SkipList 介绍
SkipList(跳跃表)是一种随机化数据结构,基于并联的链表,实现简单,插入、删除、查找的复杂度均为O(logN)。
SkipList 是对有序的链表增加上附加的前进链接,增加是以随机化的方式进行的,所以在列表中的查找可以快速的跳过部分列表,因此得名。所有操作都以对数随机化的时间进行。
此外,SkipList 在当前热门的开源项目中也有很多应用,比如 LevelDB 的核心数据结构 memtable 以及 redis 的 sorted set。在 JDK 中,ConcurrentSkipListMap 的核心数据结构也是利用 SkipList 实现的。
SkipList 主要思想
先看一下普通的有序单链表: 
要在里面查找一个值就需要顺序比较,如何降低复杂度,折半查找也却可以将复杂度降到 O(log N),但不适应单链表,那就将折半的思想抽出来,隔一段位置就建立一个标签索引,根据标签索引缩短查找范围,就是 SkipList,如下图:
 SkipList
通过对间隔的数据做一个标签索引,产生了多层单链表,在最高层依次确定查找数据的范围,最终将范围缩小到可接受值,我们看
SkipList
其实就是一个二叉查找树的变形,只是所有的数据都在最左段,其他节点用来建立查找索引,如此
SkipList 的插入删除就比二叉查找树方便多了。
SkipList
通过对间隔的数据做一个标签索引,产生了多层单链表,在最高层依次确定查找数据的范围,最终将范围缩小到可接受值,我们看
SkipList
其实就是一个二叉查找树的变形,只是所有的数据都在最左段,其他节点用来建立查找索引,如此
SkipList 的插入删除就比二叉查找树方便多了。
一个 SkipList,应该具有以下特征:
- 一个 SkipList 应该有几个层(level)组成;
- SkipList 的第一层包含所有的元素;
- 每一层都是一个有序的链表;
- 如果元素 x 出现在第 i 层,则所有比 i 小的层都包含 x;
- 第 i 层的元素通过一个 down 指针指向下一层拥有相同值的元素;
- 在每一层中,-1 和 1 两个元素都出现(分别表示 INT_MIN 和 INT_MAX);
- Top 指针指向最高层的第一个元素。
SkipList 主要操作
查找
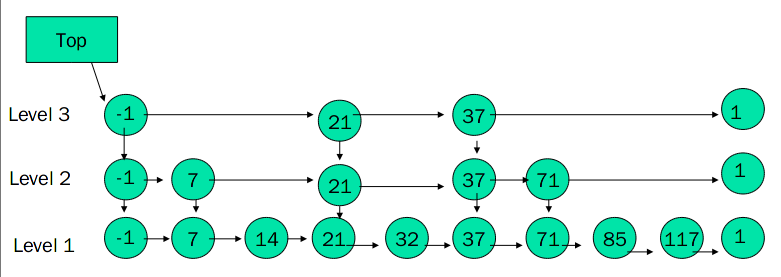
例如:查找元素 117
- 比较 21, 比 21 大,往后面找
- 比较 37, 比 37 大,比链表最大值小,从 37 的下面一层开始找
- 比较 71, 比 71 大,比链表最大值小,从 71 的下面一层开始找
- 比较 85, 比 85 大,从后面找
- 比较 117, 等于 117, 找到了节点。
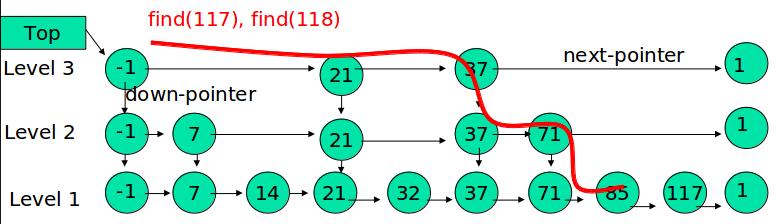
插入
先确定该元素要占据的层数 K(采用随机的方式),然后在 Level1 … LevelK 各个层的链表都插入元素。
例如:插入 119, K = 2 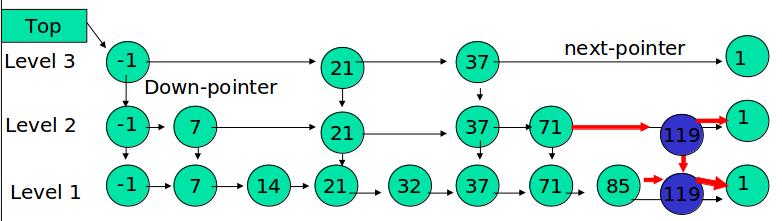 如果 K
大于链表的层数,则要添加新的层。
如果 K
大于链表的层数,则要添加新的层。
例如:插入 119, K = 4
删除
在各个层中找到包含 x 的节点,使用标准的 delete from list 方法删除该节点。
例如:删除 71 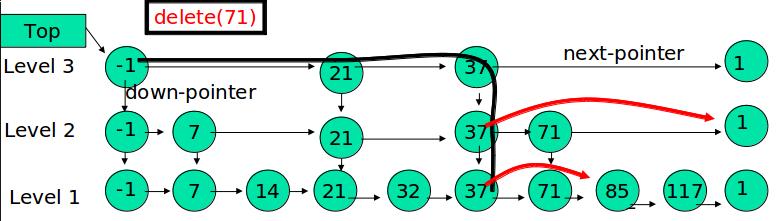
SkipList 复杂度分析



参考资料
http://blog.csdn.net/daniel_ustc/article/details/20218489 http://dsqiu.iteye.com/blog/1705530 http://in.sdo.com/?p=711