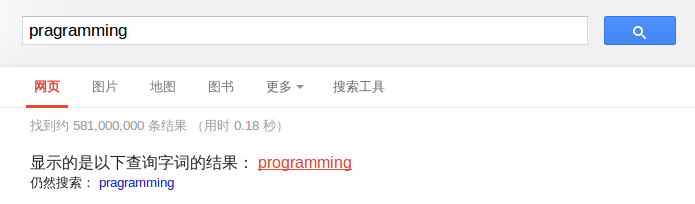
P(w|c)的含义是,在试图拼写 c 的情况下,出现拼写错误 w
的概率。这需要统计数据的支持,但是为了简化问题,我们假设两个单词在字形上越接近,就有越可能拼错,P(w|C)就越大。举例来说,相差一个字母的拼法,就比相差两个字母的拼法,发生概率更高。你想拼写单词
hello,那么错误拼成 hallo(相差一个字母)的可能性,就比拼成 haallo
高(相差两个字母)。
defread_words(): ''' Read bag of words from file ''' f = open('wiktionary', 'r') for line in f.readlines(): DICTIONARY.update({line.split(':')[0] : float(line.split(':')[1])})
defgenerate_edit_distance1_words(word): ''' Generate a set of all words that are one edit distance from word ''' #delete a character for word deletes = [word[1:]] deletes += [str(word[:i] + word[i+1:]) for i inrange(1, len(word))] #change position between two character for word transposes = [str(word[1] + word[0] + word[2:])] transposes += [str(word[:i-1] + word[i] + word[i-1] + word[i+1:]) for i inrange(2, len(word))] #replaces one character replaces = [str(c + word[1:]) for c in string.lowercase] replaces += [str(word[:i] + c + word[i+1:]) for i inrange(1, len(word)) for c in string.lowercase] #insert one character inserts = [str(c + word) for c in string.lowercase] inserts += [str(word[:i] + c + word[i:]) for i inrange(1, len(word)) for c in string.lowercase] inserts += [str(word + c) for c in string.lowercase]
defwords_filter(words): ''' Word filter ''' returnset(word for word in words if word in DICTIONARY.keys())
defcandidates(word): ''' Get all candidates for word ''' if word in DICTIONARY.keys(): returnset([word]) else: return words_filter([word]) | words_filter(generate_edit_distance1_words(word))
defcorrect(word): ''' correct the word. ''' candidate_words = candidates(word) candidate_dict = {} for item in candidate_words: candidate_dict.setdefault(item, 0) candidate_dict.update({item : DICTIONARY[item]})
returnmax(candidate_dict, key = lambda x : candidate_dict[x])
defread_words(): ''' Read bag of words from file ''' f = open('wiktionary', 'r') for line in f.readlines(): DICTIONARY.update({line.split(':')[0] : float(line.split(':')[1])})
defgenerate_edit_distance1_words(word): ''' Generate a set of all words that are one edit distance from word ''' #delete a character for word deletes = [word[1:]] deletes += [str(word[:i] + word[i+1:]) for i inrange(1, len(word))] #change position between two character for word transposes = [str(word[1] + word[0] + word[2:])] transposes += [str(word[:i-1] + word[i] + word[i-1] + word[i+1:]) for i inrange(2, len(word))] #replaces one character replaces = [str(c + word[1:]) for c in string.lowercase] replaces += [str(word[:i] + c + word[i+1:]) for i inrange(1, len(word)) for c in string.lowercase] #insert one character inserts = [str(c + word) for c in string.lowercase] inserts += [str(word[:i] + c + word[i:]) for i inrange(1, len(word)) for c in string.lowercase] inserts += [str(word + c) for c in string.lowercase]
defwords_filter(words): ''' Word filter ''' returnset(word for word in words if word in DICTIONARY.keys())
defcandidates(word): ''' Get all candidates for word ''' if word in DICTIONARY.keys(): returnset([word]) else: return words_filter([word]) | words_filter(generate_edit_distance1_words(word))
defcorrect(word): ''' correct the word. ''' candidate_words = candidates(word) candidate_dict = {} for item in candidate_words: candidate_dict.setdefault(item, 0) candidate_dict.update({item : DICTIONARY[item]})
returnmax(candidate_dict, key = lambda x : candidate_dict[x])
if __name__ == '__main__': read_words() print sys.argv[1], '->', correct(sys.argv[1])