什么是 Agent 记忆?
Agent 记忆(Agent Memory)是指 AI Agent 在执行任务过程中存储和管理信息的能力和机制。它类似于人类的记忆系统,使 Agent 能够记住过去的交互、经验和知识,并在后续任务中利用这些信息做出更好的决策。这种记忆机制对于实现持续学习和处理长期任务至关重要。
什么 Agent 需要记忆?
 从技术角度来看,Agent
的记忆本质上是对大模型有限上下文的一种扩展。在 Agent
的生命周期中,用户或 Agent 会生成大量数据,而 AI
大模型能够处理的上下文是有限的,通常为 16K 到 2M tokens。这意味着,仅凭
AI 自身的上下文处理能力,无法直接处理如此庞大的数据量。
从技术角度来看,Agent
的记忆本质上是对大模型有限上下文的一种扩展。在 Agent
的生命周期中,用户或 Agent 会生成大量数据,而 AI
大模型能够处理的上下文是有限的,通常为 16K 到 2M tokens。这意味着,仅凭
AI 自身的上下文处理能力,无法直接处理如此庞大的数据量。
从产品角度看,Agent 记忆能够实现个性化交互、保持上下文连贯性,最重要的是有效降低运营成本。
- 个性化交互:例如,用户请求 AI 推荐一部电影。如果 Agent 具有记忆,AI 可以根据用户的历史兴趣推荐用户喜欢的电影类型,避免重复推荐已看过的电影,并根据用户的偏好推荐更符合其口味的影片。这种个性化体验可以增强用户黏性和满意度,提升使用频率。
- 保持上下文连贯性:自然语言交互的特殊性要求 AI 能够理解上下文,否则即使在同一个对话中也可能产生歧义或不连贯的回答。例如,用户询问“昨晚的电影怎么样?”如果没有记忆,AI 可能无法理解用户指的是哪一部电影。但如果 AI 具备记忆,它可以回忆起用户最近观看的电影,并准确回应:“昨晚您看的是《复仇者联盟》,整体评分较高,您觉得怎么样?”这样可以保持对话的流畅性和相关性,避免重复询问和误解。
- 降低运营成本:没有记忆的情况下,AI 每次对话都需要重新读取历史记录并进行上下文推理,这会增加计算资源的消耗并延长响应时间,影响用户体验。而有记忆后,AI 可以直接利用用户的历史信息和偏好来提供服务,避免每次都从头处理所有对话内容。这种方式大大减少了对后端计算的需求,提高了效率,降低了服务器和存储成本,从而有效减少运营成本。
RAG 与记忆的区别
严格来说,记忆是 RAG(Retrieval-Augmented Generation,检索增强生成)的一个子集,二者都从外部提取信息并融入到 LLM(大语言模型)生成的提示中,但它们的应用场景和目标有所不同。核心区别在于:RAG 侧重于知识为中心,而记忆侧重于以用户信息为中心。
- 使用场景
- RAG:用于在大型文档集合(如公司 Wiki、技术文档等)中检索信息。
- 记忆:专注于管理用户互动中的个性化信息,尤其是在多用户环境中。
- 信息密度
- RAG:处理密集的非结构化数据(如文本、表格),主要用于事实检索。
- 记忆:处理用户与 Agent 之间的多轮会话数据,注重优化交互体验。
- 检索方式
- RAG:通过语义搜索和嵌入式检索来匹配精确文档。
- 记忆:侧重于总结和压缩互动中的关键信息,优化上下文体验。
常见的 Agent 记忆机制对比
以下是目前最主流的几种记忆设计机制的对比(图片来公众号坚白
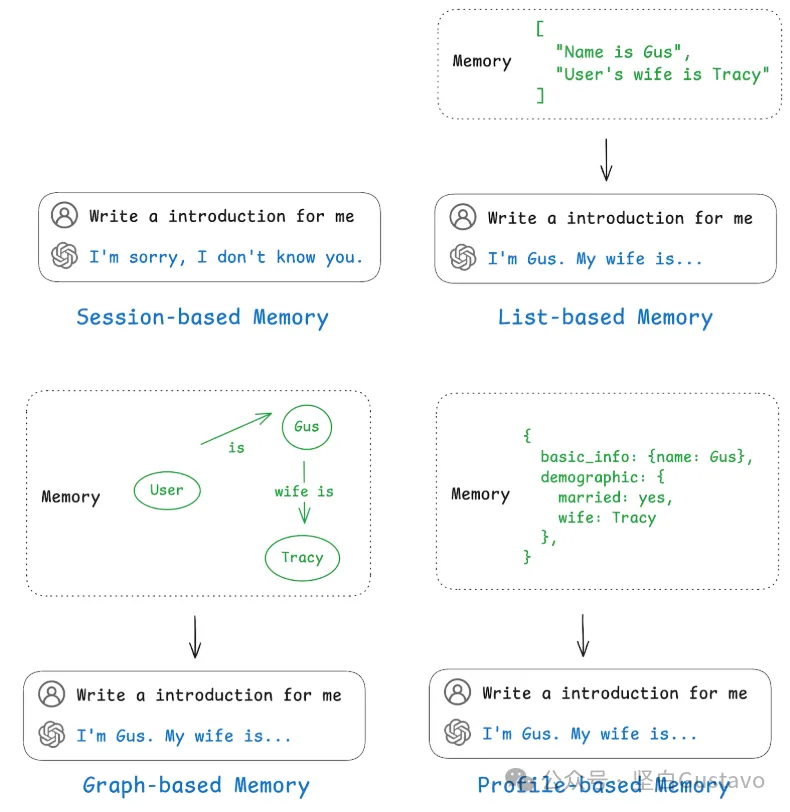
Gustavo): 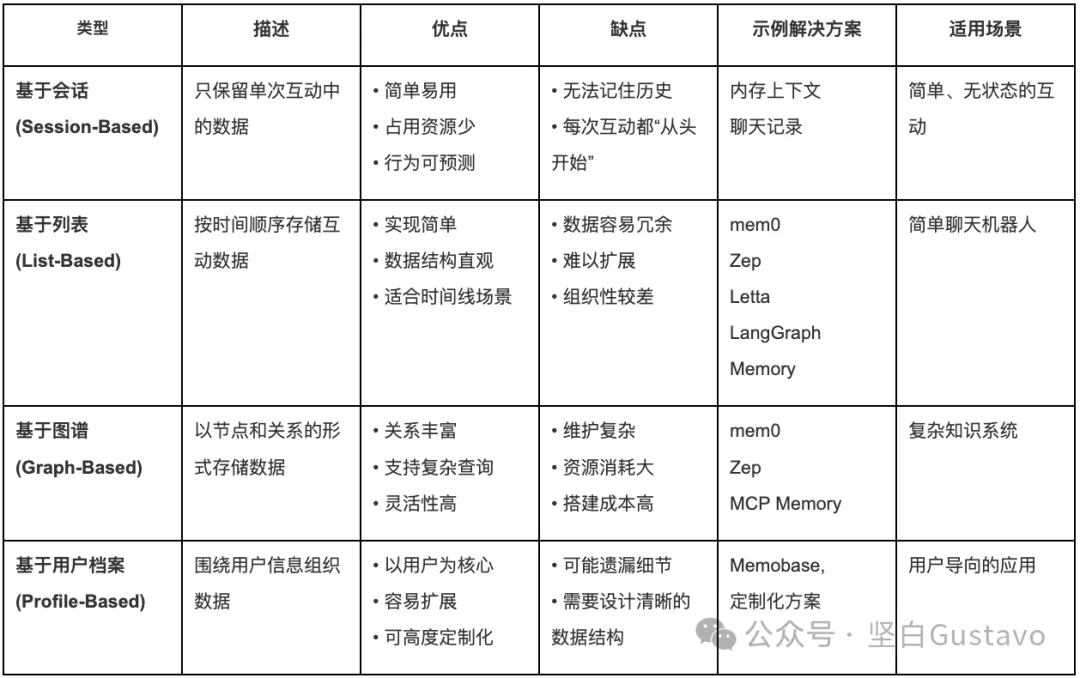 下面是一个具体的例子,帮助大家理解这几种记忆机制的区别:
下面是一个具体的例子,帮助大家理解这几种记忆机制的区别: