Zookeeper 使用了一种称为 Zab(Zookeeper Atomic Broadcast)的协议作为其一致性的核心。Zab 协议是 Paxos 协议的一种变形,下面将展示一些协议的核心内容。
考虑到 Zookeeper 的主要操作数据状态,为了保证一致性,Zookeeper 提出了两个安全属性:
- 全序(Total Order):如果消息 A 在消息 B 之前发送,则所有 Server 应该看到相同结果。
- 因果顺序(Causal Order):如果消息 A 在消息 B 之前发生(A 导致了 B),并且一起发送,则消息 A 始终在消息 B 之前被执行。
为了保证上述两个安全属性,Zookeeper 使用了 TCP 协议和 Leader。通过使用 TCP 协议保证了消息的全序的特性(先发先到),通过 Leader 解决了因果顺序(先到 Leader 先执行)。因为有了 Leader,Zookeeper 的架构就变成为:Master-Slave 模式,但在该模式中 Master(Leader)会 Crash,因此,Zookeeper 引入 Leader 选举算法,以保证系统的健壮性。
当 Zookeeper Server 收到写操作,Follower 会将其转发给 Leader,由 Leader 执行操作。Client 可以直接从 Follower 上读取数据,如果需要读取最新数据,则需要从 Leader 节点读取,Zookeeper 设计的读写比大致为 2:1。
Leader 执行写操作可以简化为一个两段式提交的 transaction:
- Leader 发送 proposal 给所有的 Follower。
- 收到 proposal 后,Follower 回复 ACK 给 Leader,接受 Leader 的 proposal.
- 当 Leader 收到大多数的 Follower 的 ACK 后,将 commit 其 proposal。
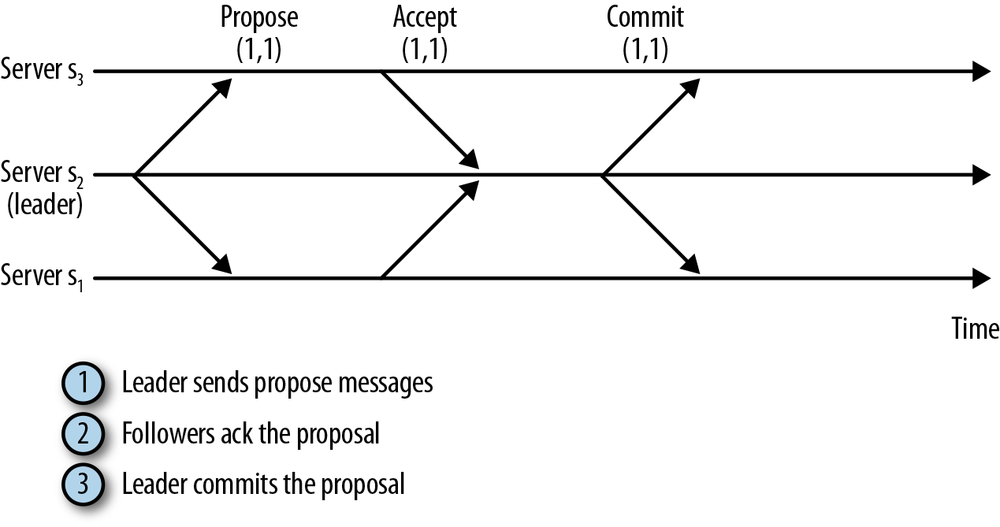
在这个过程中,proposal 的确认不需要所有节点都同意,如果有 2n+1 个节点,那么只要有 n 个节点同意即可,也就是说 Zookeeper 允许 n 个节点 down 掉。任何两个多数派必然有交集,在 Leader 切换(Leader down)时,这些交集依然保持着最新的系统状态。如果集群节点个数少于 n+1 个时,Zookeeper 将无法进行同步,也就无法继续工作。
Zab 与 Paxos
Zab 的作者认为 Zab 与 paxos 并不相同,只所以没有采用 Paxos 是因为 Paxos 保证不了全序顺序:
Because multiple leaders can propose a value for a given instance two problems arise. First, proposals can conflict. Paxos uses ballots to detect and resolve conflicting proposals. Second, it is not enough to know that a given instance number has been committed, processes must also be able to figure out which value has been committed.
举个例子。假设一开始 Paxos 系统中的 Leader 是 P1,他发起了两个事务{t1, v1}(表示序号为 t1 的事务要写的值是 v1)和{t2, v2},过程中 Leader 挂了。新来个 Leader 是 P2,他发起了事务{t1, v1'}。而后又来个新 Leader 是 P3,他汇总了一下,得出最终的执行序列{t1, v1'}和{t2, v2}。
这样的序列为什么不能满足 ZooKeeper 的需求呢?ZooKeeper 是一个树形结构,很多操作都要先检查才能确定能不能执行,比如 P1 的事务 t1 可能是创建节点“/a”,t2 可能是创建节点“/a/aa”,只有先创建了父节点“/a”,才能创建子节点“/a/aa”。而 P2 所发起的事务 t1 可能变成了创建“/b”。这样 P3 汇总后的序列是先创建“/b”再创建“/a/aa”,由于“/a”还没建,创建“a/aa”就搞不定了。
为了保证这一点,ZAB 要保证同一个 leader 的发起的事务要按顺序被 apply,同时还要保证只有先前的 leader 的所有事务都被 apply 之后,新选的 leader 才能在发起事务。