概述
Reflexion 是一种创新的框架,旨在通过语言反馈增强语言代理(language agents)的学习能力,而不依赖于更新模型权重。这一方法来自论文《Reflexion: Language Agents with Verbal Reinforcement Learning》,被称为言语强化学习(Verbal Reinforcement Learning)。通过语言反馈信号,Agent 能够进行自我反思(Reflection),并将这些反思存储在情景记忆缓冲区(episodic memory buffer)中,从而改进后续的决策。
基础反思(Basic Reflection)
首先,我们来看一种简化版本的反思方法,称为基础反思(Basic Reflection)。它类似于学生(生成器)写作业,而老师(反思者)则负责批改并提出建议,学生根据这些建议进行修改,如此反复进行。
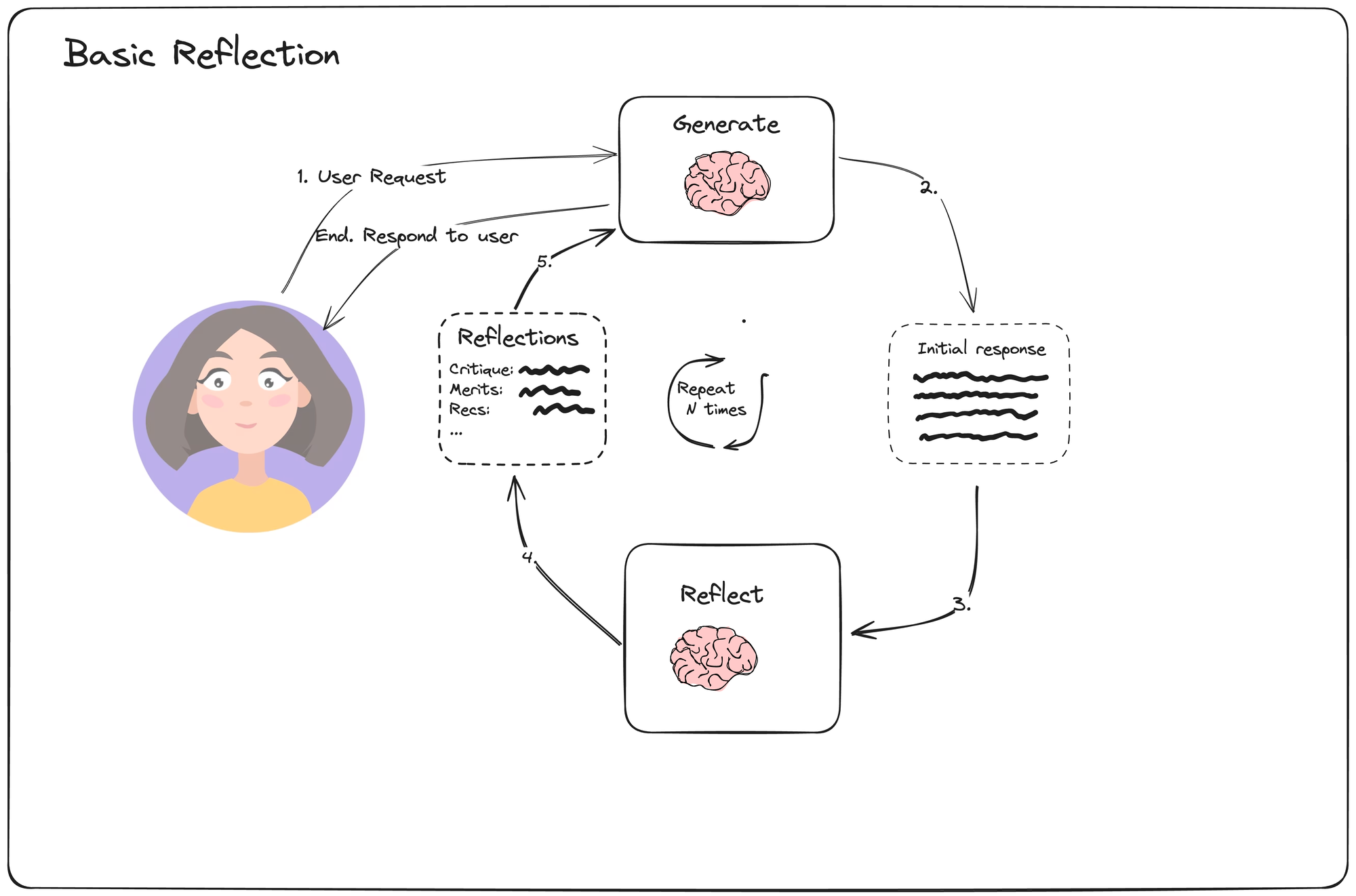
在这部分内容中,您可以参考这段代码:langgraph/examples/reflection/reflection.ipynb at main · langchain-ai/langgraph · GitHub。
反思(Reflection)
反思的工作流程分为两个部分:初始化阶段和循环迭代优化阶段。
初始化
- 模型初始化:
- 初始化三个核心模型:
- Actor:负责生成文本和动作。
- Evaluator:评估 Actor 生成的输出质量。
- Self-Reflection:生成语言反馈,帮助 Actor 改进输出质量。
- 初始化三个核心模型:
- 策略初始化:
- 设置初始策略,并使用该策略生成初始输出结果。
- 初始评估与反馈:
- Evaluator 对初始结果进行评估并生成初始评分。
- Self-Reflection 模型根据评分和结果生成初步的反思总结,并将其存储在长期记忆中。
迭代优化
- 生成新结果:
- Actor 根据当前策略和短期记忆与环境互动,生成新的结果。
- 评估新结果:
- Evaluator 对新生成的结果进行评分。
- 生成反思总结:
- Self-Reflection 模型根据评分、当前结果和长期记忆生成新的反思总结。
- 更新长期记忆:
- 将新的反思总结添加到长期记忆中,更新记忆内容。
- 策略更新:
- Actor 利用更新后的短期和长期记忆生成下一步的动作,以优化决策。
- 重复迭代:
- 持续迭代上述步骤,直到 Evaluator 认为任务完成或达到最大迭代次数。
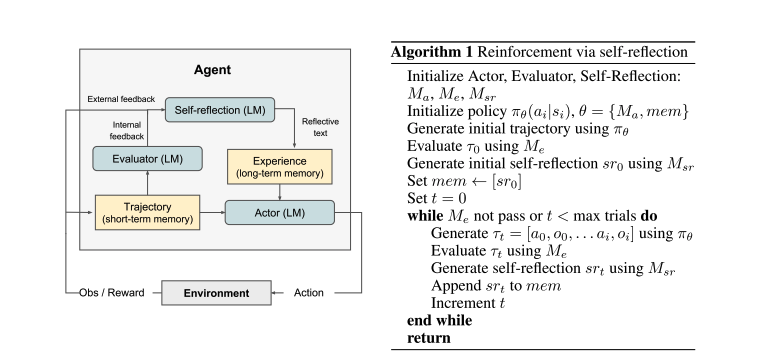
这张图示展示了整个反思过程的循环迭代流程,帮助我们更直观地理解每个步骤之间的关系。