本文内容主要来源于 Rockset 公开的《Rockset Hybrid Search Architecture》技术白皮书,同时加入了互联网资料和个人理解整理而成。如与实际情况有偏差,欢迎批评指正。
概述
Rockset 是一家专注于实时分析和搜索的数据管理和分析公司。成立于 2016 年,总部位于美国加利福尼亚州旧金山。Rockset 的主要产品是一个实时分析平台,帮助企业和开发者快速从不同数据源中提取、转化和加载(ETL)数据,并进行实时查询和分析。这个平台支持多种数据源,如数据库、数据流、云存储等,用户可以通过标准的 SQL 查询进行数据分析。Rockset 于 2024 年 6 月 21 日被 OpenAI 收购。
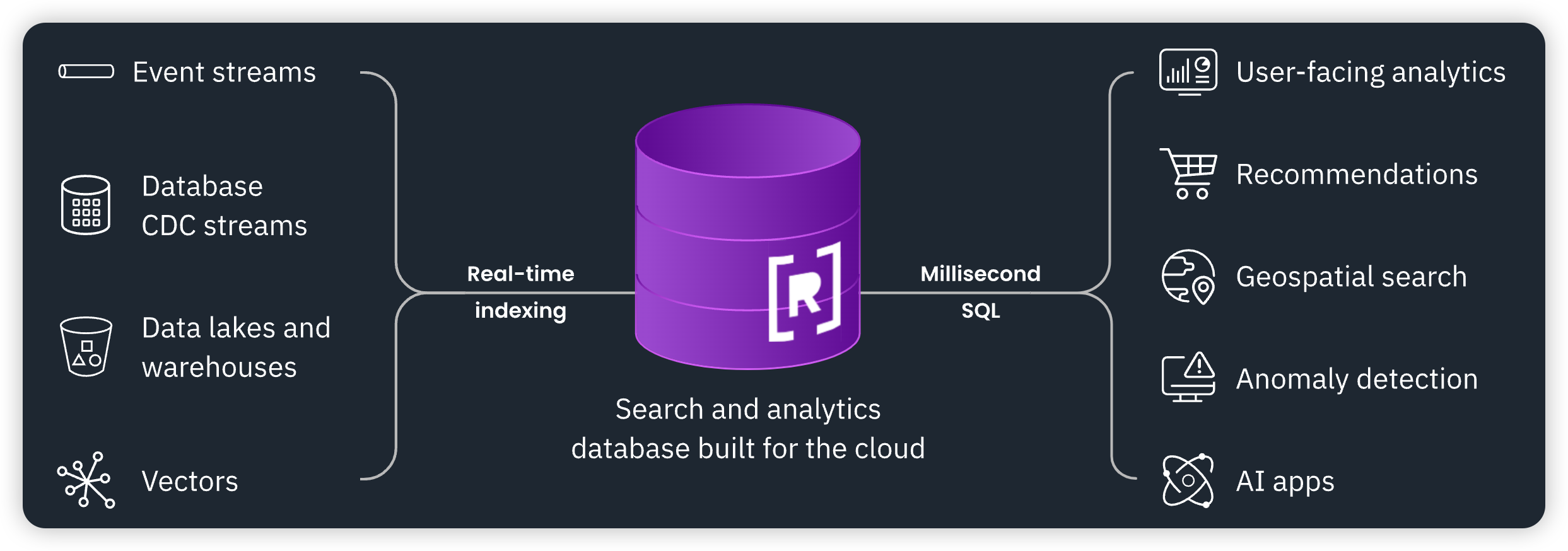
从 Rockset 的 slogan:
Index your vector, text, geospatial and JSON data for the most efficient hybrid search and real-time analytics at any scale
可以看出其产品的三个关键词:
- Hybrid Search:混合检索
- Real-Time Analytics:实时分析
- Cloud:云原生
本文将从这三个关键词入手,介绍 Rockset 的整体技术架构。
Hybrid Search (混合检索)
Rockset 在白皮书中指出:未来向量检索将变成混合搜索(Hybrid Search)。
- 领域意识的限制:通用模型在特定领域的术语识别上存在不足,而文本搜索在找到特定术语上更有效。混合搜索结合了向量检索和文本检索的优势,能够更好地处理领域特定的查询。
- 过滤能力:相似度搜索主要用于查找上下文相似的项目,但对于需要精确过滤的应用,如查找特定评级和距离内的餐馆,文本和元数据过滤更为适合。混合搜索可以结合这些过滤条件提供更精确的结果。
- 参考性:虽然自然语言生成模型(如 LLM)可以提供信息和总结,但用户通常需要验证结果或深入研究源材料。混合搜索可以结合参考材料,提高信息的可信度。
- 幻觉现象:LLM 容易产生错误信息(幻觉),将搜索结果与上下文信息结合可以提高准确性。
- 权限管理:企业使用权限管理确保数据隐私和安全。混合搜索可以结合权限设置,确保模型只能访问用户有权限的数据。
在 Rockset 的 Hybrid Search
架构中,核心环节有三个:索引(Indexing)、查询(Retrieval)和排序(Ranking)。
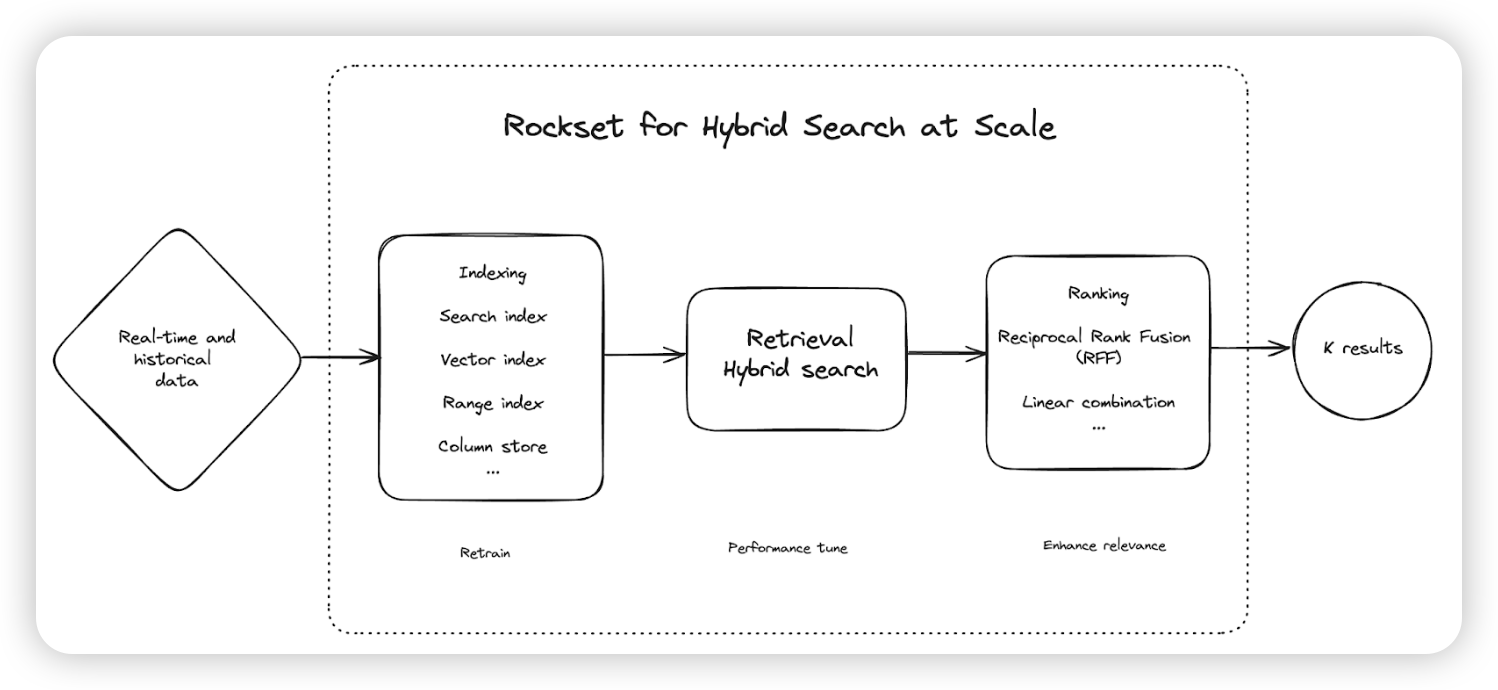
融合索引(Converged Index)
Rockset 的索引称为融合索引(Converged Index),在键值存储抽象层(后续会介绍)之上应用了向量索引、搜索索引、列式存储和行式存储的元素。Rockset 使用基于 CBO(Cost-Based Optimizer)来并行利用多个索引,以实现最有效的查询执行。融合索引是 Rockset 最核心的技术之一。
列存索引(Column Index)
像大部分 OLAP 数据库一样,Column Index 的设计是为了优化分析查询和数据压缩,具体作用如下:
- 优化分析查询:Column Store 将所有列的数据连续存储在一起,使得查询可以高效地只读取需要的列数据。这在处理涉及多列的大型数据集的分析查询时特别有用,因为它减少了不必要的数据读取,提高了查询性能。
- 更好的压缩率:因为列中的值通常彼此相似,Column Store 在存储相似值时能够实现更好的压缩效果。它可以使用高级的压缩技术,比如字典压缩和运行长度编码(Run-Length Encoding),进一步提高压缩效率和数据存储的有效性。
行存索引(Row Index)
Row Index 是为了优化行查找和事务处理,具体作用如下:
- 优化行查找:Row Store 按行存储数据,使得在处理涉及单行数据的查找操作时非常高效。这对于需要快速读取和更新单行记录的事务处理场景特别有用。
- 标准数据库组织方式:Row Store 是数据库的标准组织方式,如 PostgreSQL 和 MySQL 即采用这种方式。这种存储方式适合需要频繁读取和写入整行数据的应用。
搜索索引(Search Indexing)
Search Index 的使用场景类似 Elastic Search 或 Apache Solr。倒排表(Posting lists)是现在搜索型数据库的基础。为了优化空间和存取效率,Rockset 使用 Roaring bitmaps 来保存倒排表。
下面是使用 Roaring Bitmaps 来检索倒排表中的交集或并集: 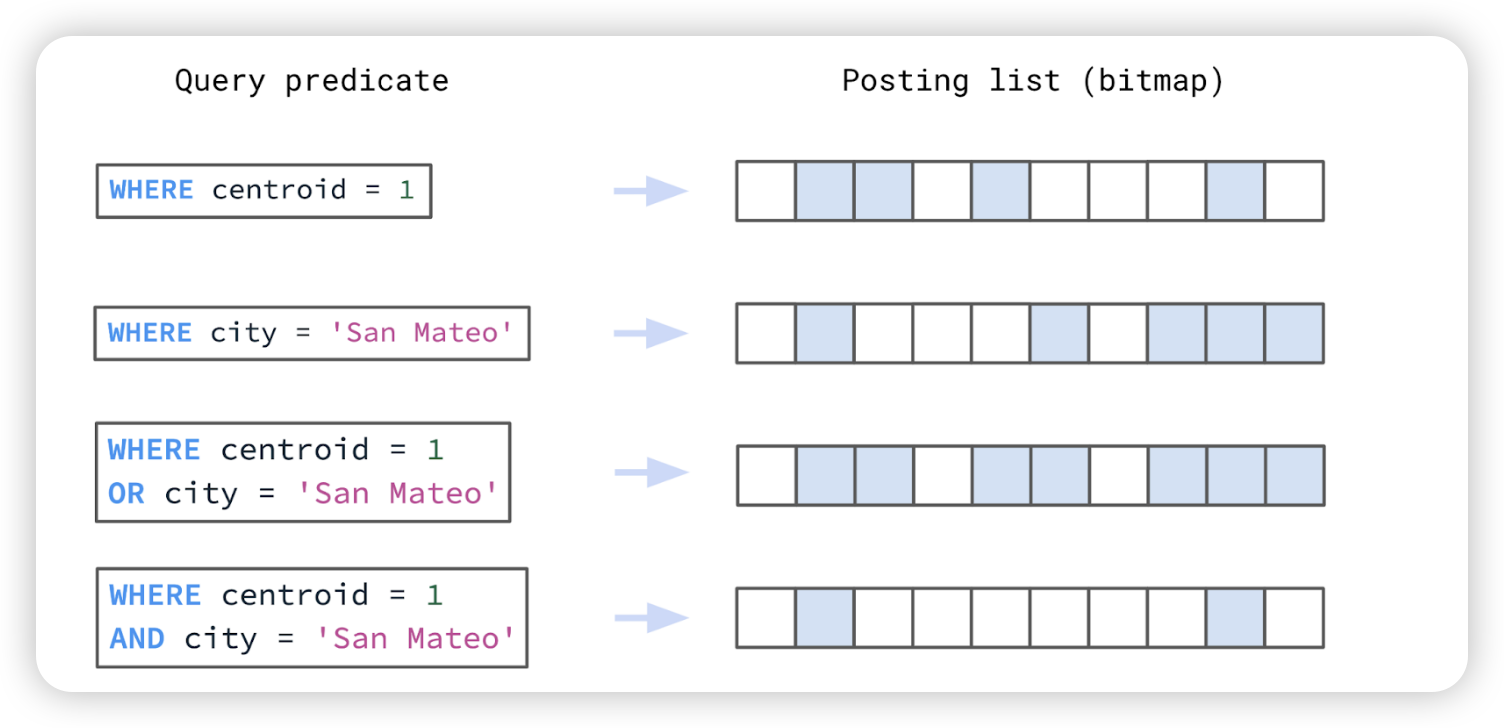 Roaring Bitmaps
并不是一个冷门的数据结构,目前相当多的数据系统都采用了这种带压缩因子的
bitmap。
Roaring Bitmaps
并不是一个冷门的数据结构,目前相当多的数据系统都采用了这种带压缩因子的
bitmap。 
向量索引(Vector Index)
Rockset 将索引和原始的文本、JSON、GEO 和时序数据放在同一个Collection中,并可以对其中的向量字段建立向量索引。
Rockset 的向量索引利用了FAISS-IVF。FAISS
是 Meta 开源的向量索引库,而 IVF(Inverted File
Index)是其倒排文件索引实现。FAISS-IVF 使用 cell-probe
索引将向量空间划分为 Voronoi
Cell,每个单元由一个质心(Centroid)表示,质心是分区的中心点。关于质心的计算,Rockset
会抽样一部分数据,划分 Cell
并计算质心,后续所有注入的每个向量都会属于某一个 Cell。 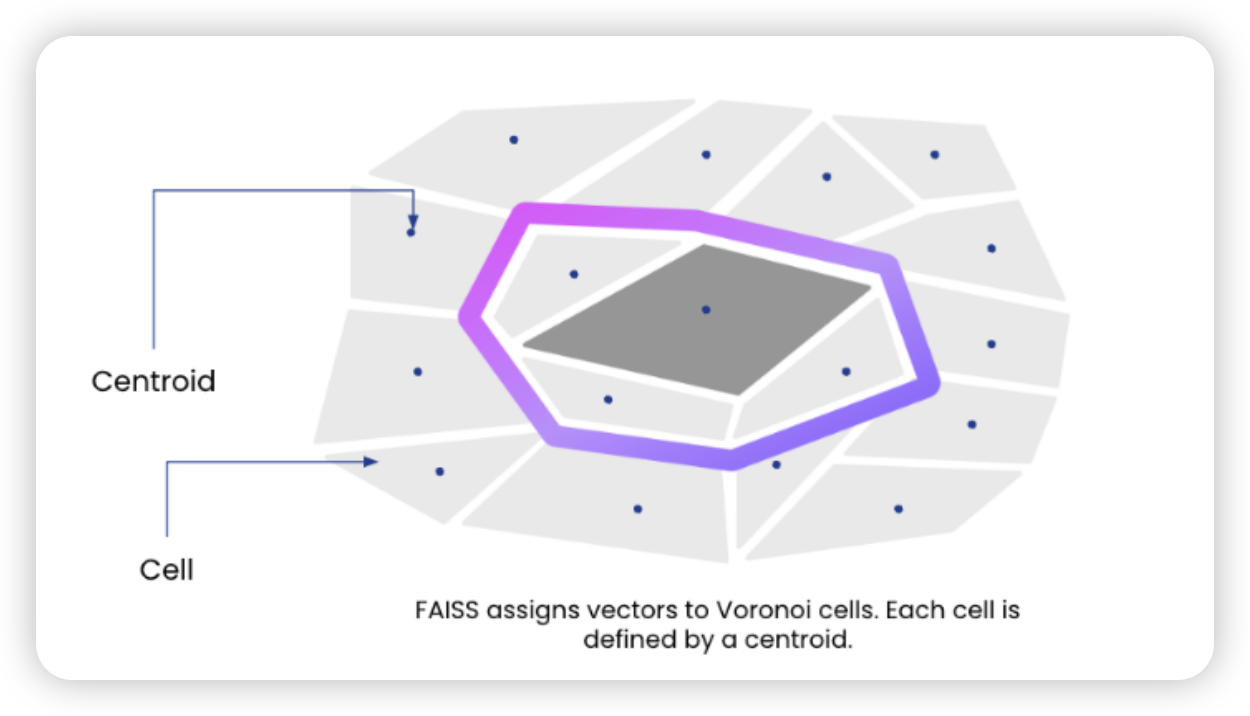
Rockset 创建了一个质心向量的倒排表(posting
list),该列表存储在内存中。Collection
中的每个记录还包含质心(Centroid)和残差(Residual)的隐藏字段,用于加速搜索。
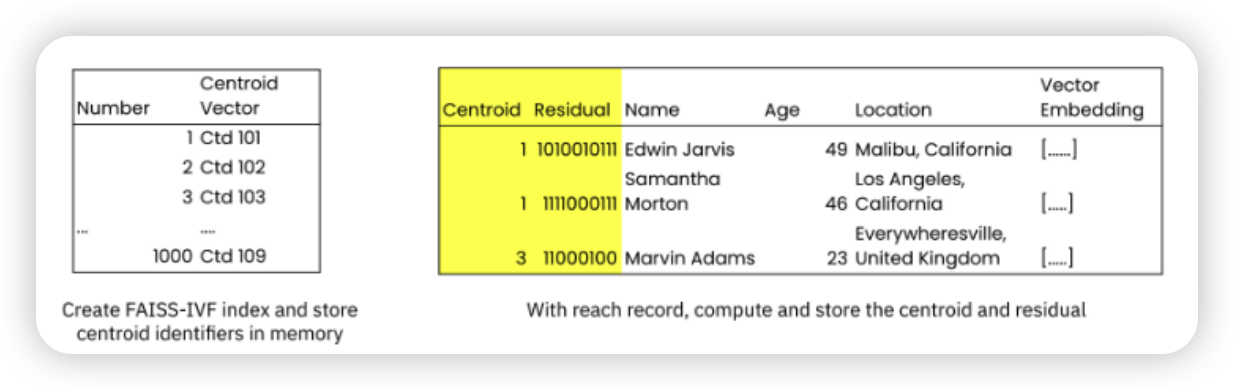 可以看出 FAISS-IVF
索引融入到整体设计的一部分。选用 FAISS-IVF 主要是因为 FAISS-IVF
索引构建速度快,虽然查询效率中等。
可以看出 FAISS-IVF
索引融入到整体设计的一部分。选用 FAISS-IVF 主要是因为 FAISS-IVF
索引构建速度快,虽然查询效率中等。  基于 FAISS-IVF
的特性,Rockset 对 Centroid 也做了倒排索引作为 Columnar Index
的一个字段,这样就可以利用列存储查询效率的优势(这个设计真的太巧妙了!)。
基于 FAISS-IVF
的特性,Rockset 对 Centroid 也做了倒排索引作为 Columnar Index
的一个字段,这样就可以利用列存储查询效率的优势(这个设计真的太巧妙了!)。
 Rockset
对其向量索引进行分片,在查询时,从每个分片检索前 K
个结果,然后聚合这些结果以生成最终的搜索结果。
Rockset
对其向量索引进行分片,在查询时,从每个分片检索前 K
个结果,然后聚合这些结果以生成最终的搜索结果。
附加的其他索引
BM25
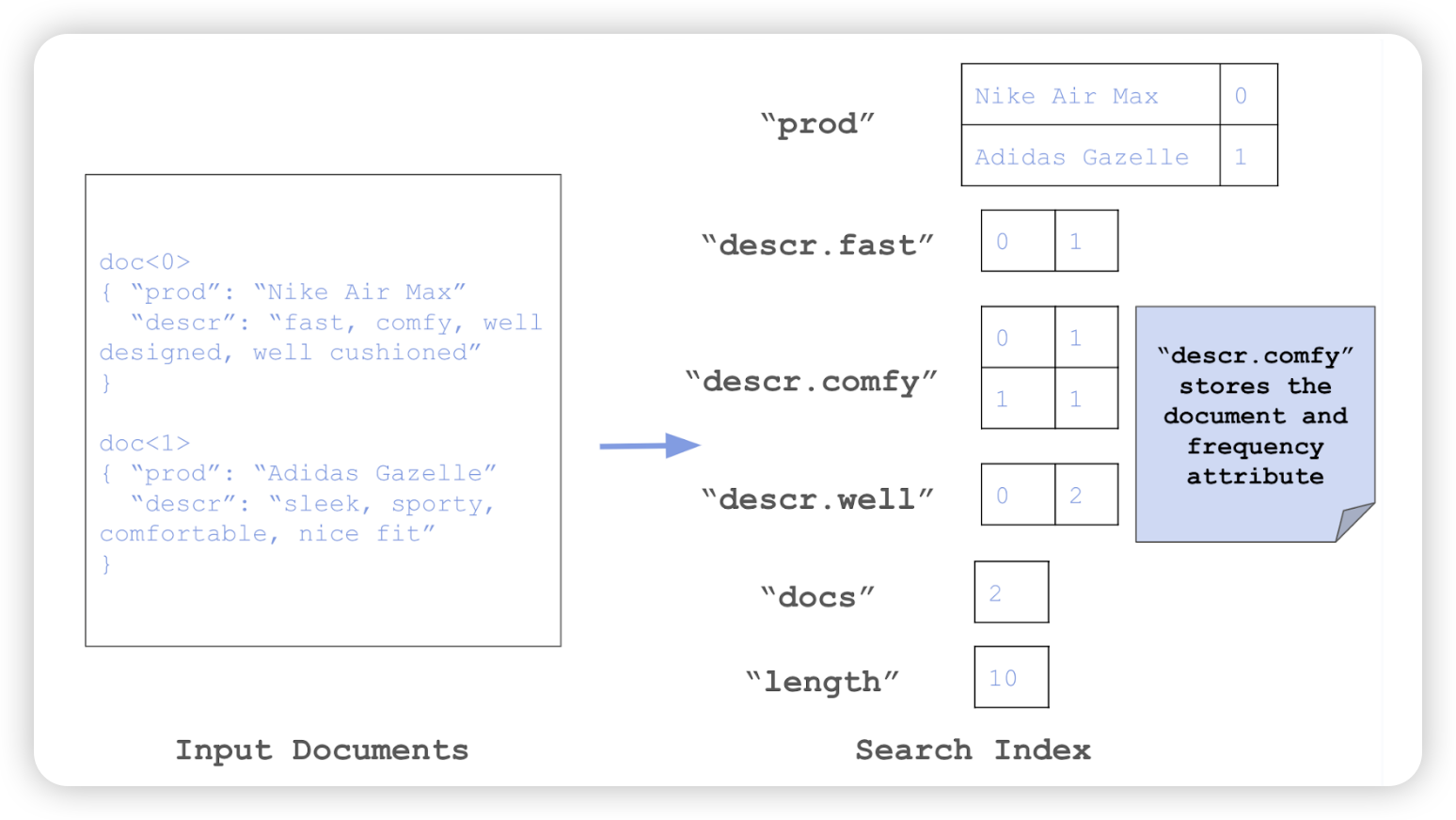
BM25 是一种用于估计文档相对于搜索查询词的相关性的排序函数。它使用词袋模型,根据每个文档中出现的查询词来对文档进行排名,而不考虑词的接近度。Rockset 搜索索引允许在索引过程中将已知属性存储在索引中。索引设计细节:
- 词频存储:在索引过程中,Rockset 计算并存储每个文档中的词频,这些词频作为已知属性存储在搜索索引中。
- 集合级元数据:Rockset 在集合级别跟踪文档总数和文档总长度的运行和,以便轻松计算平均文档长度。
- 计算 BM25 分数:利用存储的词频和集合级元数据,Rockset 可以在查询时快速计算每个文档的 BM25 分数。
GEO 索引
典型的地理空间查询通常不是搜索一个精确的点,而是搜索某个紧凑区域内的点,例如在给定距离内或多边形内的所有点。为了满足这种需求,Rockset 重新设计了搜索索引以适应地理空间查询。
地球表面的网格划分:Rockset 使用 S2 库将地球表面划分成层次化的方形网格单元。对于集合中的每个点,Rockset 在搜索索引中为包含该点的每个单元添加一个条目。由于这些单元形成了一个层次结构,一个点被包含在许多单元中——其直接父单元以及所有祖先单元中。这种方法增加了空间使用量,但显著提高了查询性能。
层次化网格单元:S2 库将地球表面划分为多个层次的方形网格单元,每个点都属于多个单元,包括其直接单元和所有上层单元。通过这种方式,一个点在多个层次单元中都有条目,提高了查询效率。
融合索引(Converged Index)
上面介绍的各种索引又是如何融合到一起的呢?在底层,Rockset
使用RocksDB作为其存储层,所有的索引数据都是以 KV
的形式存储的。例如:  Vector Search 其实是在
Rockset 系统设计完成之后引入的,可以理解为原有 Index
的一个扩展,但却毫无违和感(残差如何保存和使用还有待进一步解释)。
Vector Search 其实是在
Rockset 系统设计完成之后引入的,可以理解为原有 Index
的一个扩展,但却毫无违和感(残差如何保存和使用还有待进一步解释)。 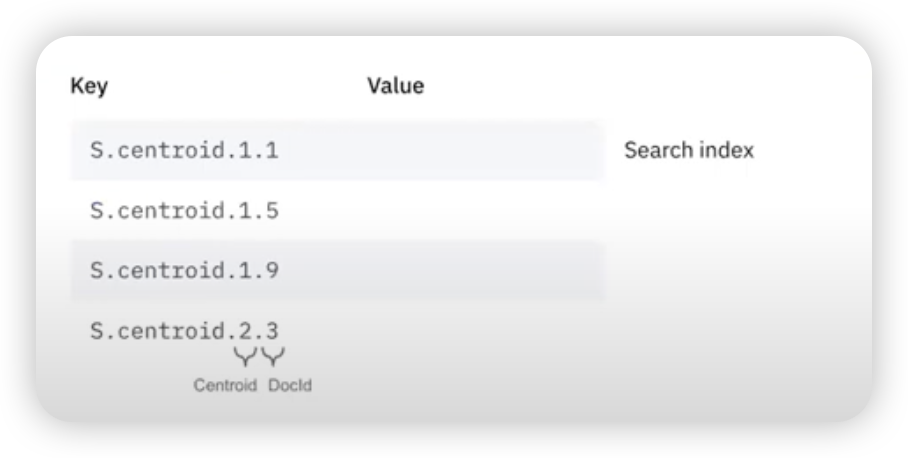
混合检索(Hybrid Search)
Vector Search + Text Search
向量搜索用于查找相似项,但可能会遗漏相关关键词。因此,许多应用程序使用混合方法,将向量搜索和文本搜索结合起来,以提高结果的相关性。
Rockset 支持混合向量和文本搜索,通过 BM25 评分模型基于查询词的频率和分布对文档进行评分,提供文本相关性测量。
使用 APPROX_DOT_PRODUCT 计算向量相似度,两者的输出可以通过线性组合进行结合,创建混合评分。
SELECT |
这个查询将通过向量相似度和文本相关性来排序结果,alpha 参数用于调整二者的权重。
Vector Search + Metadata Filtering
支持精确最近邻(KNN)和近似最近邻(ANN)搜索。
嵌入间的距离可以使用内置距离函数(如 EUCLIDEAN_DIST、DOT_PRODUCT、COSINE_SIM)计算。
SQL 中使用 ORDER BY similarity DESC 子句按相似度度量进行排序,并使用 LIMIT k 子句限制输出结果的数量。元数据过滤通过 WHERE 子句实现特定约束。
SELECT |
这个查询将查找符合定义的用户配置文件和地理位置的相似推文。
Vector Search + Geo Search
向量搜索可以通过地理过滤或地理排名进行增强。
Rockset 内置的地理函数(如 ST_DISTANCE、ST_CONTAINS 和 ST_INTERSECTS)可用于地理搜索。
SQL 中在 WHERE 子句中集成地理函数,以基于地理接近或包含来细化搜索。
SELECT |
这个查询将识别在指定地理位置范围内的相似推文。
搜索排序(Ranking)
递归排名融合(Reciprocal Rank Fusion,RRF)
递归排名融合是一种有效的方法,用于结合来自多种搜索模式(例如向量搜索、文本搜索和地理搜索)的文档排名。RRF 根据一个经过验证的评分公式(原文中并没有公开)对文档进行排序,减少了在不同搜索模式之间对分数进行归一化的需求。Rockset 实现了一个 SQL 函数用于执行 RRF。
RANK_FUSION( |
RANK_FUSION 函数在查询执行过程的最后阶段在内存中执行。
线性组合排名(Linear Combination)
线性组合通过将不同搜索模式的输出分数进行加权求和来提供排名机制。用户可以通过调整系数来微调每种模式的影响力,从而实现灵活和可定制的排名系统。线性组合通常用于跨搜索模式结合分数,输出归一化分数。
(:alpha * score1) + ((1-:alpha) * score2) |
实时分析
索引实时更新
Rockset 支持向量和元数据的实时更新,具体实现方法如下:
- 字段级别的可变性:Rockset 是可变的,可以在单个字段级别进行更新。因此,当单条记录中的向量发生更新时,系统会指示 FAISS-IVF 生成新的质心和残差。此操作只会重新索引更新的向量字段,而不会重新索引整个文档,从而使这一操作能够在 200 毫秒以内完成。
- 逻辑搜索索引和物理表示的分离:为了支持实时更新,Rockset 的聚合索引将逻辑搜索索引与其作为键值存储的物理表示分离。这在搜索数据库设计中是独特的。每个键都引用一个文档片段,这意味着用户可以更新文档中的单个向量或元数据字段,而不会触发整个文档的重新索引。

云原生架构
RocksDB-Cloud
RocksDB 是 Meta 开源的 KV 存储,为了支持云原生和分布式的特性,Rockset 公司 Fork 了一个版本称为rocksdb-cloud并开源(Rockset CTO Dhruba 之前在 Facebook 是 RocksDB 的初始工程师)。
RocksDB-Cloud 在云环境中提供了三个主要优势:
- RocksDB 实例具有持久性。数据库数据和元数据会持续且自动地复制到 S3 上。如果 RocksDB 机器发生故障,任何其他 EC2 机器上的进程都可以通过配置 S3 存储桶名称重新打开相同的 RocksDB 数据库(该存储桶保存了整个数据库的状态)。
- RocksDB 实例是可克隆的。RocksDB-Cloud 支持一种称为 zero-copy-clone()的原语,它允许另一台机器上的 RocksDB 从现有数据库克隆出一个从属实例。主实例和从属实例可以并行运行,并共享一些共同的数据库文件。
- RocksDB 实例可以利用分层存储。整个 RocksDB 的存储占用不需要全部驻留在本地存储上。S3 包含了整个数据库,而本地存储仅包含工作集中所需的文件。
计算与存储分离
架构设计
Rockset 的架构将计算资源和存储资源分离。计算资源主要是虚拟实例(VIs)(类似 Snowflake 的设计),用于数据摄取、转换和查询。存储资源通过存储节点管理,提供热数据层。这种分离允许计算和存储资源独立扩展,提高了系统的灵活性和可扩展性。
数据持久性和热存储层
Rockset 使用 RocksDB-Cloud 库将数据持久化到 Amazon S3,并在附加 SSD 上保存一份热数据副本。数据写入时,首先写入内存表(memtable),然后被转化为不可变的 SST 文件,这些文件被压缩并存储在 S3 中。热存储层确保了高性能查询,通过从 S3 中下载必要的 SST 文件来响应查询请求。
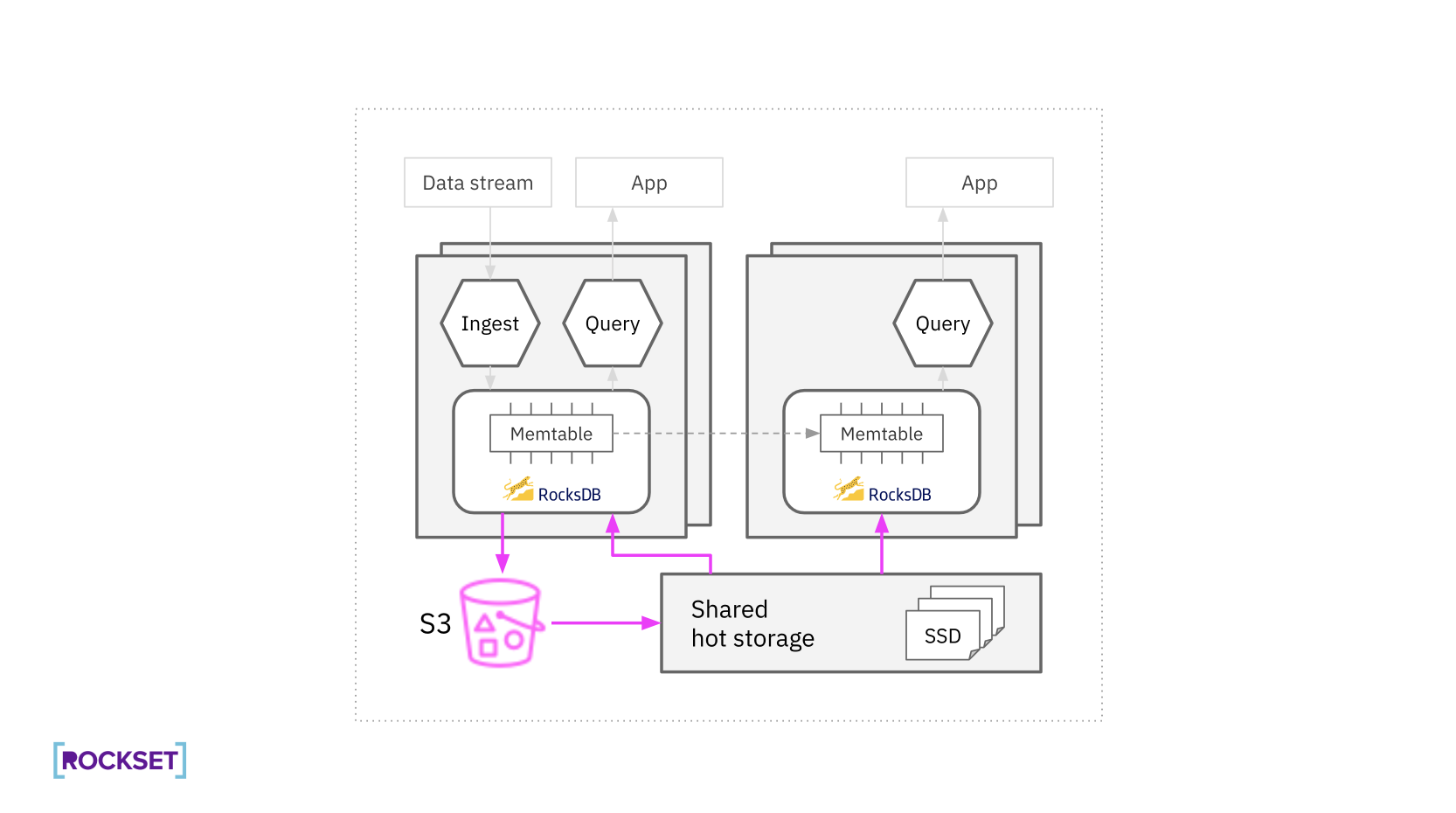
数据分配和查询
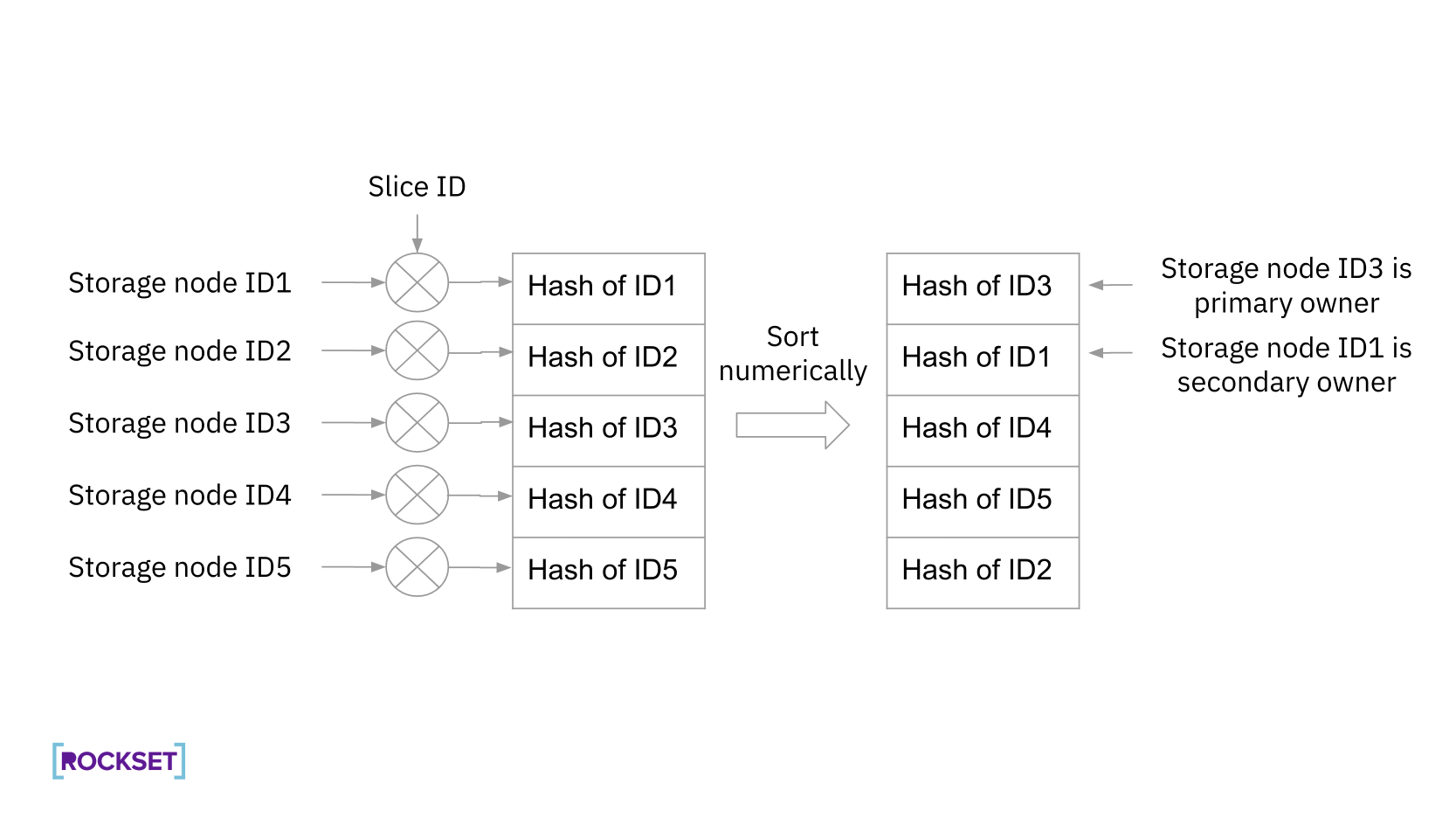
Rockset 使用 Rendezvous 哈希算法将数据片段分配到存储节点。计算节点只请求所需的数据块,这减少了网络调用的延迟。通过预取和并行技术,进一步提高了数据检索效率。在数据查询过程中,系统能够高效地在计算节点之间分配和检索数据。
缓存机制
计算节点采用内存缓存和 SSD 持久缓存,支持较大的工作集,减少对网络和 S3 的依赖。内存缓存用于存储最近使用的数据,而 SSD 持久缓存用于存储较大和较长时间的数据集合。这种双层缓存机制确保了高查询性能,满足不同工作负载的需求。
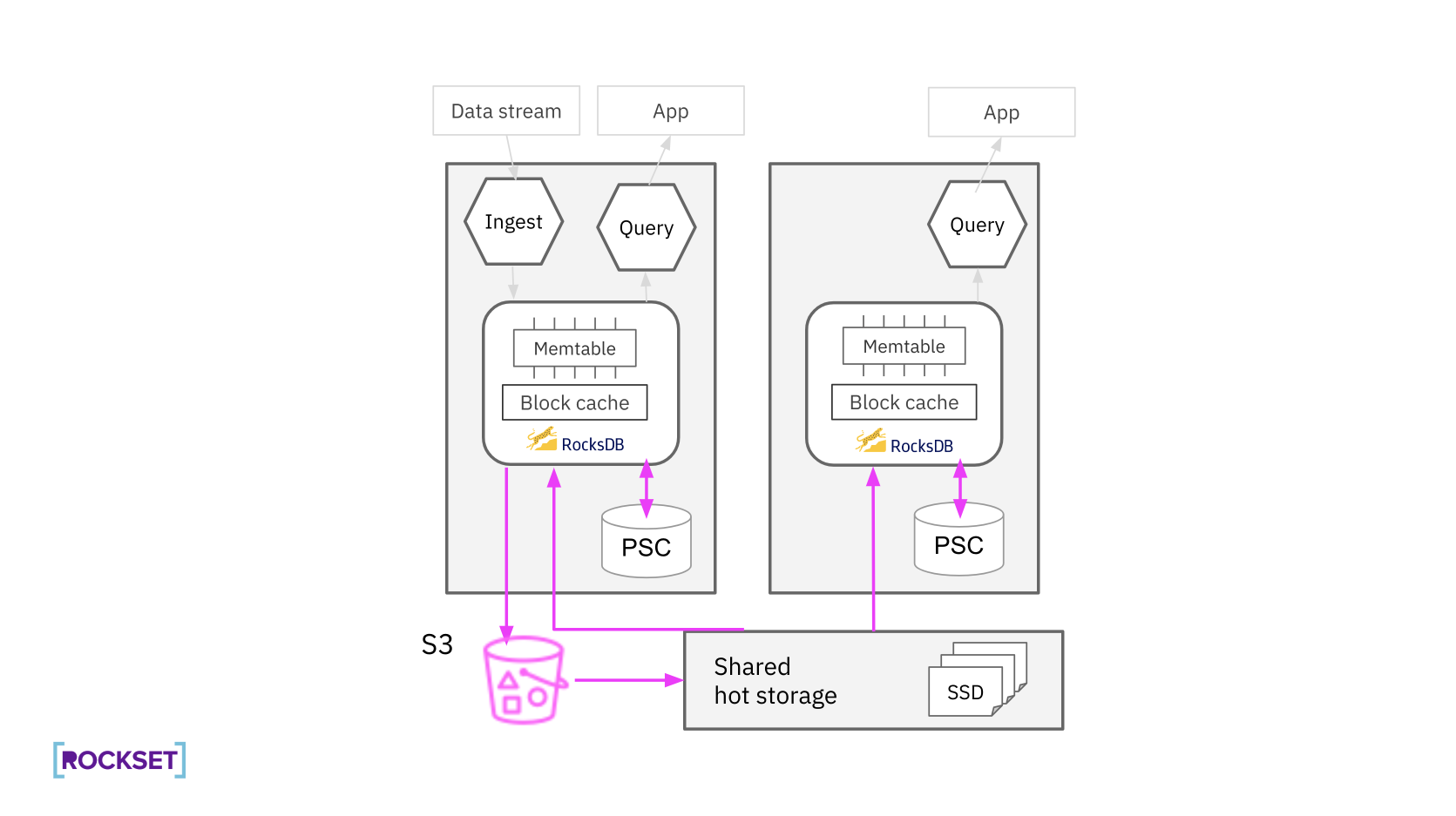
副本管理和可靠性
热存储层维护数据的主要副本和部分次要副本。主要副本保证了数据的高可用性,而次要副本采用 LRU 缓存机制,根据查询需求动态调整。这种副本管理策略提高了数据的可靠性和存储效率。
计算与计算分离
常规应对计算竞争的策略有两种:
- 计算资源过度配置:通过配置过度的资源,应对峰值的数据注入和数据查询。不过这种方式成本昂贵,所以管理员常常会调整内部设置,平衡数据注入和查询性能之间做出妥协。
- 创建数据副本:通过多副本摊平计算竞争。不过也会导致存储成本增加,同时主从副本之间的数据同步延时,可能会引发数据不一致的问题。
Rockset 为了应对计算竞争的问题,设计了一套自己的策略:Rockset 每个计算实例既可以进行写操作(Ingestion、Indexing 和 Compaction),也可以进行读操作(处理 Query 请求)。内存中的 memtable 的副本设计了 Leader 和 Follower 的角色:
- Leader 副本:负责响应 Ingestion、Indexing 和 Compaction
- Follower 副本:负责响应查询请求
这种设计意味着计算密集型的数据注入工作,只发生在 Leader。 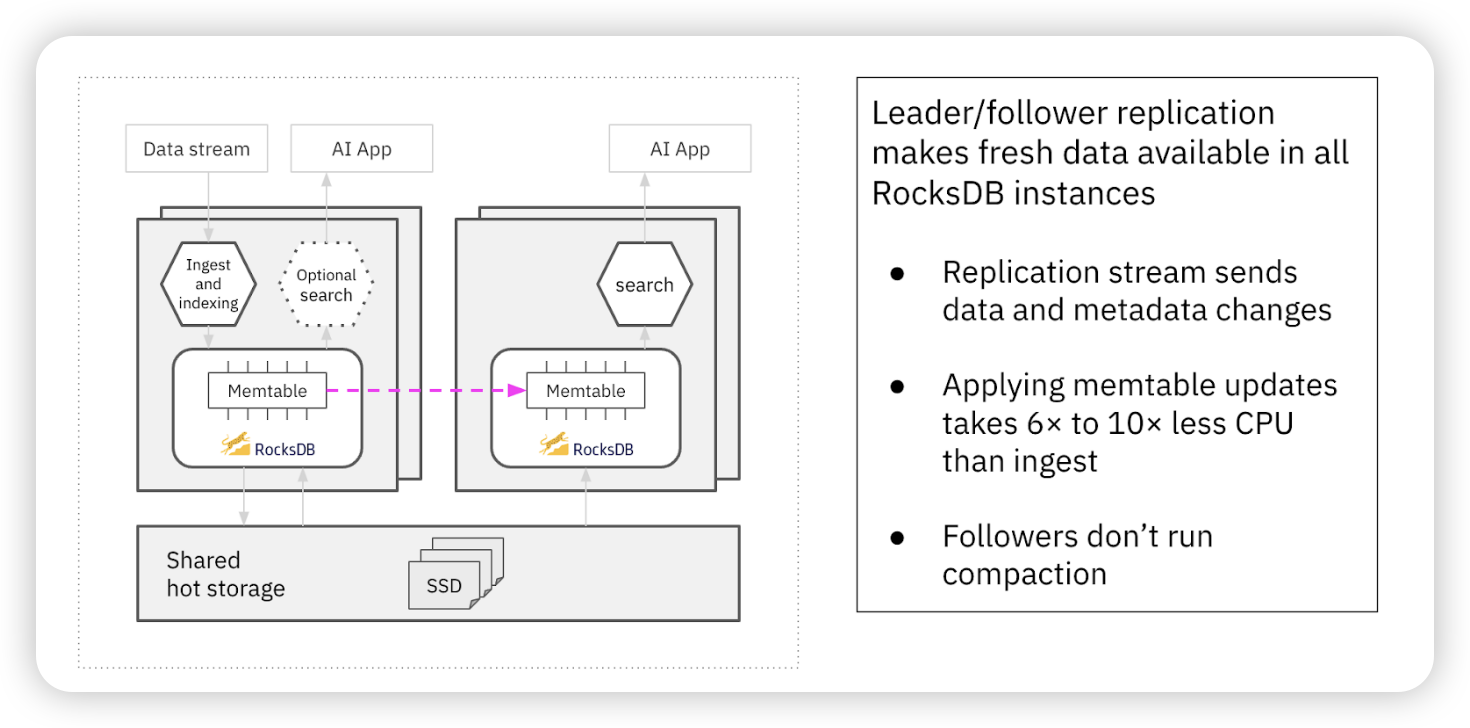
我的思考
思考 1: 混合检索将成为数据库的标配?
现在大模型的火热不仅让大厂们疯狂提升模型效果,也推动了数据系统的发展。从这几年的向量数据库可以看出,现在对非结构化数据的存储和查询需求非常迫切。不过,我个人依然不看好纯向量数据库,因为从去年开始,向量索引基本成了数据库的标配,如 Postgres、Clickhouse、MongoDB 甚至 Redis 都支持了向量检索。可见,向量检索本身计算门槛并不高,对现有数据库架构没什么挑战。随着最近的 GraphRAG 开始火热,在原有数据库架构上支持图数据库,应该也会成为下一个竞争点。对于底层是 KV 的 Rockset 或 TiDB 估计问题不大(TiDB 已经支持了 Knowledge Graph),就看其他关系数据库或分析数据库如何跟上了。
思考 2: OpenAI 为什么会收购 Rockset?
目前我的猜测有三个:
- 增强 Chat GPT 的 RAG 系统:OpenAI 拥有世界上最强的大模型,但 ChatGPT 的 RAG 并没有那么强大,也没办法长期管理用户的文档。
- 服务于内部模型训练和数据管理:目前业界从 LLM 到 MLM 的迁移基本已经是共识,对于非结构化的数据分析显得更加重要。
- 面向企业:目前 OpenAI 还没有怎么面向企业用户,如果后续有进军 to B 市场计划,数据系统是企业知识库的一个基础。
参考资料
- OpenAI Acquires Rockset | Rockset
- rockset.com/Rockset_Concepts_Design_Architecture.pdf
- rockset.com/Rockset_for_Hybrid_Search.pdf
- Converged Index: The Secret Behind Rockset's Fast Query Speed | Rockset
- How Rockset built vector search for scale in the cloud | Rockset
- Strata 2019: Rockset - A data system for low-latency queries for search and analytics - YouTube
- How we built vector search in the cloud. - YouTube
- Rockset 产品白皮书解读 | 刘家财的个人网站
- Roaring Bitmaps
- Roaring Bitmap 的简介 - 掘金
- GitHub - rockset/rocksdb-cloud: A library that provides an embeddable, persistent key-value store for fast storage optimized for AWS