引言
Spark
作为一个基于内存的分布式计算引擎,其内存管理模块在整个系统中扮演着非常重要的角色。理解
Spark 内存管理的基本原理,有助于更好地开发 Spark
应用程序和进行性能调优。
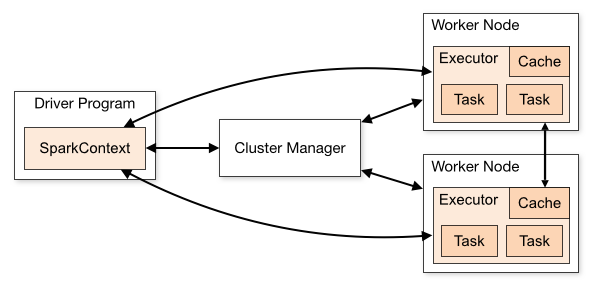
一个 Spark Application 一般包括 Driver 和 Executor 两种 JVM
进程。Driver 为主控进程,负责创建 Context,提交 Job,并将 Job 转换为
Task,协调 Executor 间的 Task 执行。而 Executor
主要负责执行具体的计算任务,将结果返回 Driver。 由于 Driver
的内存管理比较简单,和一般的 JVM 程序区别不大,所以本文重点分析 Executor
的内存管理。所以,本文提到的内存管理都是指 Executor 的内存管理。
堆内内存和堆外内存
Executor 作为一个 JVM 进程,它的内存管理是基于 JVM 之上的。所以 JVM
的内存管理包括两种方式:
- 堆内内存管理(On-Heap):对象分配的在 JVM
的堆上,对象会受 GC 束缚。
- 堆外内存管理(Off-Heap):对象通过序列化分配在 JVM
之外的内存里,由应用程序对其进行管理,且不受 GC
束缚。这种内存管理方式可以避免频繁的
GC,但缺点是必须自己编写内存申请和释放的逻辑。
一般来说对象读写速度是:on-heap > off-heap > disk
内存空间分配
在 Spark 中,支持两种内存管理方式:静态内存管理(Static Memory
Manager)和统一内存管理(Unified Memory Manager)。
Spark 为 Storage 内存和 Execution 内存的管理提供了统一的接口MemoryManager,同一个
Executor 内的任务都调用这个接口的方法来申请或释放内存。MemoryManager
的实现上,Spark 1.6
以前默认采用的是静态内存管理([StaticMemoryManager]((https://github.com/apache/spark/blob/branch-2.3/core/src/main/scala/org/apache/spark/memory/StaticMemoryManager.scala))的方式;而在Spark1.6以后,默认采用的是统一内存管理(UnifiedMemoryManager)的方式。在中Spark
1.6+中,可以通过 spark.memory.useLegacyMode 参数启用静态内存管理。
静态内存管理(Static Memory
Manager)
静态内存管理机制下,Storage 内存、Execution 内存和其他内存的大小在
Spark
应用程序运行期间均为固定的,但用户可以应用程序启动前进行配置。由于这种分配已经逐渐被淘汰,但出于兼容性考虑,Spark
依然保留下来。有兴趣的话,可以参考:https://blog.csdn.net/Lin_wj1995/article/details/79924542
这边主要讲下静态内存管理的弊端:静态内存管理机制实现起来较为简单,但如果用户不熟悉
Spark
的存储机制,或没有根据具体的数据规模和计算任务或做相应的配置,很容易造成
Storage 内存和 Execution
内存中的一方剩余大量的空间,而另一方却早早被占满,不得不淘汰或移出旧的内容以存储新的内容。
统一内存管理(Unified Memory
Manager)
Spark 1.6
之后引入了统一内存管理机制,该机制与静态内存管理的区别在于,Storage
内存和 Execution
内存是共享一块内存空间的,双方可以互相占用对方的空闲区域。
堆内模型
默认情况下,Spark 仅使用了堆内内存。堆内内存的大小由 Spark
Application 启动时的--executor-memory 或 spark.executor.memory
参数配置。Executor 内运行的并发任务共享 JVM 堆内内存。
Executor 端的堆内内存区域大致可以分为以下四大块:
- Storage 内存(Storage Memory):主要用于存储 Spark 的 cache
数据,例如 RDD 的缓存、Broadcast 变量,Unroll 数据等。
- Execution 内存(Execution Memory):主要用于存放
Shuffle、Join、Sort、Aggregation 等计算过程中的临时数据。
- 用户内存(User Memory):主要用于存储 RDD 转换操作所需要的数据,例如
RDD 依赖等信息。
- 预留内存(Reserved Memory):系统预留内存,会用来存储 Spark
内部对象。
内存分布如下图所示: 
堆外模型
Spark 1.6 开始引入了 Off-heap memory(SPARK-11389)。默认情况下,堆外内存是关闭的,我们可以通过
spark.memory.offHeap.enabled 参数启用,通过 spark.memory.offHeap.size
设置堆外内存大小。相比堆内内存,堆外内存的模型比较简单,只包括 Storage
内存和 Execution 内存,其分布如下图所示: 
如果堆外内存被启用,那么 Executor
内将同时存在堆内和堆外内存,两者的使用互补影响,这个时候 Executor 中的
Execution 内存是堆内的 Execution 内存和堆外的 Execution
内存之和,同理,Storage 内存也一样。下图为 Spark 堆内和堆外示意图 
动态占用机制
- 在程序提交时,会根据 spark.memory.storageFraction 参数设置 Storage
内存区域和 Execution 内存区域。
- 在程序运行时,如果双方的空间不不足(存储空间不足以放下一个完整的
Block),则按照 LRU
规则存储到磁盘;如果己方空间不足而对方空间有空余,则借用对方的空间。
- Storage
占用对方内存,可将占用的部分转存到硬盘,然后"归还"借用的空间。
- Execution 占用对方内存,目前的实现是无法让对方"归还"的。因为 Shuffle
过程产生的文件在后面一定会被使用到,而 Cache
在内存的数据不一定在后面使用,归还内存可能会导致性能严重下降。
参考资料

 %201.png)
%201.png)