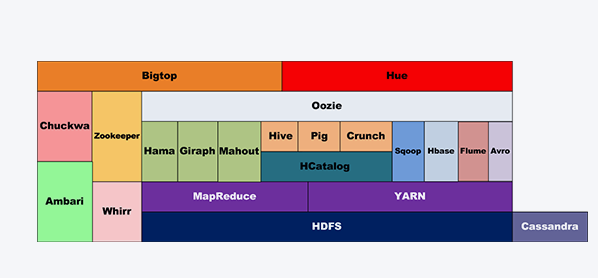
2013 年 10 月 15 日,Apache Hadoop 发布了 2.2.0 版本。这个是里程碑式的版本,它是 Hadoop 2.0 的第一个 stable 版本,它标志着 Hadoop 从此进入了 2.0 时代。
- YARN
YARN(Yet Another Resource Negotiator),也称 MapReduce 2.0,它是 Hadoop 2.0 引入的一个全新的通用资源管理系统,可以在其上运行各种程序和框架。YARN 是从 MapReduce 1.0 衍化来的。引入了 ResourceManager、ApplicationMaster 和 NodeManager 等组件用于系统的资源调度。
- HDFS High Availability
Hadoop HA 同时解决了 NameNode 单点故障问题和内存受限问题。主要利用 Active NameNode 和 Standby NameNode 之间的状态切换解决单节点故障问题。而其中采用 NFS、QJM 和 Bookeeper 三种可选策略用于 NameNode 之间的 Metadata 共享。
- HDFS Federation
HDFS Federation,它允许一个 HDFS 集群中存在多个 NameNode,每个 NameNode 分管一部分目录,而不同 NameNode 之间彼此独立,共享所有 DataNode 的存储资源,由于 NameNode Federation 中的每个 NameNode 仍存在单点问题,需为每个 NameNode 提供一个 backup 以解决单点故障问题。
- HDFS Snapshots
HDFS Snapshots,是 HDFS 在某一时刻的只读镜像。它可以是整个文件系统也可以是一部分文件夹。通常用于数据备份,防止数据丢失或者误操作。
- NFSv3
将 NFS 引入 HDFS 后,用户可像读写本地文件一样读写 HDFS 上的文件,大大简化了 HDFS 使用。
- 支持 Windows 平台
在 2.2.0 版本之前,Hadoop 仅支持 Linux 操作系统,而 Windows 仅作为实验平台使用。将 Microsoft 有关 Hadoop Windows Patch 吸收进代码之后,Hadoop 对 Windows 的支持有了本质上的增强。其实之前 Hortonworks 的 HDP 的也曾发布支持 Windows 的 Hadoop。
- 兼容 Hadoop 1.x 的 MapReduce 程序
为了使 MRv1 可以在 YARN 架构上运行,对 MR API 进行了修改保证可以在 YARN 上运行。
- 完成与 Hadoop 生态圈的其他软件的集成测试
相比 Hadoop 1.0 中,Hadoop 2.0 对 HDFS 和 MapReduce 等核心组件进行了较大的改动,并引入了全新的资源调度框架 YARN。因此对那些以 Hadoop 作为底层的应用进行集成测试是十分必要的。
参考资料:
Apache Hadoop 2.2.0: http://hadoop.apache.org/docs/r2.2.0/
Hadoop 2.0 稳定版本 2.2.0 新特性剖析: http://dongxicheng.org/mapreduce-nextgen/hadoop-2-2-0/
HDFS Snapshots: http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsSnapshots.html
Hadoop For Windows: http://dongxicheng.org/mapreduce/hadoop-for-windows/