概述
投机解码(Speculative Decoding)是一种新兴技术,用于加速大型语言模型(LLM)的推理过程。该方法不仅能够显著提升推理速度,还能保持解码质量,因此受到广泛关注。本文将简要介绍投机解码的实现原理,并探讨对该算法原始实现的改进方案。
自回归解码
传统的自回归解码方法中,输入的 token 为“t1, t2”,输出为“t3, t4, t5”,通常需要分三个步骤逐步生成“t3, t4, t5”。由于每个 token 是逐一生成的,这些步骤无法通过并行计算来加速推理过程(更多细节可以参考:LLM 模型推理入门)。
具体步骤如下:
Step 1:t1, t2 -> 目标 LLM -> t3
Step 2:t1, t2, t3 -> 目标 LLM -> t4
Step 3:t1, t2, t3, t4 -> 目标 LLM -> t5
投机解码
投机解码的核心思想是“先预测后验证”(draft-then-verify)。它在原有 LLM 基础上引入了一个小型的 Draft Model。具体流程分为两步:
Step 1(预测):t1, t2 -> Draft Model -> t3, t4, t5
Step 2.1(验证):t1, t2 -> 目标 LLM -> t3
Step 2.2(验证):t1, t2, t3 -> 目标 LLM -> t4
Step 2.3(验证):t1, t2, t3, t4 -> 目标 LLM -> t5
验证过程可以在同一个批次中并行执行,并通过验证结果确定最终的解码输出。通过这种方式,LLM 的推理解码速度通常是原来的三倍。
投机解码的关键要素
从上面的例子可以看出,投机解码想要实现有效的推理加速,依赖于以下几个关键要素:
Draft Model 的准确性
使用小型的 Draft Model 生成多个可能的 token,这个模型需要与目标 LLM 在行为上有较好的对齐,以确保预测结果的准确性。如果 Draft Model 生成的 token 与目标 LLM 输出相差较大,将影响解码速度。例如,在以下流程中:
Step 2.1(验证):t1, t2 -> 目标 LLM -> t3
Step 2.2(验证):t1, t2, t3 -> 目标 LLM -> t4
Step 2.3(验证):t1, t2, t3, t4 -> 目标 LLM -> t5如果在 t4 位置发生预测错误,最终的输出只能是“t3, t4”,此时解码速度最多是原来的两倍。
更极端的情况是,预测完全错误,如下所示:
Step 2.1(验证):t1, t2 -> 目标 LLM -> T3
Step 2.2(验证):t1, t2, t3 -> 目标 LLM -> T4
Step 2.3(验证):t1, t2, t3, t4 -> 目标 LLM -> T5此时,最终输出只能是“t3”,解码速度与原速度相同,且考虑到 Draft Model 的计算时间,速度可能会更慢。
Draft Model 的推测速度
假设 Draft Model 的推测速度非常快,几乎可以忽略不计。这一假设对 Draft Model 的选择至关重要。
常见的 Draft Model
小型模型作为 Draft Model
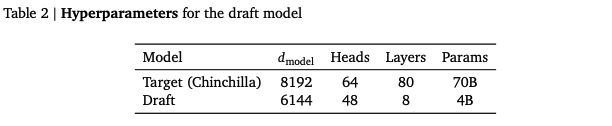
Draft Model 可以采用与目标 LLM 相同的模型架构,只是参数量较小。在《Accelerating Large Language Model Decoding with Speculative Sampling》一文中,建议其参数量为目标 LLM 的二十分之一。
搜索引擎作为 Draft Model
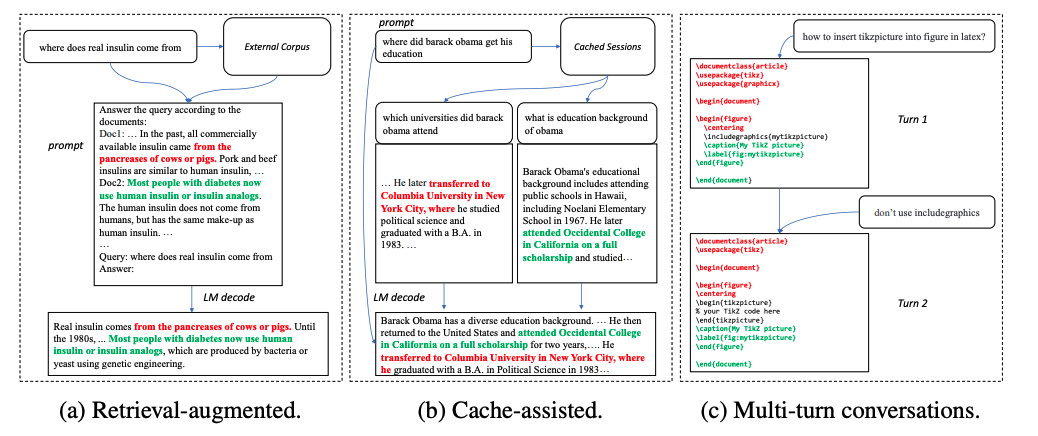
在《Inference with Reference: Lossless Acceleration of Large Language Models》一文中指出,对于 RAG 类型的生成任务,可以通过检索方法,找到相关文本片段作为候选 token 进行验证。
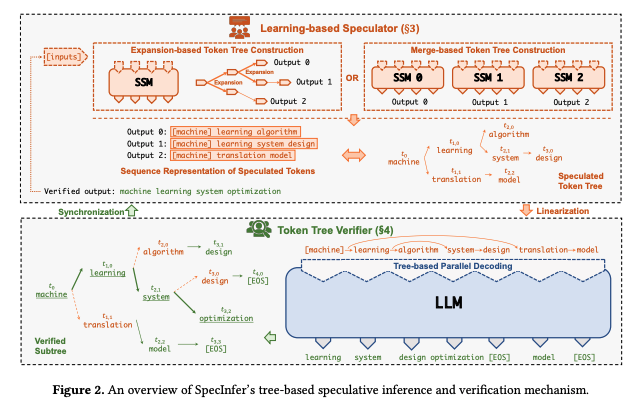
集成多个 Draft Model
《SpecInfer: Accelerating Generative Large Language Model Serving with Tree-based Speculative Inference and Verification》提出,使用多个小型 Draft Model 来预测 LLM 的输出,并通过集成学习方法提高结果的多样性。