解压缩软件 7z
sudo yum install p7zip p7zip-plugins |
安装截图工具 shutter
sudo yum install shutter |
安装小熊猫
sudo yum install ailurus |
安装 MSN 客户端
sudo yum install emesene |
安装邮件提醒
sudo yum install mail-notification mail-notification-evolution-plugin |
安装 FTP 客户端
sudo yum install filezilla |
安装 smplayer
sudo rpm -ivh http://rpm.livna.org/livna-release.rpm |
安装 Rhythmbox mp3 wma 支持插件
sudo yum install gstreamer-plugins-ugly gstreamer-plugins-bad gstreamer-ffmpeg |
安装 EasyTag
sudo yum install easytag |
安装 g++
sudo yum install gcc-c++ |
*OS:Fedora 16 TexLive Version: TexLive 2011
1)添加 rpm 源*
sudo rpm -i http://jnovy.fedorapeople.org/texlive/2011/packages.fc16/texlive-release.noarch.rpm |
(其他版本可以到http://jnovy.fedorapeople.org/找下对应源)
2)安装 texlive2011
sudo yum clean all |
3)下载中文库包
Url:http://bj.soulinfo.com/~hugang/tex/tex2007/YueWang-zhfonts-final_1.01.tar.bz2
解压后取出
texmf-var,将里面的内容分别复制到/usr/share/texlive/texmf-local
和/usr/share/texlive/texmf-var 里面
然后执行 sudo texhash,重新建立数据库
4)测试 documentclass{article}
usepackage{CJKutf8}
begin{document}
begin{CJK}{UTF8}{hei}
Hello , Latex !
你好,Latex
end{CJK}
end{document}
保存 test.tex 退出,然后,执行
latex test.tex
dvipdfm test.dvi
PS:如果运行时出现 CJKutf8.sty 找不到,执行 sudo yum install 'tex(CJKutf8.sty)'解决
安装SVNKit http://svnkit.com/download.php
Window > Preferences, Team > SVN and change there the JavaHL client to SVNKit. Restart.
安装 rpm-build 包 yum install rpm-build
在 Fedora 下安装了 Virtualbox,发现运行时出现以下问题:
Kernel driver not installed (rc=-1908)
The VirtualBox Linux kernel driver (vboxdrv) is either not loaded or there is a permission problem with /dev/vboxdrv. Please reinstall the kernel module by executing ‘/etc/init.d/vboxdrv setup’ as root. Users of Ubuntu, Fedora or Mandriva should install the DKMS package first. This package keeps track of Linux kernel changes and recompiles the vboxdrv kernel module if necessary.
然后以 root 身份运行/etc/init.d/vboxdrv setup 结果提示:
Stopping VirtualBox kernel modules [确定] Uninstalling old VirtualBox DKMS kernel modules [确定] Trying to register the VirtualBox kernel modules using DKMSError! Bad return status for module build on kernel: 3.2.3-2.fc16.i686 (i686) Consult /var/lib/dkms/vboxhost/4.0.8/build/make.log for more information.[失败] (Failed, trying without DKMS) Recompiling VirtualBox kernel modules [失败] (Look at /var/log/vbox-install.log to find out what went wrong)
解决方法: 先尝试:
sudo yum install -y kernel-headers kernel-devel dkms gcc |
如果执行此操作,仍然出现上述错误。可以参考下面 安装 PAE 包, sudo yum install kernel-PAE-devel 。 完成后再执行 sudo/etc/init.d/vboxdrv setup
【试题描述】
n 是一个奇数,求证 n(n^2-1)能被 24 整除
【试题来源】网易
【试题分析】
令 n=2k + 1,则 n(n^2 - 1) = (2k + 1)((2k + 1)^2 - 1) = 4k(k + 1)(2k + 1) = 4*6(1^2+ 2^2 + 3^2 … k^2)
因此 n(n^2-1)能被 24 整除
编辑距离,又称 Levenshtein 距离(也叫做 EditDistance),是指两个字串之间,由一个转成另一个所需的最少编辑操作次数,如果它们的距离越大,说明它们越是不同。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。俄罗斯科学家 Vladimir Levenshtein 在 1965 年提出这个概念。因此也叫 Levenshtein Distance,常用来衡量字符串相似度。
【算法过程】
int LevenshteinDistance(char s[1..m], char t[1..n]) |
【代码】
#Levenshtein Distance Algorithm |
1)点击“服务器管理器” 
2)点击“角色”->“添加角色” 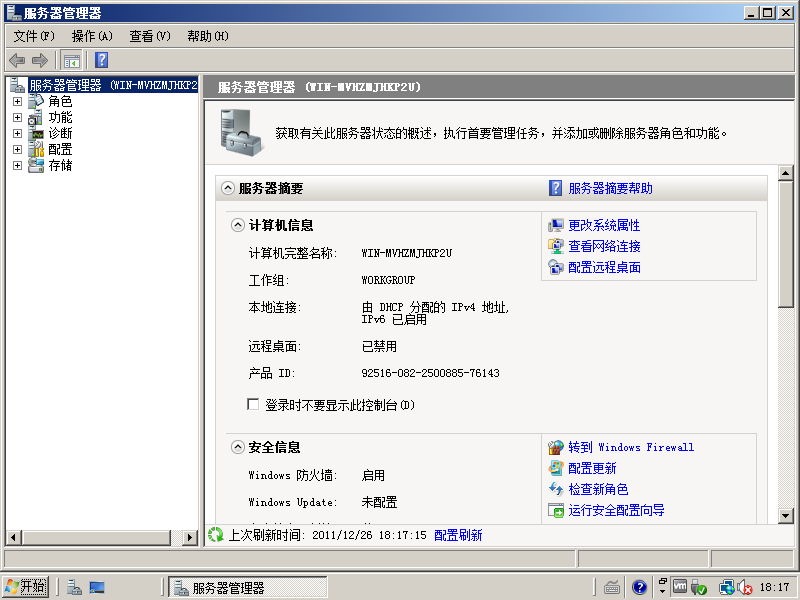
3)点击“下一步” 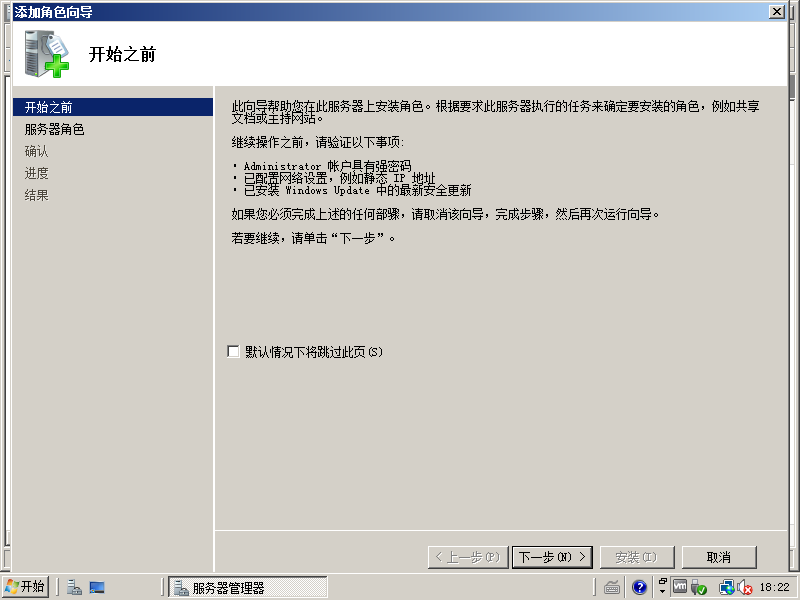
4)选中“Web 服务器(IIS)” 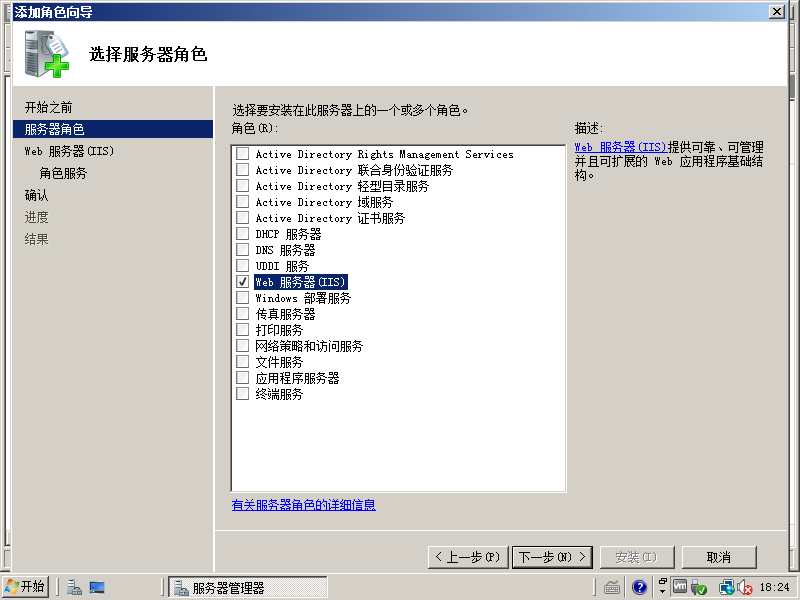
5)点击“添加必需的功能”,点击下一步 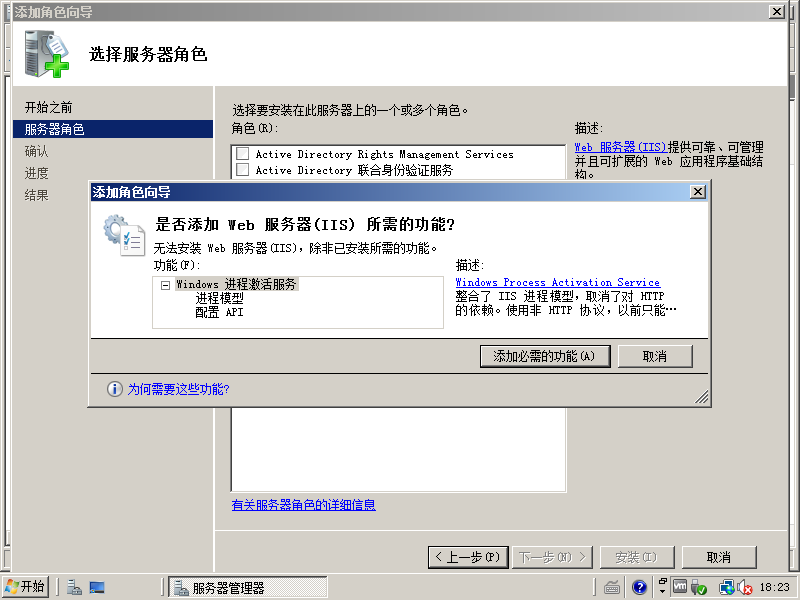
6)点击“下一步” 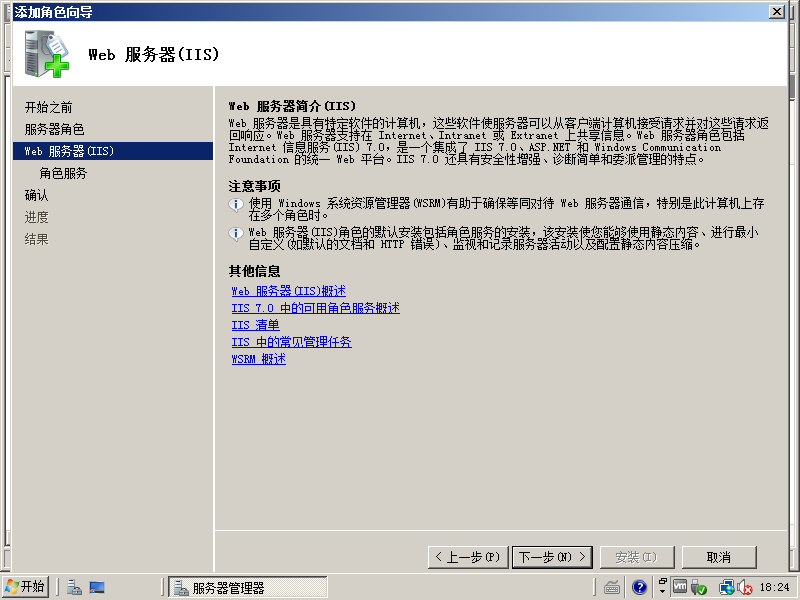
7)选中“应用程序开发”->“ASP.NET”以及“FTP 发布服务” 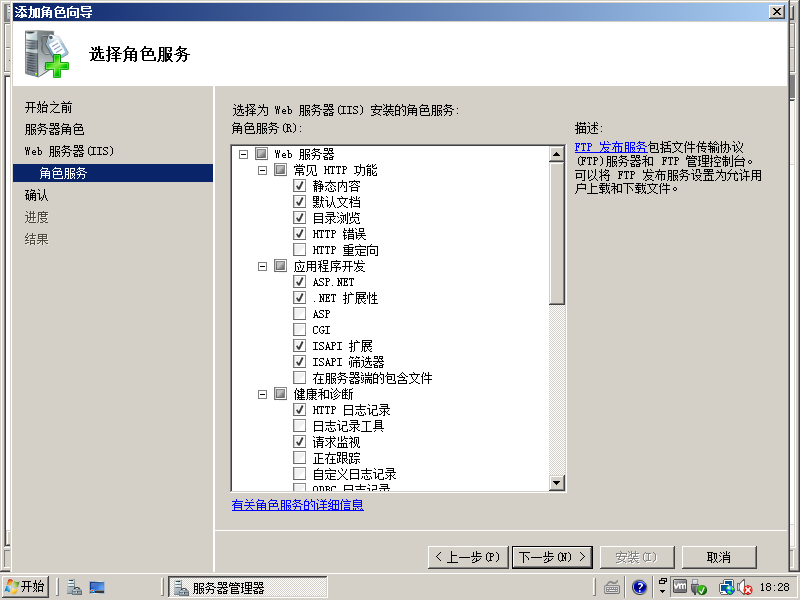
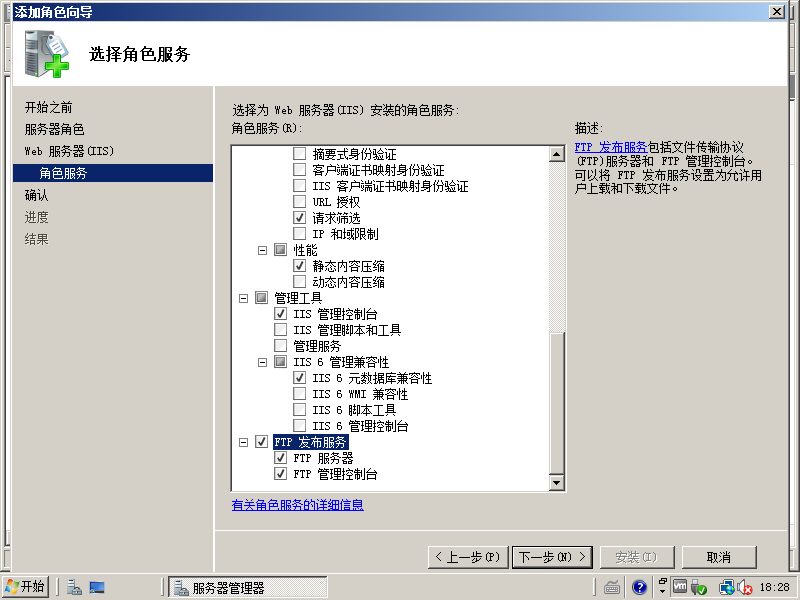
8)点击安装 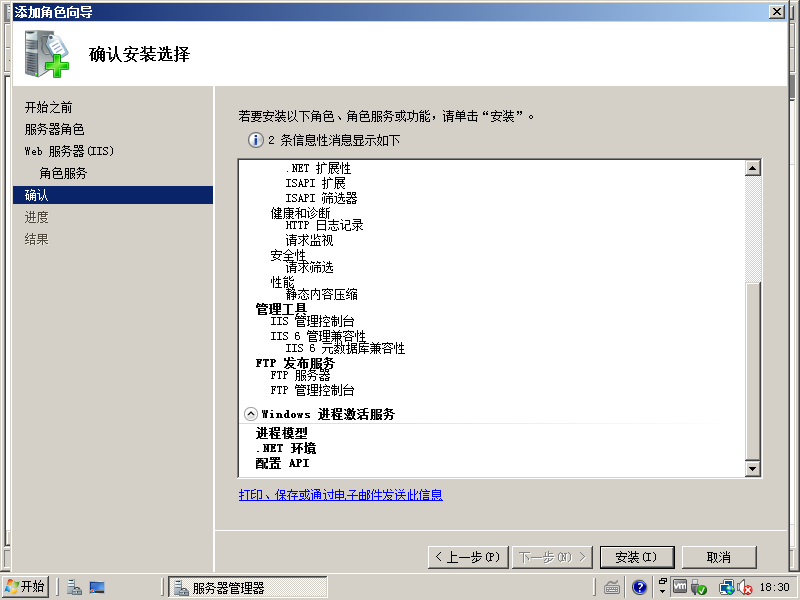
9)测试 IIS,在 IE 中输入 http://localhost/,出席下面页面 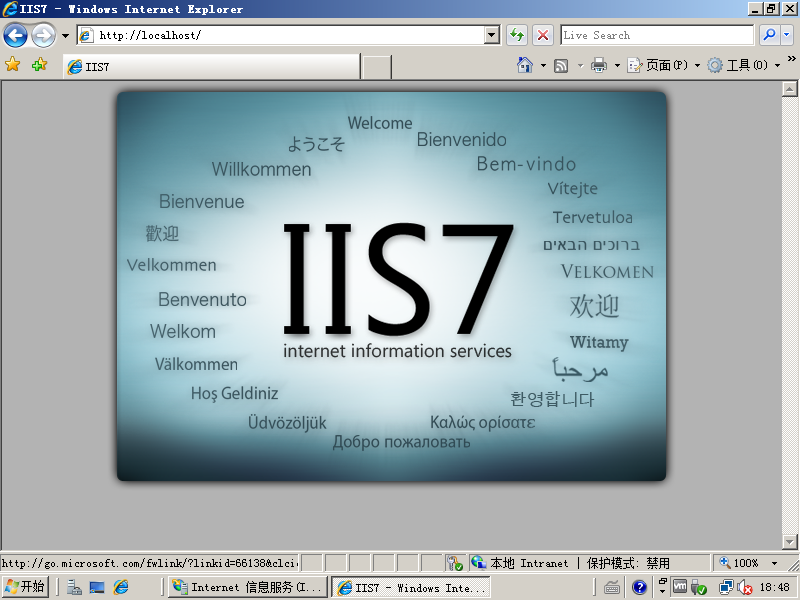
10)点击查看网络连接,配置 IP 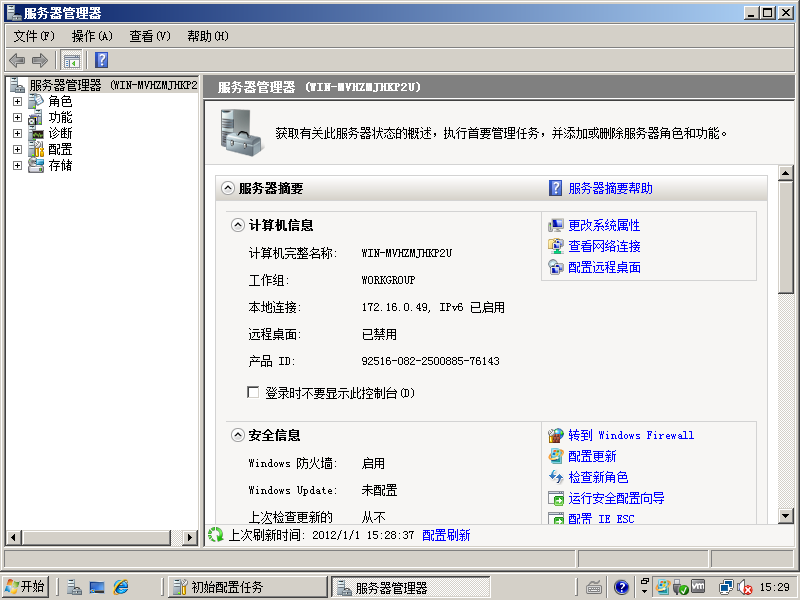
11)开启网络连接