概述
在大语言模型(LLM)的推理过程中,KVCache 已经成为一种不可或缺的推理优化技术。如果你对 LLM 推理的工作原理还不太了解,可以参考《LLM 模型推理入门》一文。本文将介绍 KVCache 的概念以及其工作原理。
为什么需要 KV Cache
为了更好地理解 KVCache 的必要性,我们首先需要对 Transformer 类大语言模型的计算过程有一个整体了解。为了简化描述,以下图示省略了其他计算过程。
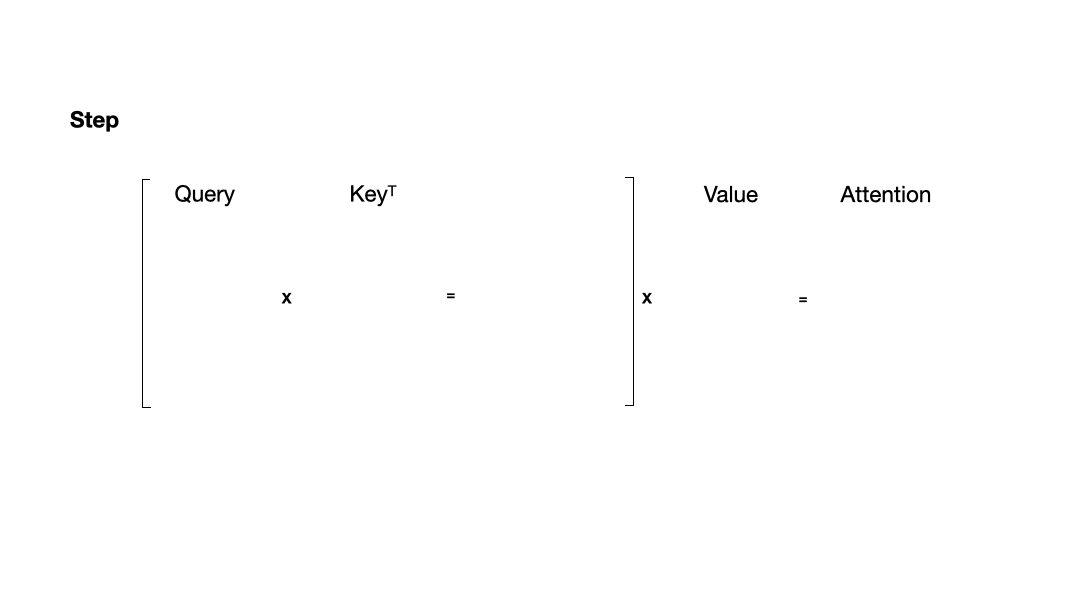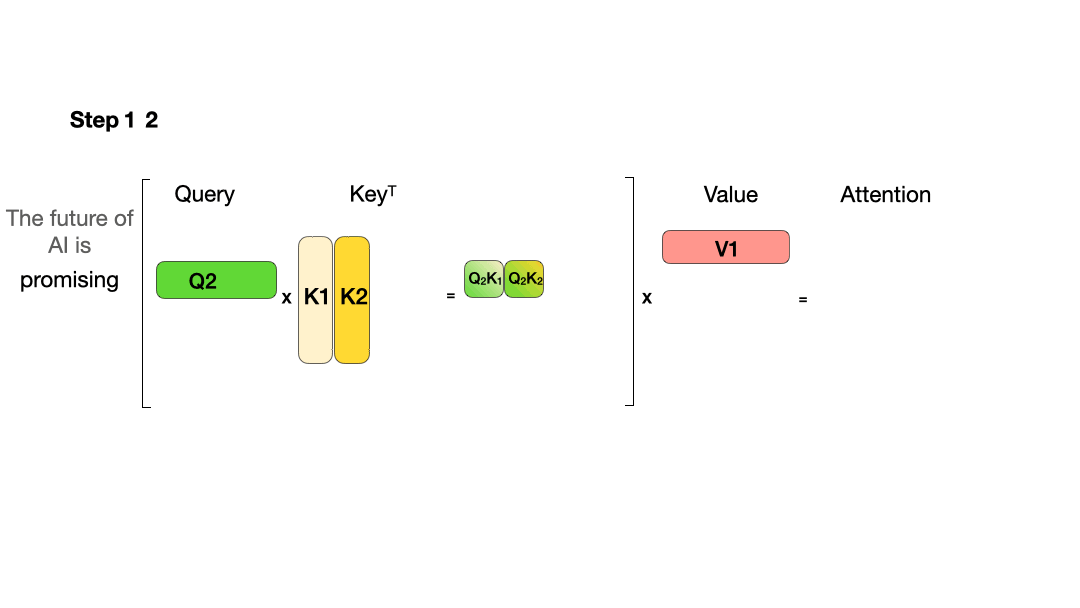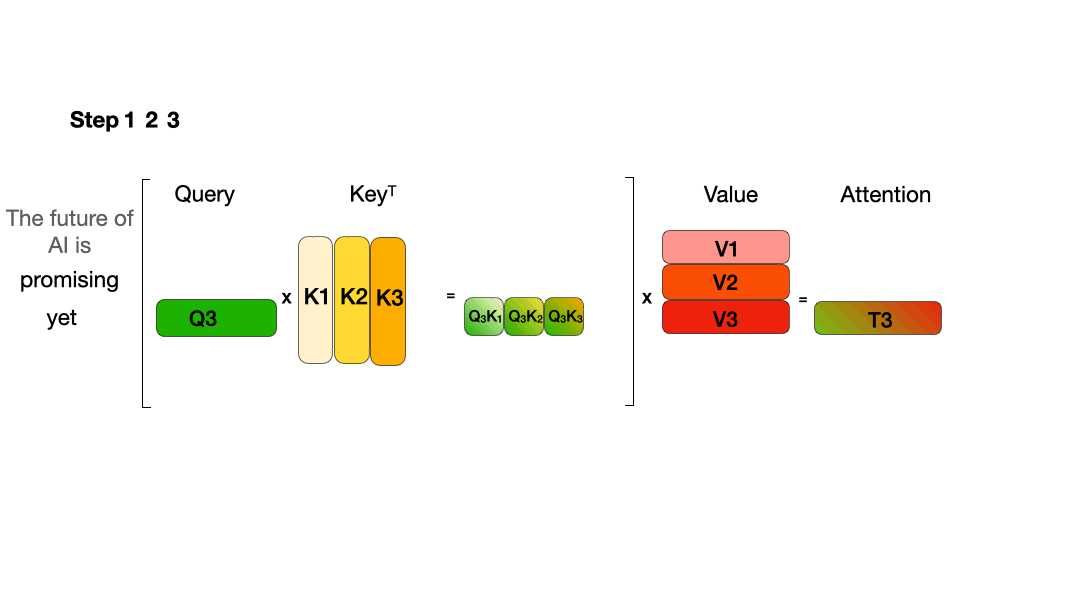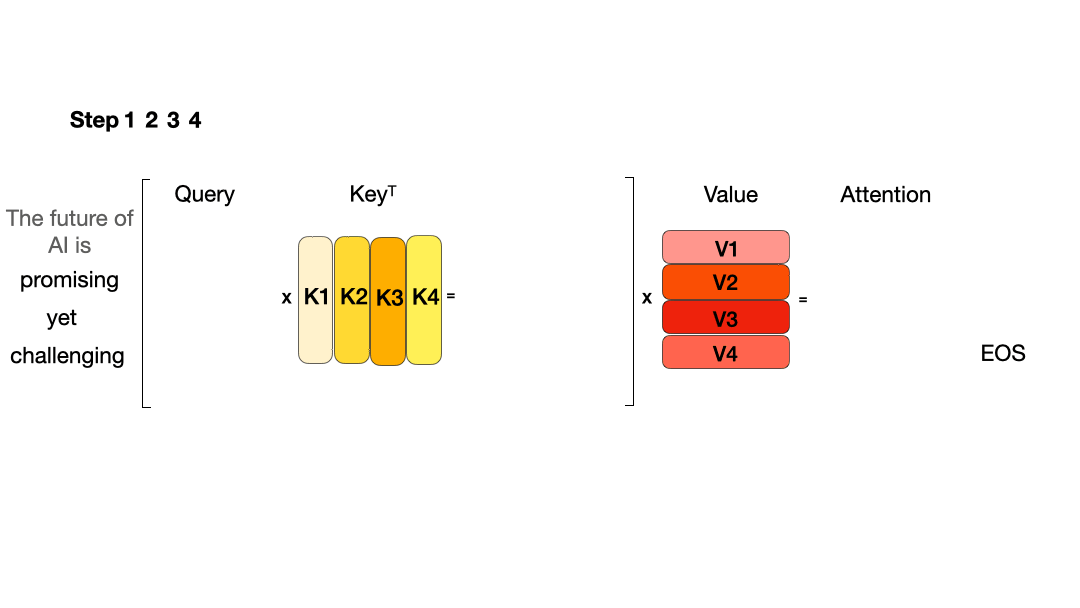
从图中可以看到,在每一步计算中,当前的查询向量 ( Q_i ) 都需要与之前的键向量 ( K_j ) 进行矩阵乘法计算,然后再与之前的值向量 ( V_j ) 进行矩阵乘法。为了节省计算资源,我们可以将之前计算得到的 ( K_j ) 和 ( V_j ) 结果缓存起来,从而使得每次计算时只需进行增量计算。这种缓存机制就是 KVCache。
下面的图展示了在引入 KVCache 后的推理过程:
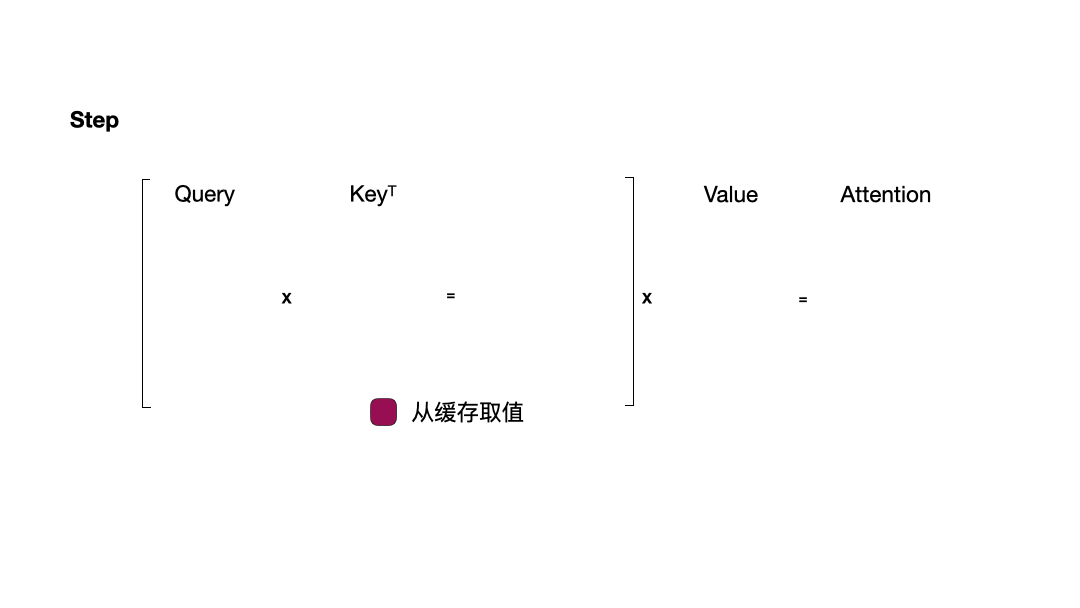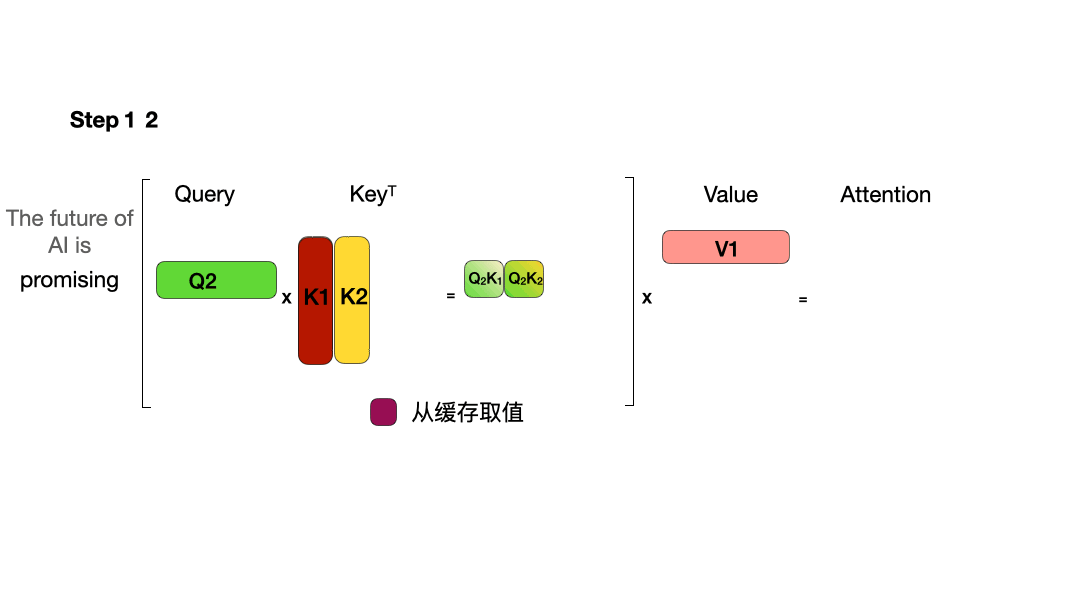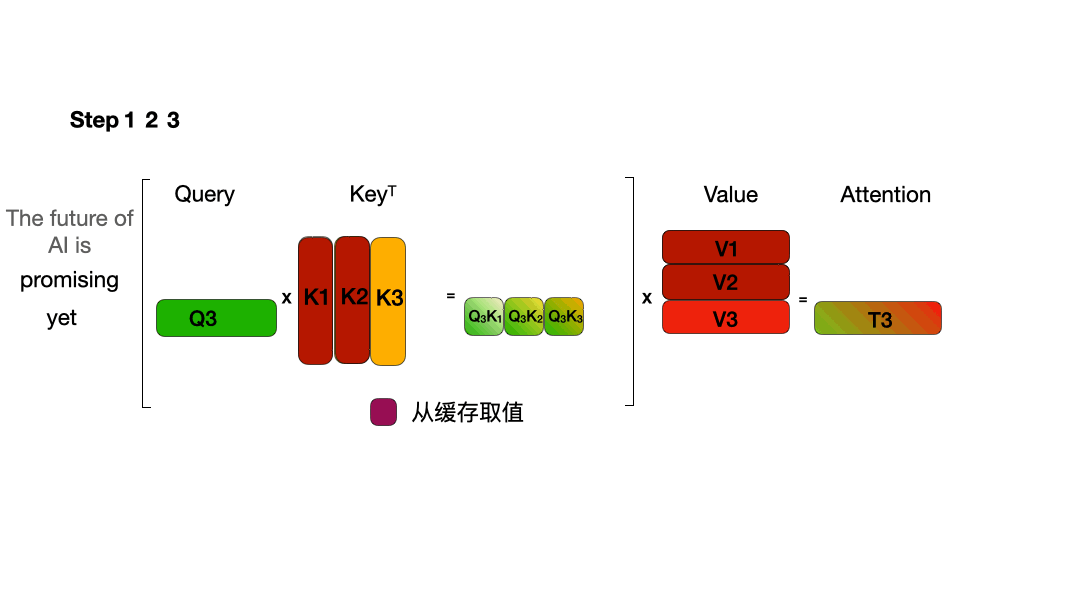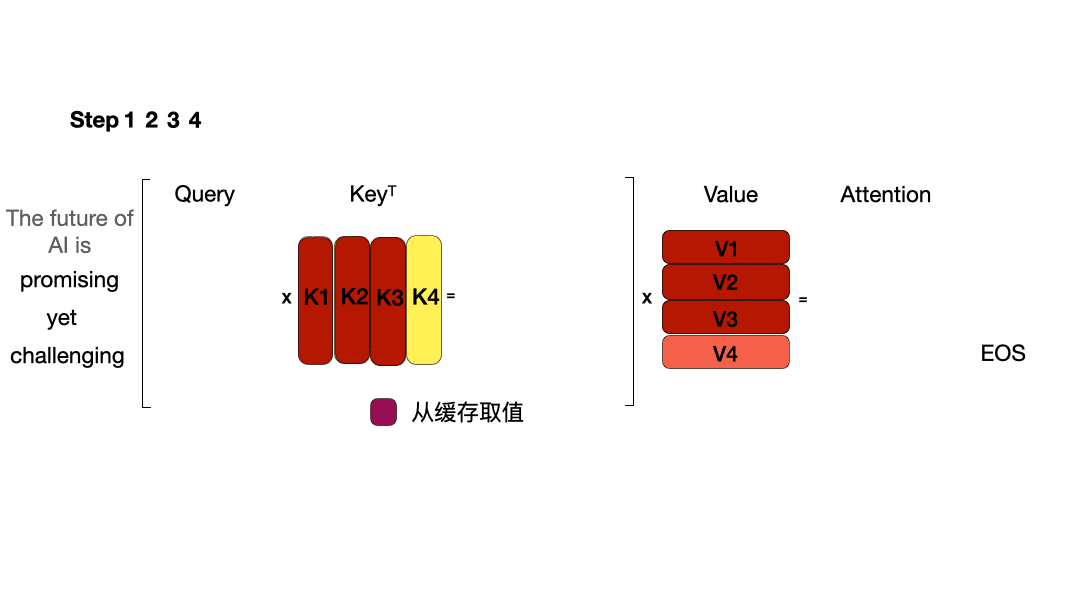
KVCache 显存占用
假设我们使用一个 Transformer 模型,其中每一层的 Key 和 Value
向量的维度为 d_model,序列长度为 n,层数为
L,批量大小为 b。在这种情况下,每一层的
KVCache 显存占用可以通过以下公式计算:
- 每个 token 的 Key 和 Value:每个 token 的 Key 和
Value 向量的维度为
d_model,因此每个 token 的 Key 和 Value 占用的显存为2 * d_model(因为有 Key 和 Value 两部分)。 - 每层的缓存:每层的 KVCache 将缓存每个 token 的 Key
和 Value,因此,对于序列长度为
n,每一层的 KVCache 显存占用为2 * n * d_model。 - 所有层的缓存:如果模型有
L层,那么所有层的 KVCache 显存占用为L * 2 * n * d_model。 - 批量大小:对于批量大小为
b的情况,显存占用则需要乘以b。
因此,KVCache 显存占用的总量为:
Total KV Cache Memory= b * n * d_model * L * 2 * size of float16
其中,size of float16 大约是 2 字节(16 位浮点数)。
KVCache 的存储及实现细节
从上一节的分析可以看出,KVCache 的内存消耗与当前序列长度(即当前 token 数量)、向量维度以及层数成正比。当前 token 数量会随着推理过程不断增加,因此我们需要一种有效的方式来管理内存。常见的解决方法有三种:
- 预分配最大容量缓冲区:要求提前预知最大 token 数量,并为此分配足够的内存。这种方法在大规模模型中不太适用,因为当前许多大模型支持数百万 token,而大部分用户的请求序列长度相对较短。按照最大容量分配显存显然是非常浪费的。
- 动态分配缓冲区大小:类似于经典的 vector append 方式,缓冲区会根据需要自动扩展。当超过当前容量时,内存大小会翻倍。这种方法虽然可行,但在 GPU 上频繁申请和释放内存的开销较大,导致效率较低。
- 数据拆分与元数据管理:将数据按最小单元存储,并使用元数据记录每一块数据的位置。这种方法是当前最常用的方案,称为 PageAttention。程序在初始化时申请一块较大的显存区域(例如 4GB),然后按照 KVCache 的大小将显存划分成多个小块,并记录每个 token 在推理过程中需要访问的小块。显存的分配、释放和管理类似于操作系统对物理内存的虚拟化过程。这一思路被 vLLM(具体参见论文 Efficient Memory Management for Large Language Model Serving with PagedAttention)所采用,并广泛应用于大规模语言模型的推理中。