1)语言选择,点击“下一步” 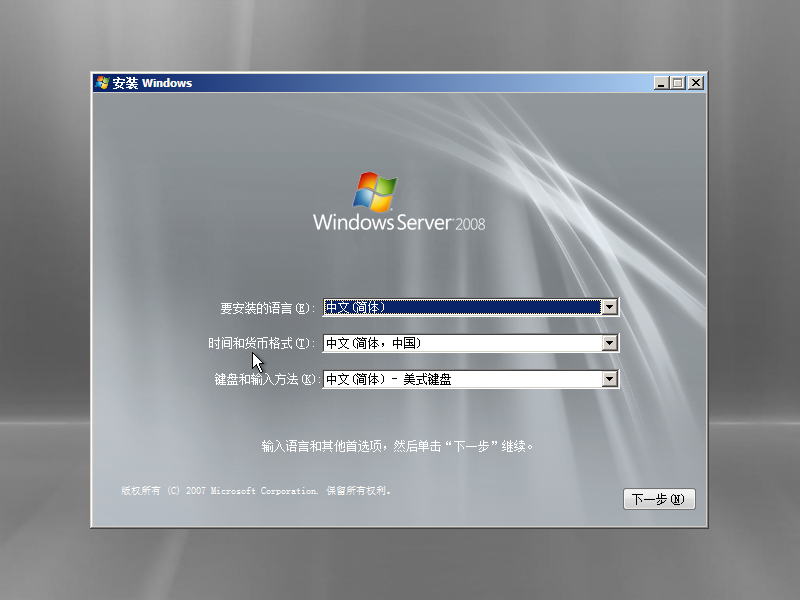
2)点击“现在安装” 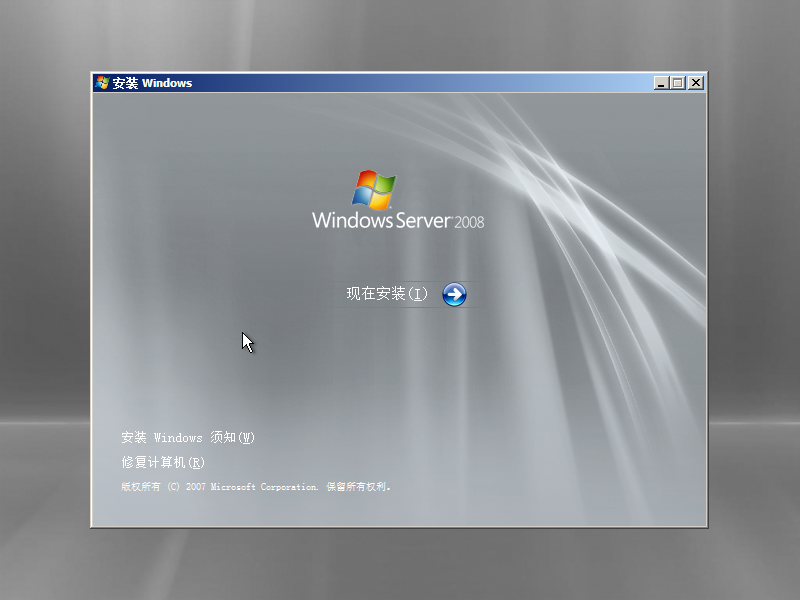
3)选择所要安装的版本,点击“下一步” 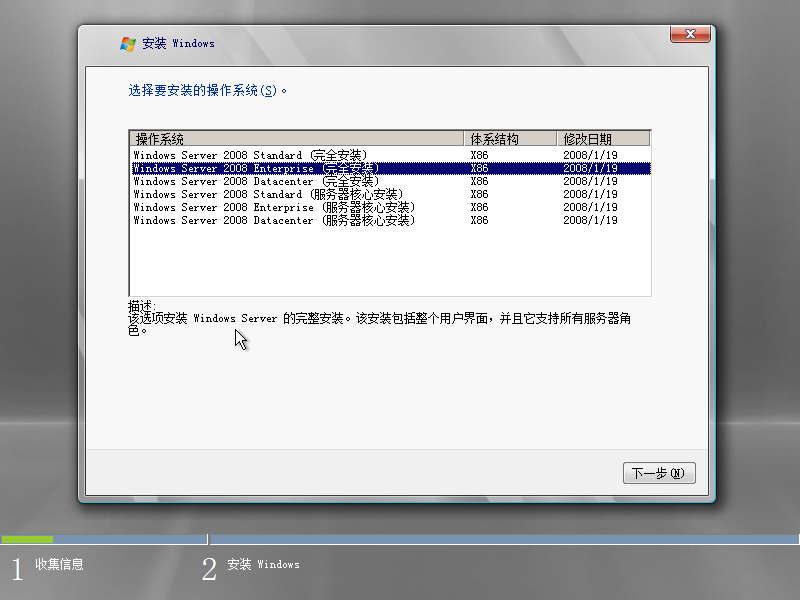
4)勾起“我接受许可条款”,点击“下一步” 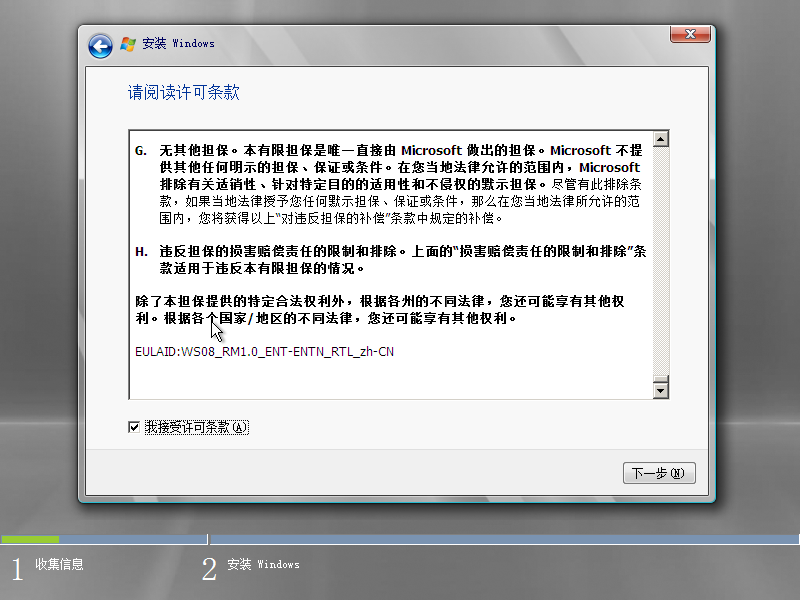
5)点击“自定义(高级)” 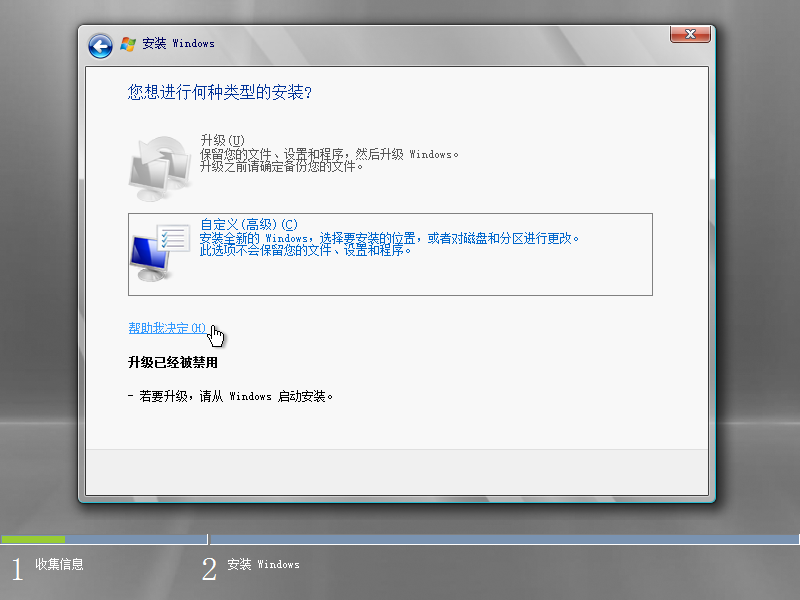
6)选择安装位置,点击“下一步” 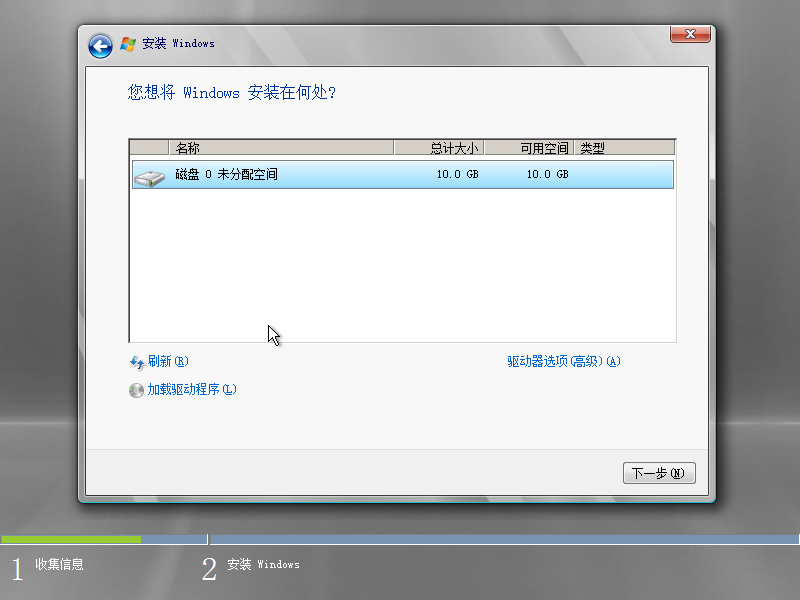
7)开始安装 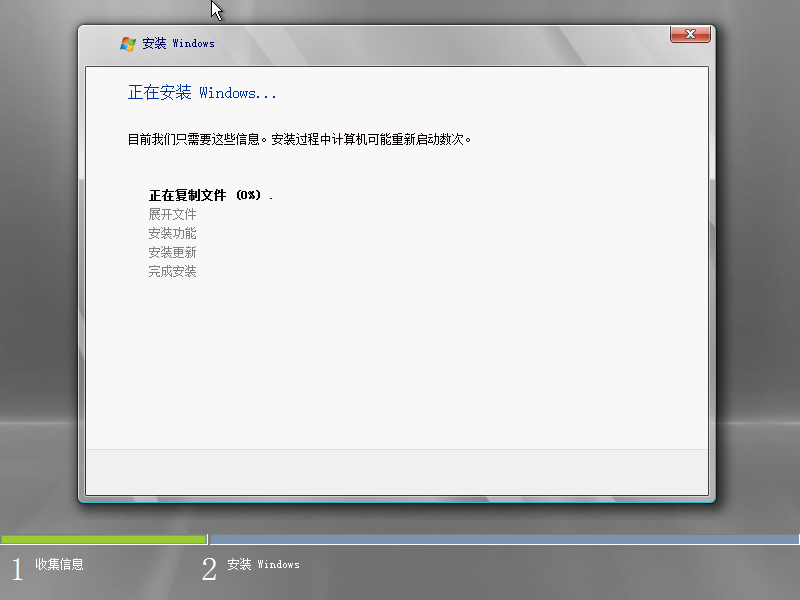
8)首次登录需修改密码 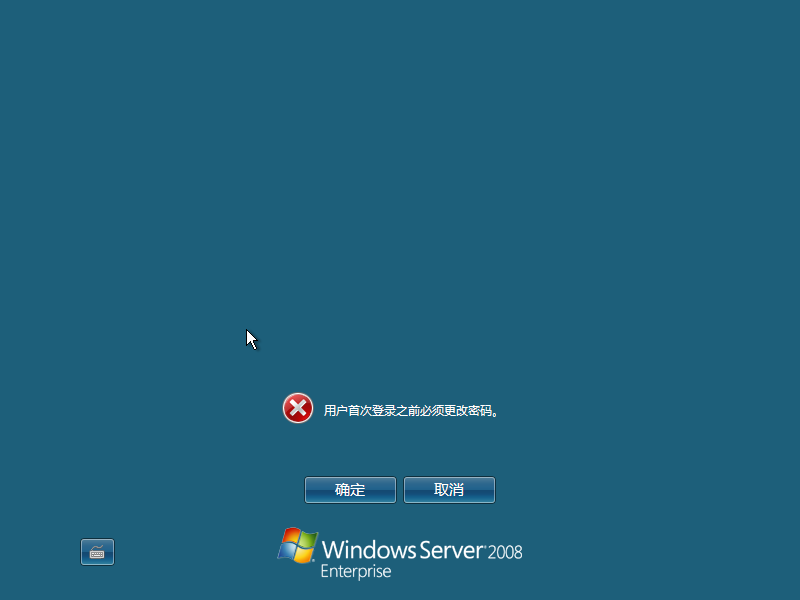
9)修改密码(密码需包含大写字母,小写字母,数字,长度超过 8 位) 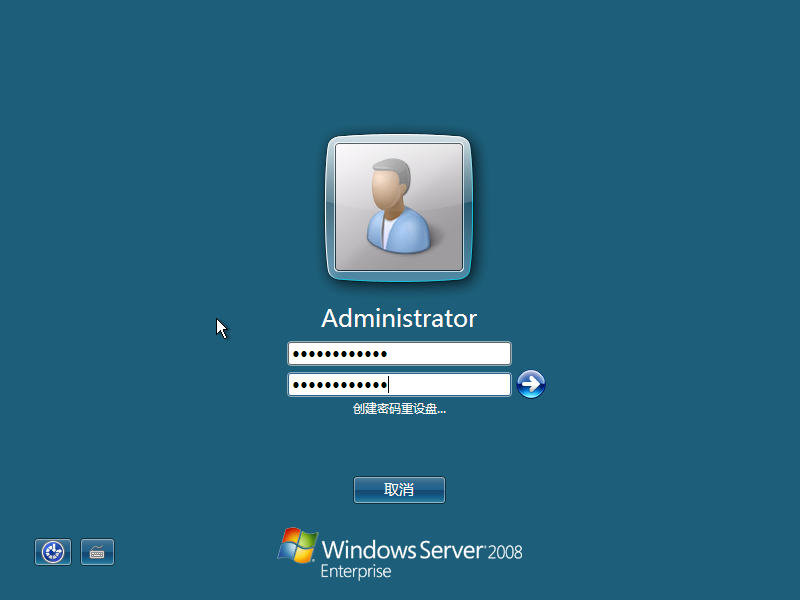
1)语言选择,点击“下一步”
2)点击“现在安装”
3)选择所要安装的版本,点击“下一步”
4)勾起“我接受许可条款”,点击“下一步”
5)点击“自定义(高级)”
6)选择安装位置,点击“下一步”
7)开始安装
8)首次登录需修改密码
9)修改密码(密码需包含大写字母,小写字母,数字,长度超过 8 位)
【试题描述】
在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。(PS:数组的不一定是n*n的矩阵)
【试题来源】未知
【试题分析】
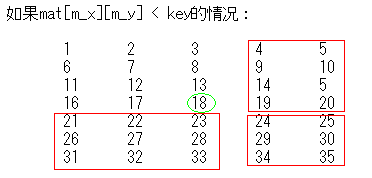
总体思路就是使用递归+二分查找的方法,具体过程如下所示:
设二分查找的中间点为(m_x,m_y),其中 m_x = (s_x +e_x) / 2 m_y = (s_y
+e_y) / 2 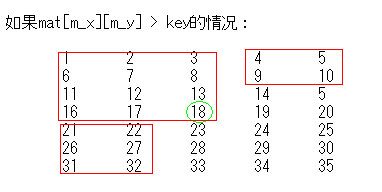
【源代码Python】
#!/usr/bin/env python |
【参考资料】
http://topic.csdn.net/u/20111214/10/d09797c3-d1ce-4249-b1e5-8b693b4c85f8.html"http://topic.csdn.net/u/20111214/10/d09797c3-d1ce-4249-b1e5-8b693b4c85f8.html> http://justjavac.iteye.com/blog/1310178 http://nubnub.blog.163.com/blog/static/169186347201192411857362/
1 、搜索订阅
优酷中进行“视频搜索”的,如排行榜里的种种是是非非,如成龙等人的优酷,非本人视频空间,而是大量网友的上传后进行的视频搜索整合得到,都可通过复制网址订阅。
2、专辑订阅
进入专辑首页,网址里后缀中为 id_*。直接复制网址到
google reader 的添加订阅即可。
3、个人视频空间全部视频订阅:
由于优酷像新浪微博一样屏蔽了用户的真实
id,导致直接复制网址订阅无效。后缀中 id 后是一串字母,这是优酷对真实 id
进行了加密的结果。
解决方法:网页空白处右击,点击“查看源文件”。再打开的网页源文件中, Ctrl
+F ,查找 id ,一般第二个 id 后的一串数字即为用户的真实 id 找到真实 id
后,再按照目前优酷视频空间的 RSS 的一般格式:http://www.youku.com/user/rss/id/真实
id(一串数字),添加到 google reader 即可。
转自:http://biotech.ustc.edu.cn/forum/forum.php?mod=viewthread&tid=10663
1)LPAD 方法:
SELECT LPAD(sal,8,'0') FROM |
2)TO_CHAR 方法
SELECT TO_CHAR(sal,'00000000') From |
3)SUBSTR 方法
SELECT SUBSTR('00000000'||sal,-8) FROM |
=================================================================== 补充:
LPAD 和 RPAD 用法: Lpad()函数的用法: lpad 函数将左边的字符串填充一些特定的字符其语法格式如下: lpad(string,n,[pad_string]) string:可是字符或者参数 n:字符的长度,是返回的字符串的数量,如果这个数量比原字符串的长度要短,lpad 函数将会把字符串截取成从左到右的 n 个字符; pad_string:是个可选参数,这个字符串是要粘贴到 string 的左边,如果这个参数未写,lpad 函数将会在 string 的左边粘贴空格。 例如: lpad('tech', 7); 将返回' tech' lpad('tech', 2); 将返回'te' lpad('tech', 8, '0'); 将返回'0000tech' lpad('tech on the net', 15, 'z'); 将返回 'tech on the net' lpad('tech on the net', 16, 'z'); 将返回 'ztech on the net'
Rpad()函数的用法: rpad 函数将右边的字符串填充一些特定的字符其语法格式如下: rpad(string,n,[pad_string]) string:可是字符或者参数 n:字符的长度,是返回的字符串的数量,如果这个数量比原字符串的长度要短,lpad 函数将会把字符串截取成从左到右的 n 个字符; pad_string:是个可选参数,这个字符串是要粘贴到 string 的右边,如果这个参数未写,lpad 函数将会在 string 的右边粘贴空格。 例如: rpad('tech', 7); 将返回' tech' rpad('tech', 2); 将返回'te' rpad('tech', 8, '0'); 将返回'tech0000' rpad('tech on the net', 15, 'z'); 将返回 'tech on the net' rpad('tech on the net', 16, 'z'); 将返回 'tech on the netz'
参考资料:http://hi.baidu.com/ljw460/blog/item/5788594a1b55ff2608f7efc5.html
一般情况下,可以如下:
select rownum, a from A; |
但是当后面有多表关联,order by 排序的时候,
select rownum, a from A,B where A.a=B.b order by A.a; |
rownum 就可能会乱了。
这时候,可以利用分析函数 rank()来实现:
select rank() over(order by t.b) rowno, t.a, t.c from test t order by t.b; |
这样就既可以排序,又可以自动加上连续的序号了。
参考资料: http://yuaoi.iteye.com/blog/767889 http://www.cnblogs.com/mycoding/archive/2010/05/29/1747065.html
一、使用 Indexer 建立文本文件索引
这里简化为对某一目录下面的所有后缀为“.py”的文件建立索引。
''' |
运行结果:
Indexer.py 将在 index 目录下建立一些索引文件,用于对.py 文件建立索引
二、使用 Searcher 检索文件
下面程序中实现了对文件的检索,其中参数 q 是一个表达式,可以理解为检索使用的关键字,如果文件中包含次关键字将被检索出来
''' |
【试题描述】
有一名员工发现日历已经7天没有翻了,于是他连着翻了7页,7天的总和刚好是138,问这一天是几号?
【试题分析】
1)假设7天在同一个月,设第一天为X,那么应该满足等差数列之和(2X+6)7/2
= 138,得到的X不为整数,所以应该是跨两个月。
2) 假设跨到第二个月1号,那么天数之和应该为(2X+5)6 + 1 =
138,不满足条件
3) 假设跨到第二个月2号,那么天数之和应该为(2X+4)*5 + 1 + 2 =
138,满足条件,X为25
那么七张日历数字应该为:25,26,27,28,29,1,2;也就是说日历是从闰年的2月25日到3月2日。
那么翻日历的那天应该是3月3日。
【试题描述】
已知有个rand7()的函数,返回1到7随机自然数,让利用这个rand7()构造rand10()随机1~10。
【试题分析】
1)要保证rand10()在整数1-10的均匀分布,可以构造一个1-10n的均匀分布的随机整数区间(n为任何正整数)。假设x是这个1-10n区间上的一个随机整数,那么x%10+1就是均匀分布在1-10区间上的整数。
2)接下来利用(rand7()-1)*7+rand7()构造出均匀分布在1-49的随机数:
首先rand7()-1得到一个离散整数集合{0,1,2,3,4,5,6},其中每个整数的出现概率都是1/7。那么(rand7()-1)7得到一个离散整数集合A={0,7,14,21,28,35,42},其中每个整数的出现概率也都是1/7。而rand7()得到的集合B={1,2,3,4,5,6,7}中每个整数出现的概率也是1/7。显然集合A和B中任何两个元素组合可以与1-49之间的一个整数一一对应,也就是说1-49之间的任何一个数,可以唯一确定A和B中两个元素的一种组合方式,反过来也成立。由于A和B中元素可以看成是独立事件,根据独立事件的概率公式P(AB)=P(A)P(B),得到每个组合的概率是1/71/7=1/49。因此(rand7()-1)*7+rand7()生成的整数均匀分布在1-49之间,每个数的概率都是1/49。
3)由于出现的每个数的出现都是相对独立的,所以剔除41-49后剩下1-40也应该是均匀分布。
【CodeBy C Language】
int rand10() { |
【参考资料】 http://topic.csdn.net/u/20110926/11/AD722874-BCE1-4DFE-ADE1-DC4C7C293FF2.html http://blog.csdn.net/ljsspace/article/details/6820753"http://blog.csdn.net/ljsspace/article/details/6820753>
用 dos 进入到 VirtualBox 的安装目录下,找到 VBoxManage.exe
执行:
VBoxManage.exe setextradata WinXP_JP "VBoxInternal/Devices/VMMDev/0/Config/GetHostTimeDisabled" "1″ |
''' |