春节期间,朋友圈里两件事格外火爆:电影《哪吒 2》的上映和 DeepSeek-R1 模型的发布。尽管网上已有大量关于 DeepSeek-R1 甚至 DeepSeek V3 的分析和复现工作,但作为 AI 技术从业者,我想梳理一下 DeepSeek-R1 的关键技术点,同时澄清一些媒体对 DeepSeek 的误解。
背景
在介绍 DeepSeek 之前,首先对一些技术概念做一些科普,以便于读者更好理解后续的文章内容。
预训练和后训练
预训练(Pre-training)和后训练(Post-training)是大语言模型训练过程中的两个重要阶段。预训练是模型在海量通用文本数据上进行自监督学习的过程,让模型学习语言的基本规律和知识。而后训练则是在预训练基础上,针对特定任务或领域进行额外的训练,以提升模型在这些场景下的表现。
在模型后训练阶段使用 SFT 数据集和强化学习方法是一项重要突破(《Training language models to
follow instructions with human
feedback》),使大语言模型生成的内容更接近人类表达,并由此引发了当前
AI 领域的创新浪潮,而正是 OpenAI 开创的技术。 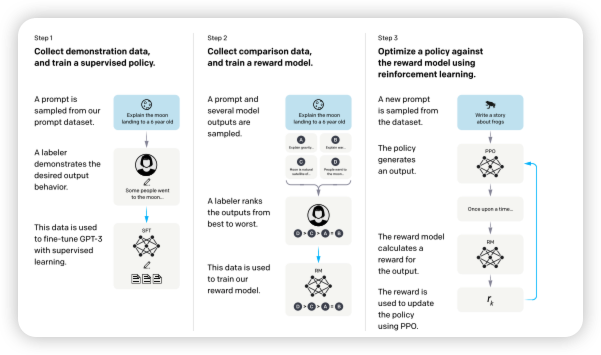 从目前业界实践上看,预训练部分已经没有太多秘密了,更多是数据清晰和组织的过程了。所以,目前业界关注的重点都在模型后训练上。
从目前业界实践上看,预训练部分已经没有太多秘密了,更多是数据清晰和组织的过程了。所以,目前业界关注的重点都在模型后训练上。
MOE
MOE(Mixture of
Experts)是一种模型架构,它由多个专家网络(Experts)和一个门控网络(Gate)组成。门控网络负责根据输入动态选择最合适的专家网络来处理任务。这种架构能够让模型在保持较小参数量的同时,获得更大模型的性能。在大语言模型领域,MOE
架构已经被证明能够显著提升模型性能,同时降低计算成本。这种模型结构的特点就是很难训练,非常容易训练失败(loss
不收敛)。 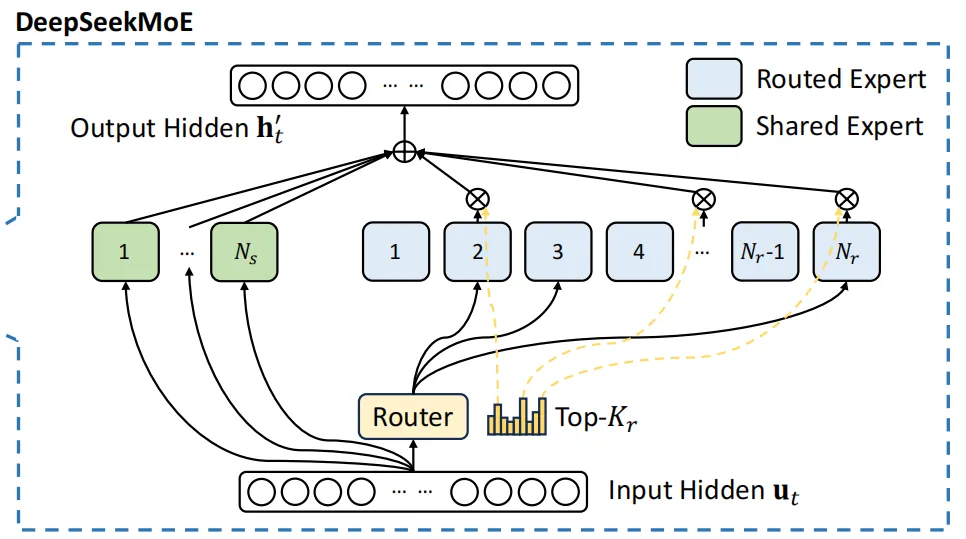
Reasoning
大语言模型本质上是一个文本生成模型,可以简单理解为一个续写句子的过程。长期以来,业界普遍认为这类模型无法具备逻辑推理能力,因此无法解决数学等复杂问题。Reasoning(推理)指的是大语言模型通过逻辑分析和步骤分解来解决复杂问题的能力,包括数学推理、逻辑推理和常识推理等多个方面。高质量的推理能力不仅要求模型能给出正确答案,还需要展示清晰的思考过程和推理链路。
OpenAI 率先实现了模型的 Reasoning 能力,这种能力首次在其 o1-preview 模型中得到体现,目前该系列模型已迭代至 o3。
DeepSeek-R1 的关键技术点
以往的研究主要依赖大量监督数据来提升模型性能。而 DeepSeek 的研究证明,即使不使用 SFT 作为冷启动,仅通过大规模强化学习也能显著提升模型的推理能力。更重要的是,引入少量冷启动数据能进一步优化性能。这也是 DeepSeek-R1 最出圈的创新。
DeepSeek-R1 系列包含以下模型:
- DeepSeek-R1-Zero:无需任何 SFT 数据直接上强化学习,即可获得稳健的 Reasoning 能力。
- DeepSeek-R1:引入少量冷启动数据 (Cold Start Data) ,在进行强化学习,性能更好。
- DeepSeek-R1-Distill-xx:用 DeepSeek-R1 生成数据去蒸馏小模型,让小模型也有 Reasoning 能力。
以下内容主要参考自 DeepSeek-R1 的论文(《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》)。
DeepSeek-R1-Zero: 无需任何 SFT 数据直接上强化学习,即可获得稳健的 Reasoning 能力
DeepSeek-R1-Zero 采用纯强化学习(RL)的方法,从基础模型(DeepSeek-V3-Base)直接进行大规模强化学习训练,而不依赖任何监督微调 (SFT) 数据。这种方法有效激发了模型的自我进化能力,模型在训练过程中自然涌现出多种推理行为,如自我验证、反思以及长链式思维 (Long Chain-of-Thought, CoT)。
强化学习算法与奖励建模
- 算法:采用 Group Relative Policy Optimization (GRPO) 算法,通过组内得分基线代替传统的价值模型,有效降低了 RL 训练成本。
- 奖励模型:设计了基于规则的奖励机制,包括:
- 准确性奖励:依据任务的正确性,如数学题的标准答案或代码编译结果进行评估。
- 格式奖励:要求模型在回答中使用
<think>标签包裹推理过程,用<answer>标签包裹最终答案。
性能表现
- 在 AIME 2024 基准测试中,DeepSeek-R1-Zero 的 pass@1 分数从初始 15.6% 提升至 71.0%,并在多数投票 (majority voting) 下达到了 86.7%,与 OpenAI-o1-0912 相当。
- 随着训练步骤的增加,模型自动延长推理链路,并且在过程中涌现出自我反思(例如在解题过程中主动检查并修正推导错误)。
局限性
- 内容可读性较差,生成的回答可能混合多语言或缺乏结构性标注。
- 在部分任务中存在语言风格不一致的问题。
DeepSeek-R1: 引入少量冷启动数据 (Cold Start Data) ,在进行强化学习,性能更好
为了使 Reasoning 过程更可读,并与社区共享。DeepSeek-R1 相比 R1-Zero,引入了少量(数千条)高质量的冷启动数据 (Cold Start Data) 进行初期微调 (SFT),随后再进行大规模强化学习。这种两阶段训练流程大幅提升了模型的推理能力与可读性。
冷启动数据构建
- 数据来源:
- 通过 Few-shot Prompting 生成长链式推理数据 (Long CoT)。
- 收集并优化 DeepSeek-R1-Zero 生成的高质量输出。
- 由人工标注者进行后期筛选与润色。
- 数据规模:包含约数千条高质量冷启动数据,用于模型初期微调。
强化学习阶段改进
- 一致性奖励:在 RL 阶段引入语言一致性奖励,降低多语言混杂现象,提高输出的可读性。
- 全场景强化学习:在接近收敛时,通过拒绝采样 (Rejection Sampling) 生成 SFT 数据,并加入非推理类任务数据 (如写作、问答等),进行二次 RL 训练。
性能表现
- 在 AIME 2024 中,DeepSeek-R1 的 pass@1 分数提升至 79.8%,超过 OpenAI-o1-1217。
- 在 Codeforces 编程竞赛中,DeepSeek-R1 达到了 96.3% 百分位,展现了卓越的代码推理能力。
DeepSeek-R1-Distill: 用 DeepSeek-R1 生成数据去蒸馏小模型,让小模型也有 Reasoning 能力
DeepSeek-R1-Distill 利用 DeepSeek-R1 生成的 80 万条推理相关数据,对多个小模型进行监督微调 (SFT),从而赋予小模型强大的推理能力。采用纯 SFT 蒸馏,直接使用 DeepSeek-R1 生成的推理数据对小模型进行训练,而不再进行 RL 阶段。
性能表现
- DeepSeek-R1-Distill-Qwen-7B:在 AIME 2024 基准测试中达到了 55.5% 的 pass@1,超越了 QwQ-32B-Preview。
- DeepSeek-R1-Distill-Qwen-32B:在 MATH-500 基准测试中达到了 94.3% 的 pass@1,超过了同类大模型。
澄清媒体对 DeepSeek 的误解
目前媒体对 DeepSeek 有着各种误解,我仅挑选两个比较典型的:
- DeepSeek-V3 模型的训练成本为 557.6 万美元,成本仅为国外三十分之一,硅谷恐慌!
- DeepSeek 成功绕开 CUDA,或将引领国产 GPU 潮流!
- 中国 DeepSeek 大模型成本优势,会不会打破英伟达和美股科技股的泡沫?
1.训练成本真有那么大差距?
首先,让我们看看训练成本 557.6 万美元这个数字的出处。出自 DeepSeek V3 的技术报告《DeepSeek-V3 Technical Report》。
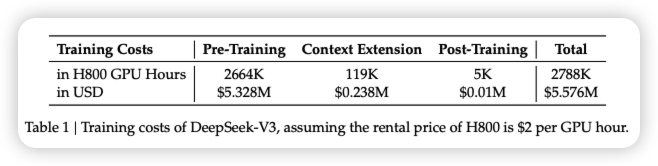 简单来说,DeepSeek-V3 仅用
2048 块英伟达 H800 GPU 就完成了训练,总成本为 557.6
万美元。这相比同等规模的模型(如 GPT-4、GPT-4o、Llama
3.1)的训练成本大幅降低。
简单来说,DeepSeek-V3 仅用
2048 块英伟达 H800 GPU 就完成了训练,总成本为 557.6
万美元。这相比同等规模的模型(如 GPT-4、GPT-4o、Llama
3.1)的训练成本大幅降低。
这种误读有一些客观原因,因为 OpenAI、Meta 官方从来没有公布过 GPT-4、GPT-4o、Llama 3.1 的训练成本,多数人对模型训练成本构成也并不熟悉,但误读背后更多还是主观原因。然而,在这种乐观情绪的驱使下,人们容易忽视"隐性成本"——包括前期研究、模型架构探索、算法研究和模型消融实验等。这些隐性成本往往才是 AI 训练中的主要支出。
甲子光年,给出了一种在同一成本计算方法(按照 GPU
租赁逻辑)下训练成本对比: 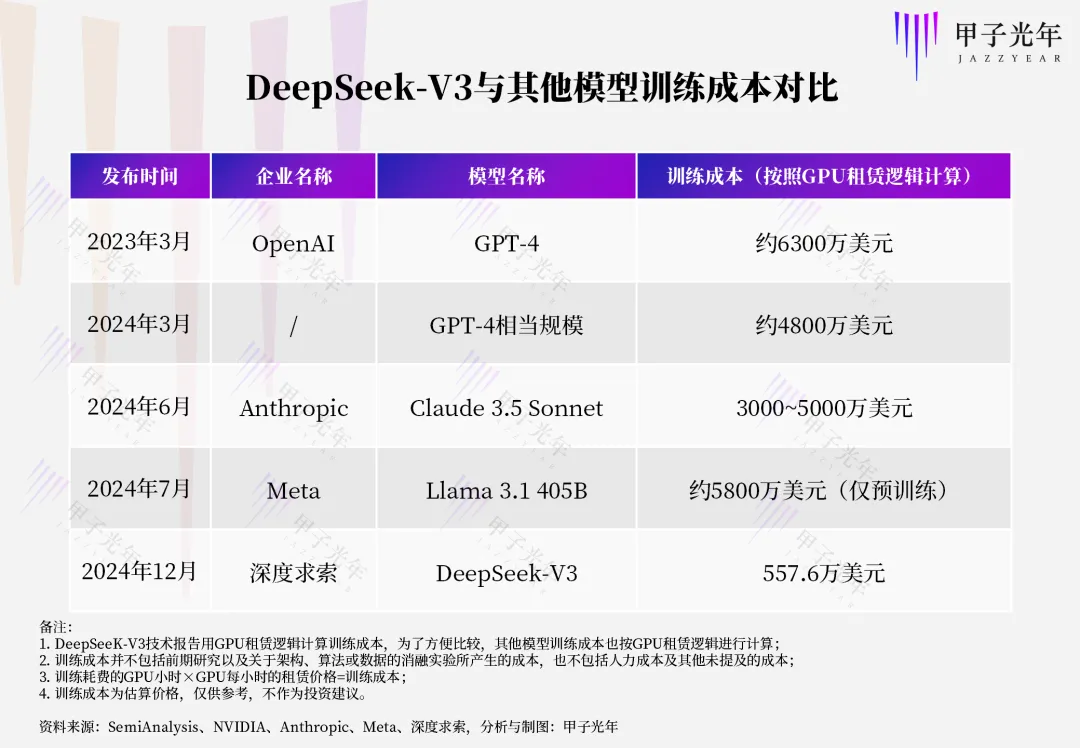 DeepSeek-V3
的训练成本相比其对标模型训练成本大幅降低,但没有到某些人说的“几十分之一”的夸张程度。
DeepSeek-V3
的训练成本相比其对标模型训练成本大幅降低,但没有到某些人说的“几十分之一”的夸张程度。
不管真实训练成本如何,DeepSeek 团队在算法、框架和硬件优化上的协同设计的价值依然是非常巨大的。
2. DeepSeek 是否真的绕过的 CUDA?
DeepSeek 的论文提到,他们采用了 PTX(Parallel Thread Execution)编程技术。通过这种定制化的 PTX 优化,使得 DeepSeek 的系统和模型能够更好地发挥底层硬件的性能。这个观点也是出自 DeepSeek V3 的技术报告。

要解释这个问题,我们需要先理解 PTX 和 CUDA 的区别。首先,PTX(并行线程执行)指令实际上是位于 CUDA 驱动层内部的一个组件,它仍然依赖于 CUDA 生态系统。所以,用 PTX 绕过 CUDA 的垄断这种说法是不准确的。
不过,从技术的角度来看,DeepSeek 这种优化方案并不是在芯片受限的现实条件下的不得已为之,而是主动做的优化,不管芯片用的是 H800 还是 H100,这种方法都能够提高通信互联效率。
3. DeepSeek 能否脱离 NVIDIA?
模型所需的显卡可分为两类:训练显卡和推理(部署)显卡。就目前国内业界发展来看,推理显卡的国产化已相对成熟,且成本较低,这也是当前多家 AI 芯片厂商重点发力的方向。然而,在训练显卡方面,国内仅有华为、中科曙光等少数几家企业能够生产。除了厂商自身外,目前使用国产显卡进行预训练的成功案例并不多见。主要原因在于,没有机构愿意在如此不确定的场景中投入巨额资金,因为一旦训练失败,损失将会非常巨大。