IPALA 信息管理方法是对 Tiago Forte 的 P.A.R.A 方法的优化,包含收集箱(Inbox)、项目(Projects)、领域(Areas)、资料库(Library)和归档(Archives)。该方法适用于笔记和各类资料的整理,帮助提高信息管理的效率和有序性。
如何给自己和家人配置保险
这篇文章详细介绍了如何通过购买商业保险来保障自己和家人。它首先解释了保险的基本作用和可靠性,接着分别介绍了医疗险、意外险、重疾险和定期寿险的功能和选择策略。最后,文章根据不同年龄段(未成年人、青壮年、中年和老年)的需求,提供了具体的保险配置建议,帮助读者合理规划保险购买。
Readwise Reader迁移到Omnivore指南
如何导出数据
在 Readwise Reader 中,"Preference" -> "Export account data"

导入链接
Readwise Reader 导出的数据格式与 Omniovre 并不兼容。数据格式的转换可以参考这个项目:https://github.com/omnivore-app/readwise-reader-csv-to-omnivore-csv
Omnivore 提供了一个非常简单易用的导入方式,就是文件拖拽到软件中即可。
导入 OPML
目前 Omnivore 并没有提供导入 OPML 的功能,不过可以利用这个项目完成 Feed 导入:https://github.com/edleeman17/omnivore-opml-import
个人知识管理体系 - 工具篇
本文介绍了作者多年构建的独特知识获取与管理方法论,旨在帮助读者优化日常工作和学习。文中详细介绍了一系列实用工具,如微信读书、Readwise和Obsidian等,用于阅读、笔记同步、信息管理和回顾,以及如何利用这些工具提高学习和信息管理的效率。
个人知识管理体系 - 方法论篇
本文介绍了作者多年构建的独特知识获取与管理方法论,旨在帮助读者优化日常工作和学习。文中首先介绍了关键的工具和技术,如笔记软件和任务管理工具,以及如何使用这些工具来捕捉灵感、整理思路和管理待办事项。知识管理工作流被分为三个主要阶段:输入、内化和输出。输入阶段涉及从多个信息源采集信息;内化阶段则是通过个人理解转化这些信息;输出阶段则是通过撰写、演讲等方式验证并分享所学知识。作者还强调了费曼学习法的重要性,即通过教学来加深理解和发现知识盲点。
LLM微调优化 - QLoRA
引言
QLoRA(Quantized Low-Rank Adapter)是一种高效的微调方法,是 LoRA
的量化版本(什么是
LoRA?)。该调优方法由华盛顿大学发表于论文《QLORA: Efficient Finetuning of
Quantized LLMs》。通过降低内存使用,实现在单个 GPU
上对大型语言模型进行微调。它可以在单个 48GB GPU 上微调 650
亿个参数的模型,并且能够保持完整的 1 6 位微调任务性能。 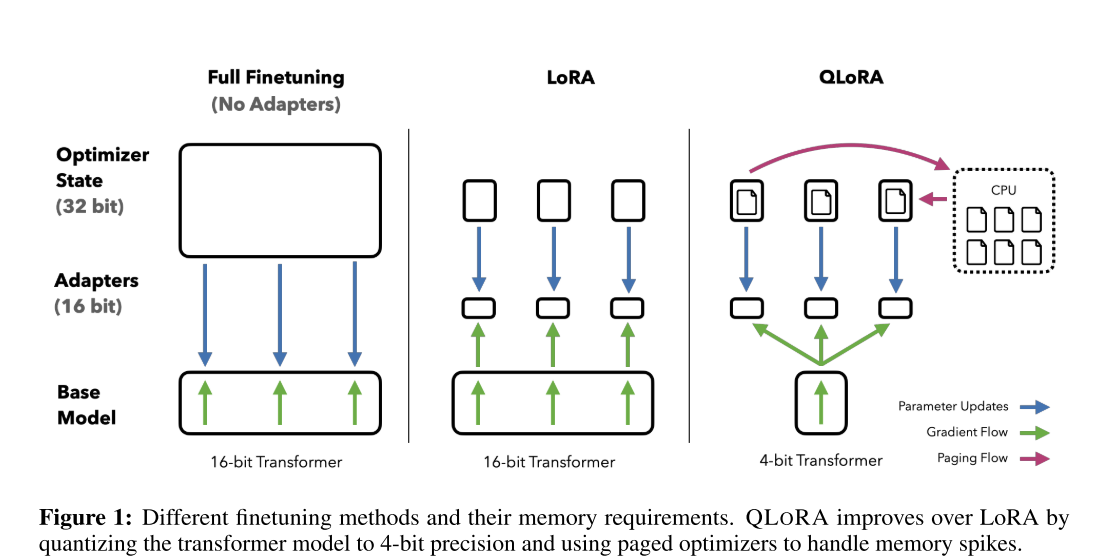
基础技术介绍
Block-wise k-bit Quantization
量化指的是将连续或高精度的数值转换为较低精度(比如较少的位数)的表示形式的过程。这通常用于减少模型的存储需求和加快其运算速度。例如,将一个 FP32 的 tensor 转成 Int8: \[X^{\text{Int8}} = \text{round}\left(\frac{127}{\text{absmax}(X^{\text{FP32}})} \cdot X^{\text{FP32}}\right)=round(c^{\text{FP32}})\] 其中,c 为量化常数。逆量化公式则为: \[\text{dequant}(c^{\text{FP32}}, X^{\text{Int8}}) = \frac{X^{\text{Int8}}}{c^{\text{FP32}}}\] 这种常规的量化方法的局限性也非常明显,当 tensor 中有一个非常大的数字(一般称为 outlier)时,将影响最终的量化结果。
因此,Block-wise k-bit Quantization 方法就是把 tensor 线性平展开,然后分割成 B 段,每段有自己的量化常数 c,独自量化。
Low-rank Adapters
LoRA,全称为“Low-Rank Adaptation”,尤其是在大型预训练语言模型(比如 GPT-3)的微调领域中。它是一种参数高效的模型微调技术,通过引入低秩的权重矩阵来修改预训练模型的自注意力机制。
在大型语言模型的背景下,LoRA 的关键优势是它能够在增加极少量参数的情况下,有效地适应新的任务或数据集。这一点尤其重要,因为全面重新训练这些大型模型需要大量的计算资源,而 LoRA 提供了一种更为节能的替代方案。
具体来说,LoRA 的工作原理是在自注意力模块的键(key)和值(value)矩阵中引入低秩矩阵。这些低秩矩阵与原始的键值对进行相乘,产生新的键值对,用于微调模型。因为这些矩阵的秩很低,所以新增加的参数数量较少,但这些参数的引入足以让模型学习到新任务的特定特征。
LoRA 的这种设计旨在保持预训练模型的大部分权重不变,同时仅对模型进行必要的小规模修改,从而快速适应新的任务。这样的方法在保持模型性能的同时,还能显著减少部署和运行大型模型所需的资源。

PEFT
PEFT(Parameter- Efficient Finetune)是一种在自然语言处理(NLP)中常用的方法,特别是在大型预训练语言模型的微调阶段。PEFT 方法的关键思想是,在保持大部分预训练模型参数固定不变的同时,只微调一小部分参数。这些参数可以是添加到模型的新参数,也可以是模型内部的一小部分可训练参数。这样做的好处是显著减少了微调过程中的内存和计算需求,同时仍然保持了模型的表现力。
核心技术
4 bit Normal Quantization
论文中提出的 4-bit NormlFLoat 量化是对 Quantile Quantization(分位量化)进行了改进,并结合上诉 Block-wise Quantization,降低计算复杂度和误差。
以 4-bit 量化为例,参数将被映射到 16 个可能的值(从 0 到 15)中的某一个,类似于四舍五入的方式。然而,这种传统量化方法的一个主要缺点是,量化后的参数分布可能与原始分布相差甚远。比如,如果有一个极大的值,那么大多数参数可能都会被量化到 0,从而导致模型性能显著下降。
为了解决这一问题,作者采用了分位量化(Quantile Quantization)方法。那么,分位量化是什么呢?仍然以 4-bit 量化为例,这意味着有 16 个不同的值可以选择。在分位量化中,首先将输入参数按大小排序(Quantile),然后将它们等分成 16 份(Block-Wise),每份对应一个量化值。这种方法在量化过程中能够更好地保持参数的原始分布,从而在降低参数精度的同时,尽可能减少对模型性能的影响。
上述分位量化会额外引入明显的计算开销,因为每次有参数输入进来都需要对齐进行排序并等分。
作者发现预训练的参数基本上都服从均值为 0 的正态分布,可以将其缩放到[-1,
1]的范围中。同时可以将正态分布 N(0,1)划分为 2^k+1 份,并缩放到[-1,
1]的范围中。这样就能直接将参数映射到对应的分位,不用每次都对参数进行排序。
但是这样做饭也会有一个缺点,参数 0 量化后可能不在 0
的位置上了,就没法表达 0
的特殊意义了。为此作者还做了一点改进,即分别将负数和整数部分划分为 2^k-1
份,参数 0 还是放在 0 原本的位置上。 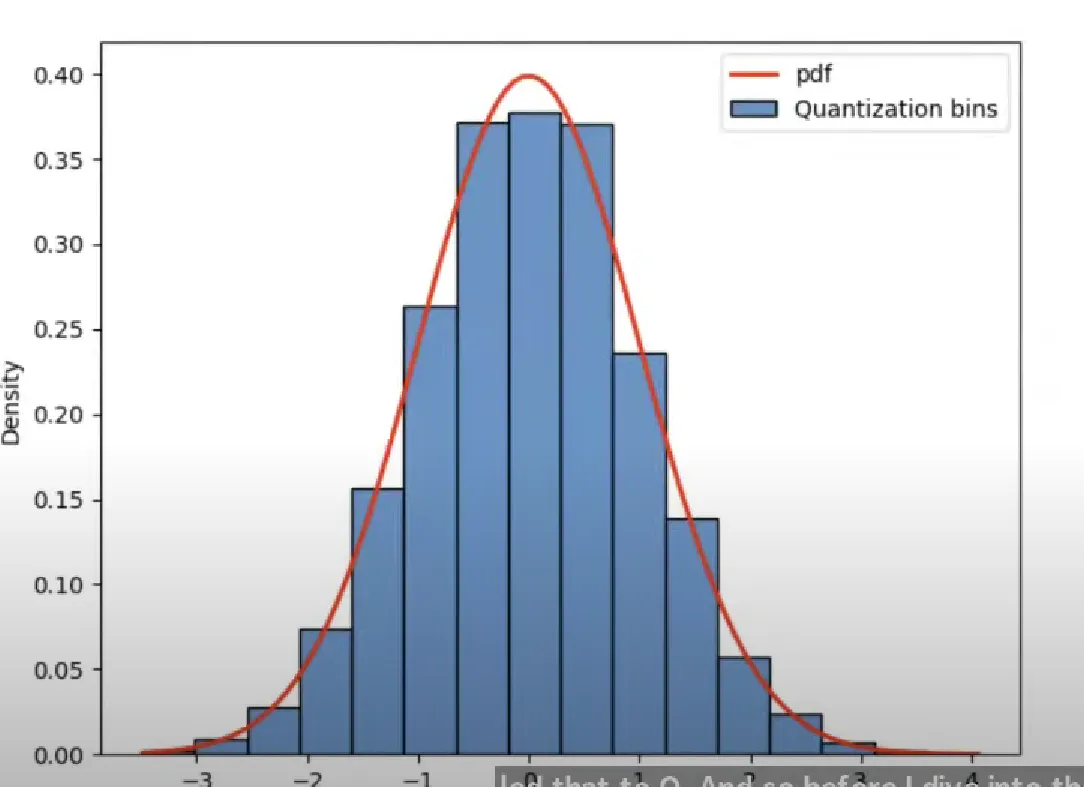
Double Quantization
分块量化中每个 block 都会额外产生一个量化常数 c。以量化 32bit
参数、block 大小 64 为例,每个 block 会引入 32bit
的量化常数,对应每个参数会额外引入 32/64=0.5bit 的额外开销。
论文采用了双重量化方法,如下图所示: 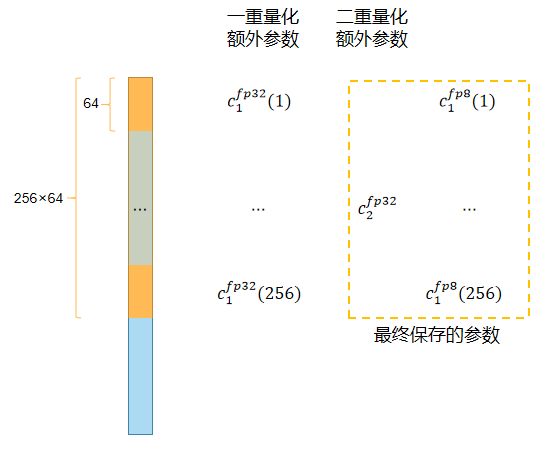 在第一次量化后,并不会直接储存量化常数 c1,而是按照 block 大小 256
对量化常数再量化到 8bit 上去储存,这个阶段会再引入一个量化常数
c2。最终保存的额外参数为 8/64 + 32/(64 ·
256)=0.127bits,也就是每个参数减少 0.5-0.127=0.373bits
在第一次量化后,并不会直接储存量化常数 c1,而是按照 block 大小 256
对量化常数再量化到 8bit 上去储存,这个阶段会再引入一个量化常数
c2。最终保存的额外参数为 8/64 + 32/(64 ·
256)=0.127bits,也就是每个参数减少 0.5-0.127=0.373bits
Paged Optimizers
Paged Optimizer 将优化器需要存储的数据(例如权重和梯度)分成多个小块或“页”。在每个训练步骤中,只加载当前需要的数据页到内存中,而不是一次性将所有数据加载进内存。这种方法允许在相对较小的内存中有效地处理大型模型,因为任何时候都只有部分数据被加载。
QLoRA 训练
所以 QLoRA 最终训练的表达为:
\[ Y^{\text{BF16}} = X^{\text{BF16}} \text{doubleDequant}\left(c_{1}^{\text{FP32}}, c_{2}^{\text{k-bit}}, W^{\text{NF4}}\right) + X^{\text{BF16}}{L_1}^{\text{BF16}}{L_2}^{\text{BF16}} \]
其中:
\[ \text{dequant}\left(c_1^{\text{FP32}},c_2^{\text{FP32}}, W^{\text{k-bit}}\right) = dequant(dequant(c_1^{FP32}, c_2^{k-bit}), W^{NF4})=W^{BF16} \]
参考资料
如何将微信读书导入Readwise
第一步:复制读书标注

第二步:将格式转换为 Readwise 导入格式
访问:https://notepal.randysoft.org/ 
我的GTD实践之路
经过8年的探索和尝试不同工具和方法,我终于总结出了一套适合自己的 GTD 实践方法,并在过去半年成功应用于日常生活。
【论文精读】A Berkeley View of Systems Challenges for AI
论文原文:Hidden Technical Debt in Machine Learning Systems
在文章的开篇,Google 工程师们就指出:虽然开发和部署机器学习系统相对快速并且成本低廉,但是持续的维护比较困难且成本高昂。这是由于:
首先,机器学习系统本质上也是一种软件系统,所以它具有其它软件系统中存在的技术债务。更复杂的是,机器学习系统又有很多机器学习相关的技术债务。而这些问题往往存在于系统级别 (system level),而不是代码级别 (code level)。
基于上面的判断,作者们给出了基于他们实践经验的技术债务总结。
复杂模型侵蚀边界 (Complex Models Erode Boundaries)
作者们指出的是:在传统的软件工程中,人们往往需要用封装、模块化等等手段来定义一些抽象边界,以达到改善软件系统的可维护性的目的。然而,在机器学习系统中,由于其依赖于大量的外部数据,这样的边界变得难以准确描述和定义了。
举个例子,如果一个机器学习系统中的模型使用了特征 x1, x2, ..., xn。当 x1 的分布情况变化时,原有模型的其他特征的权重也会发生改变,这就给系统的管理带来了很大的挑战。作者们把这种影响叫做 CACE 原则:
Changing Anything Changes Everything.
(改变任何一个就改变了所有)
这个问题称做 Entanglement,作者们给出了两个方案来改善这一问题:隔离模型和专注检测模型预测中的变化。
数据依赖比代码依赖成本更高(Data Dependencies Cost More than Code Dependencies)
在传统的软件工程中,人们往往可以借助于静态分析(Static Analysis)来发现和分析代码依赖关系。然而在机器学习系统中数据的依赖关系要更难以分析。
第一个问题就是数据的依赖关系可能很不稳定(Unstable data dependencies)。一个简单的例子就是一个机器学习系统可能把另一个系统的输出作为一个输入。然后,这种输入是不稳定的,并且变化是难以觉察的。作者们给出了一个可行的方案是对输入进行版本控制。
另一个问题就是不必要的数据依赖(Underutilized data dependencies),比如随着系统的变化不再需要的软件包。作者们建议用 leave-one-feature-out 的方法,来定期的检查和去除非必要的软件包。
由于数据依赖方面静态分析(Static analysis of data dependencies)工具的缺失,作者们也建议开发相应的工具来帮助分析数据依赖。
反馈循环(Feedback Loops)
对于在线学习系统而言,一个非常重要的特性就是模型需要持续更新。一种常见的实践是建立一个反馈循环,用于持续更新模型。
机器学习系统的反模式(ML-System Anti-Patterns)
在一个实际的机器学习系统中,仅仅一小部分代码是用于学习和预测的。随着时间的推移,一个机器学习系统中会出现各种各样系统设计中的反模式。
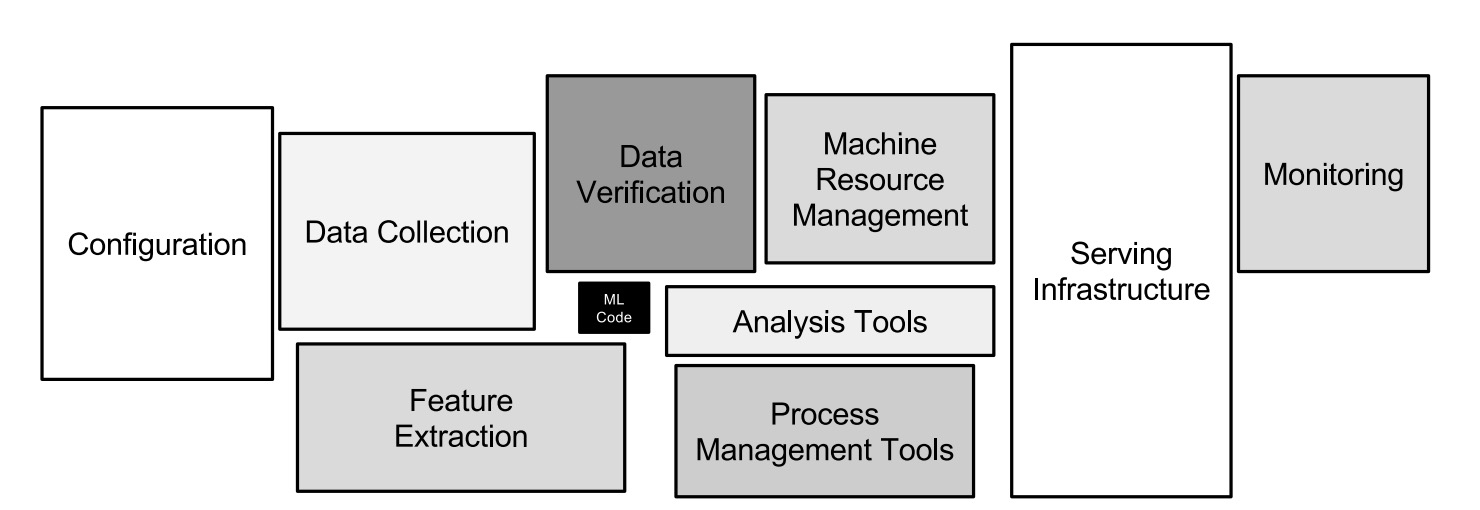
胶水代码(Glue Code)
作者们发现机器学习工程师们倾向于使用各种通用的机器学习库来编写代码,这就导致了系统中存在着大量的来自于庞大的通用机器学习库的代码。作者们的建议是把这些胶水代码用相同的 API 封装起来。
管道丛林(Piepline Jungles)
这里主要指的是数据准备(data preparation)阶段可能存在的问题。如果不加以注意,随着时间的推移,越来越多的输入信号加入到数据准备中,导致其变成一个混杂着各种爬虫、连接、取样等各种数据操作的丛林。有意思的是,作者们给出的解决方案是让工程师和科研工作者更多的合作,譬如在一个团队中,来帮助减少这种问题。
无用的实验代码路径(Dead Experimental Codepaths)
机器学习常常伴随着大量的试验,很容易导致在原有代码中产生各种条件分支。而后,随着条件分支越来越多,系统的技术债务也随之增加。作者们建议定期检查并删除这些无用的代码路径。
抽象债务(Abstraction Debt)
那么为什么会有这么多的技术债务问题呢?作者们的观点是我们目前还是缺乏用来描述机器学习系统的强抽象。无论是 MapReduce 还是 pramater-server 都达不到需要的抽象描述。
常见味道(Common Smells)
在软件工程中,有一个词语常常用来描述可能的代码结构问题,叫做坏的代码味道(bad code smell)。那么这里呢,作者们也列举了几个他们发现的可能的机器学习系统的坏的代码味道。
- 基础数据类型(Plain-Old-Data Type Smell)
- 多种语言(Multiple-Language Smell)
- 原型(Prototype Smell)
配置债务(Configuration Debt)
由于机器学习系统和算法的复杂性,一个大型的机器学习系统中常常存在着大量的配置,譬如使用哪些特征、数据如何选取、具体算法的参数设置、预处理的方式等等。作者们强调了配置的可维护性和易读性。譬如,配置也应该经过代码评审并提交到代码库中。
处理外部环境的变化(Dealing with Changes in the External World)
一个机器学习系统常常要和外部世界交互。然而,一个不容忽视的问题就是外部环境常常存在着各种变化。这无疑给机器学习系统的维护带来了极大的挑战。比如,一个机器学习系统应该如何监测呢?我们知道一个模型上线后,随着时间的推移以及新的数据的注入,常常会发生概念偏移(Concept drift),模型的准确率可能会有较大的变化。所以持续的监控和预警也就是非常必要的了。
【论文精读】A Berkeley View of Systems Challenges for AI
论文原文:A Berkeley View of Systems Challenges for AI
这又是篇不涉及过多技术的一篇论文,不过其中提到的 Challenges 确是目前 AI Systems 一直在努力解决的。
文中提到的几点关于 AI System 的 Challenge:
- Design AI systems that learn continually by interacting with a dynamic environment, while making decisions that are timely, robust, and secure.
- Design AI systems that enable personalized applica- tions and services yet do not compromise users’ privacy and security.
- Design AI systems that can train on datasets owned by different organizations without compromising their confidentiality, and in the process provide AI capabilities that span the boundaries of potentially competing organization.
- Develop domain-specific architectures and soſtware systems to address the performance needs offuture AI applications in the post-Moore’s Law era, including custom chips for AI work-loads, edge-cloud systems to efficiently process data at the edge, and techniques for abstracting and sampling data.
在论文中也提出了一些解决上述 Challenge 的研究方向: 