Transformer 模型概述
Transformer 是一种在自然语言处理(NLP)任务中广泛使用的深度学习架构。它由 Google 于 2017 年在Attention Is All You Need 论文中提出,旨在解决序列到序列(seq2seq)任务中的长期依赖问题,同时提高了处理效率。如今,Transformer 不仅在 NLP 领域得到了广泛应用,还被迁移到计算机视觉(CV)领域,成为如 GPT、Llama 等大语言模型的基础。
简单来说,如果把 Transformer 模型看作一个黑盒,比如在机器翻译应用中,输入是一个字符串,输出也是一个字符串。

Transformer 模型结构
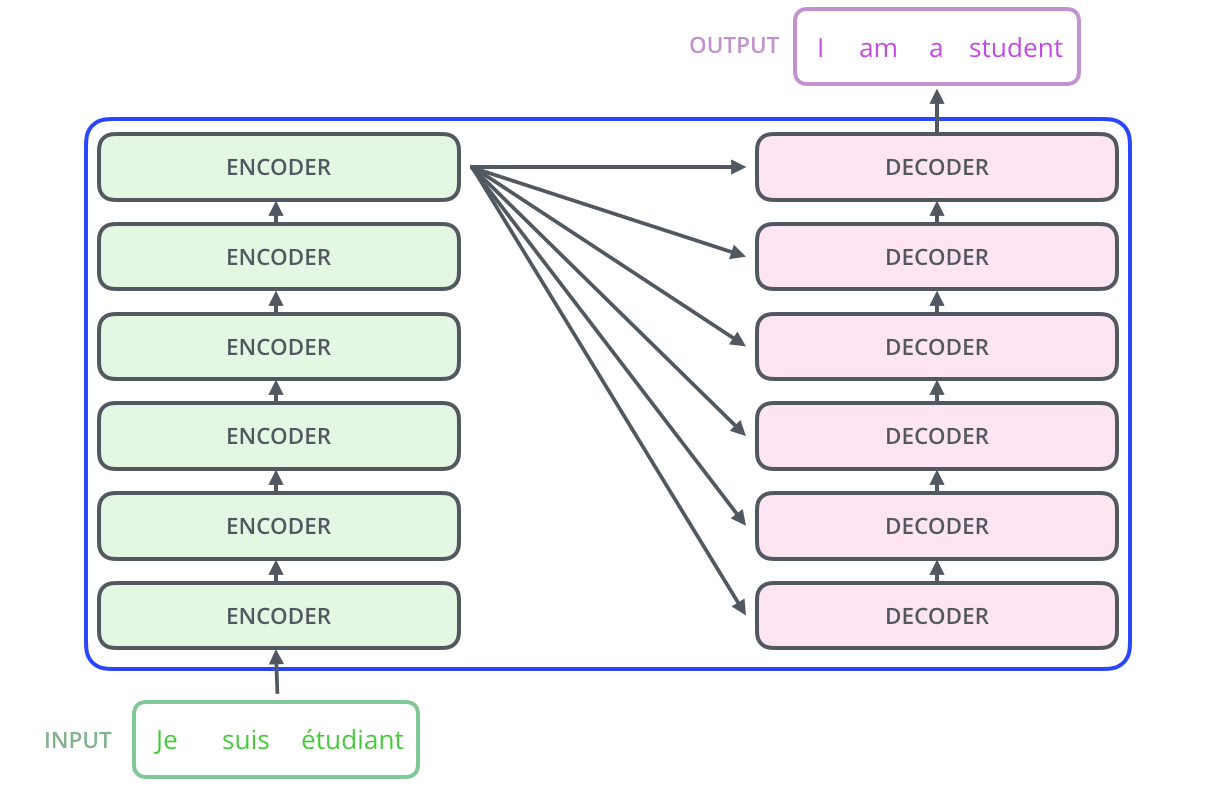
Transformer 由多个编码器(Encoder)和解码器(Decoder)层堆叠而成。
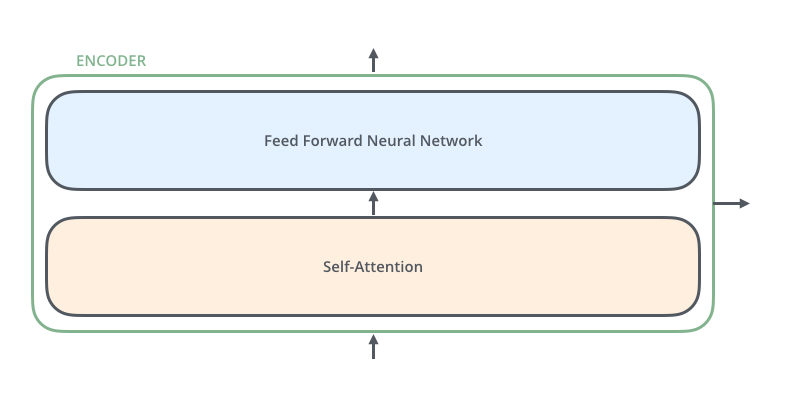
编码器结构(Encoder)
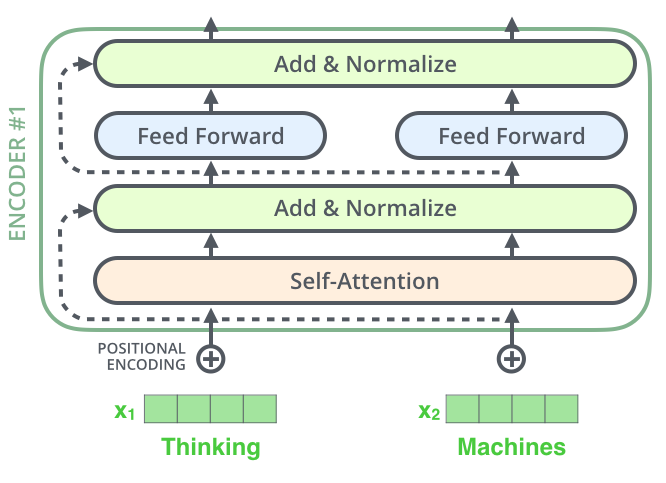
编码器由多个相同的层构成,每一层包含自注意力机制和前馈神经网络。这些层之间的权重并不共享。
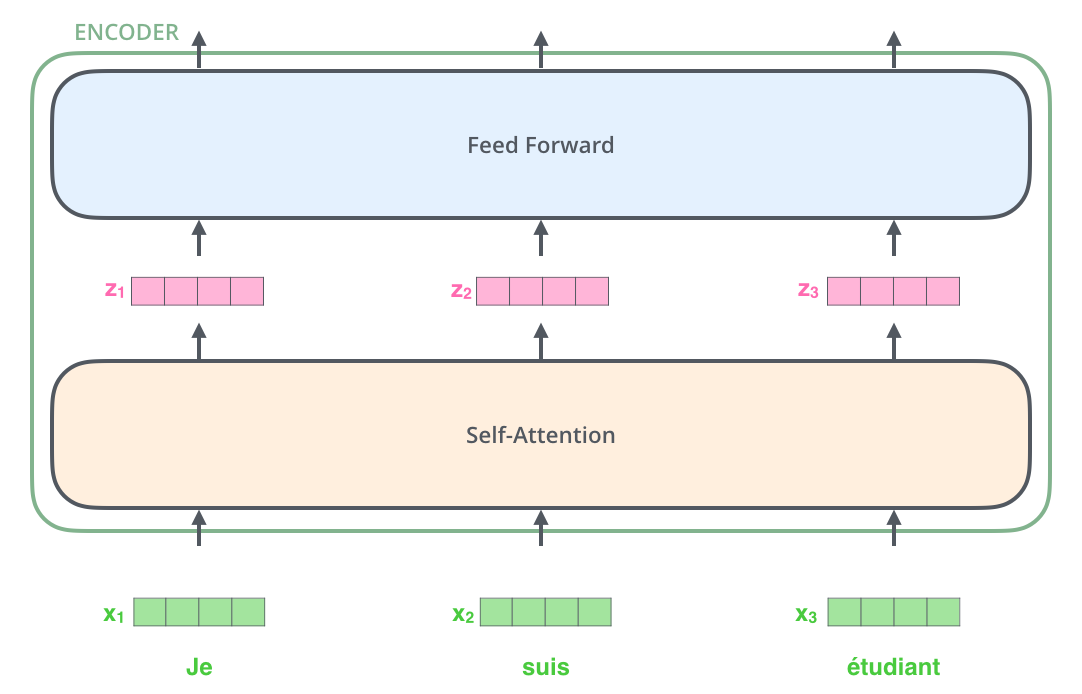
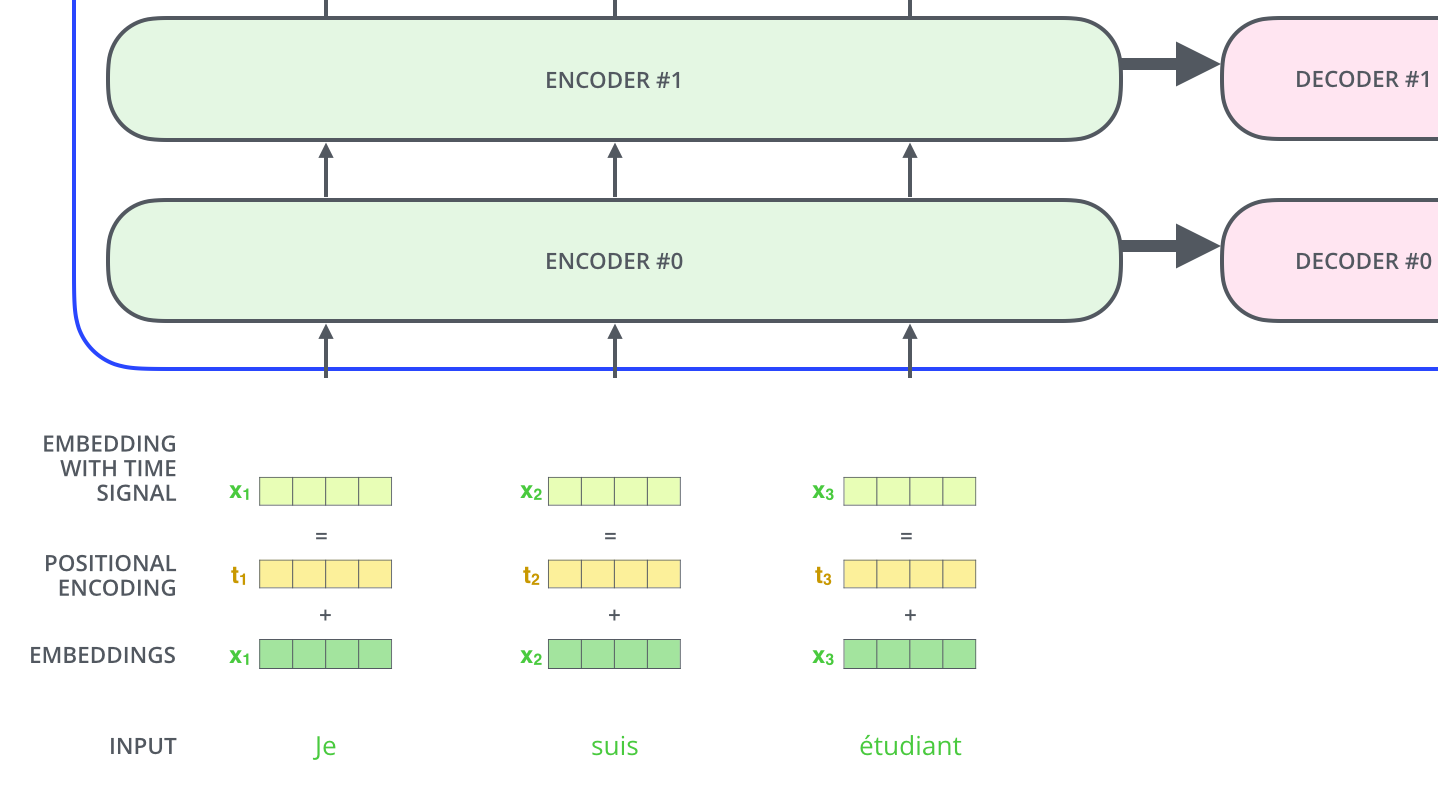
在 NLP 中,模型首先将输入的单词转化为向量表示,这个过程称为 Embedding。每个单词被转化为一个固定维度(如 512 维)的向量。随后,向量会经过多个编码器层处理,每一层的输入是上一层的输出。
自注意力机制(Self-Attention)
自注意力机制让模型在处理某个单词时,可以参考输入句子中的其他单词。比如在句子“The animal didn't cross the street because it was too tired”中,模型需要判断 "it" 指的是“animal”而不是“street”。自注意力机制帮助模型理解句子中各个单词之间的关系。

Self-Attention 的计算过程
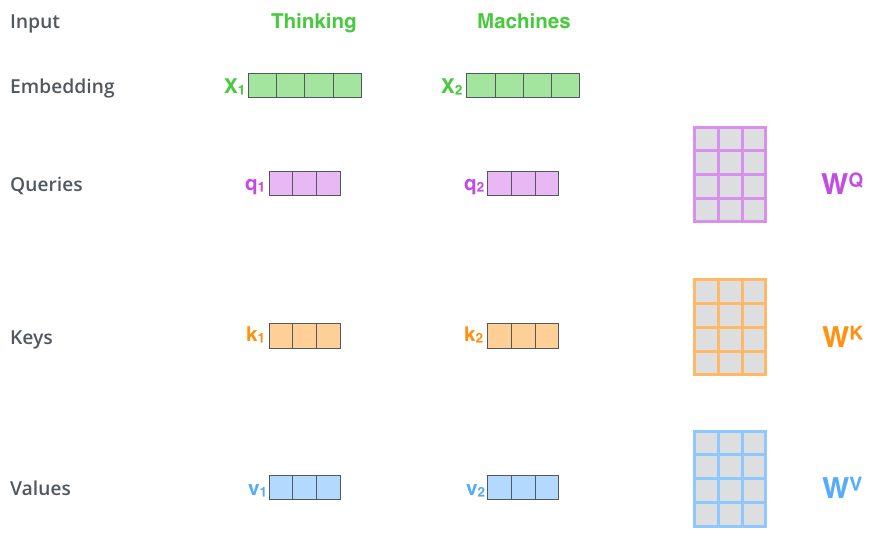
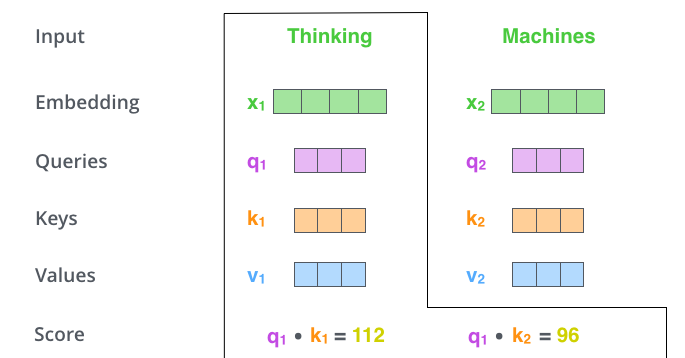
- 计算 Query、Key、Value
向量:对每个输入向量,分别通过不同的权重矩阵计算
Query(Q)、Key(K)和 Value(V)。
- 计算每个单词与句子中其他单词的相似度,即通过点积得到每个单词对其他单词的
score。
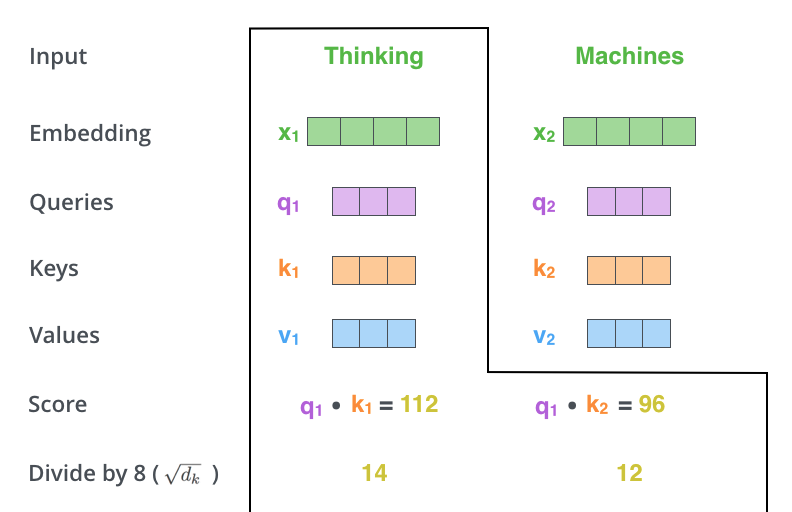
- 缩放 score:为了稳定梯度,将 score
除以向量维度的平方根。
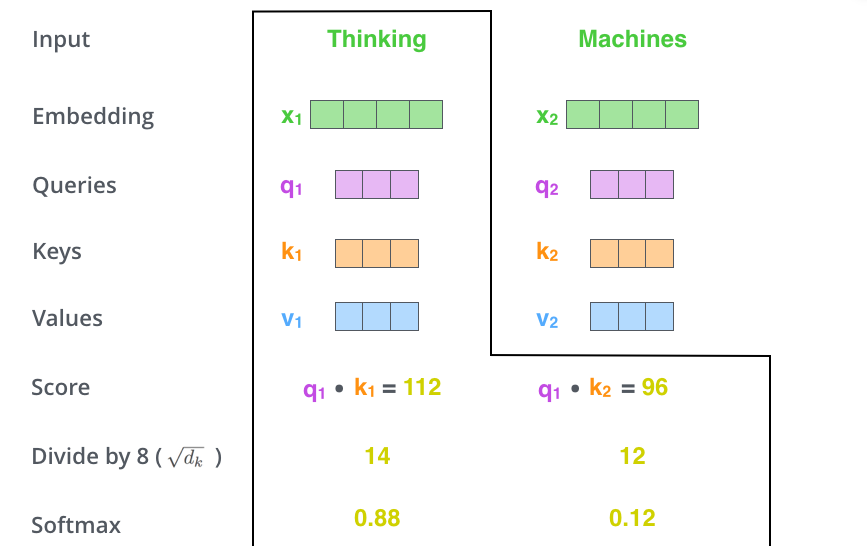
- Softmax 归一化:将缩放后的 score 转化为概率分布。
- 加权求和:将 Softmax 结果与 V 向量相乘,得到
Attention 输出。
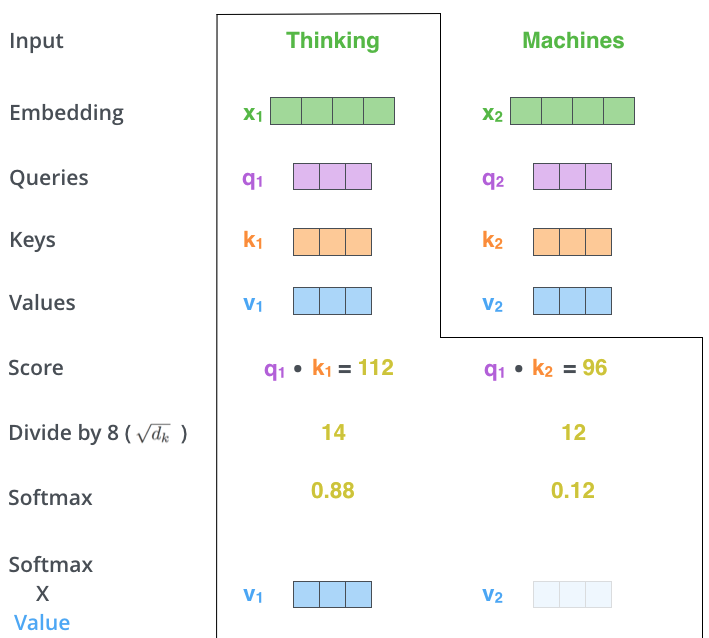
实际计算中,这些操作通过矩阵运算并行处理,使得计算更高效: 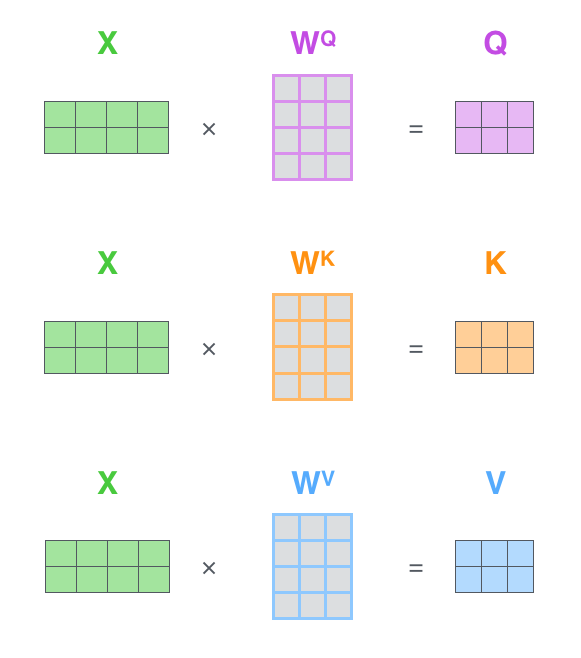
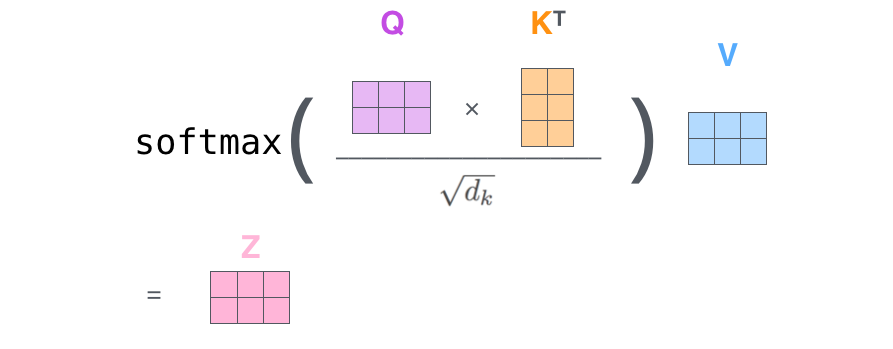
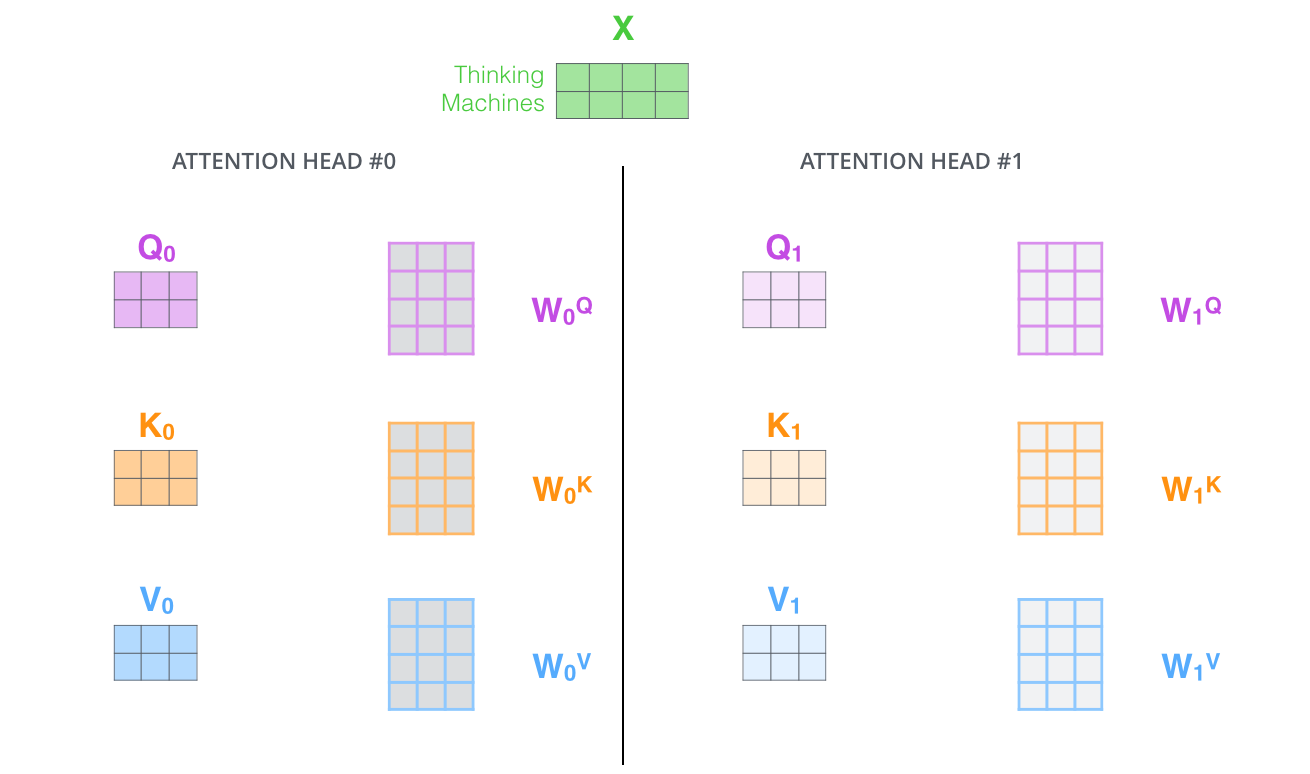
多头注意力机制(Multi-Head Attention)
Transformer 提出了多头注意力机制来增强模型的表现。多头注意力允许模型从不同的角度处理同一句话的信息。通过多个注意力头(如 8 个),模型可以并行计算多个注意力矩阵,捕捉到更多的上下文信息。
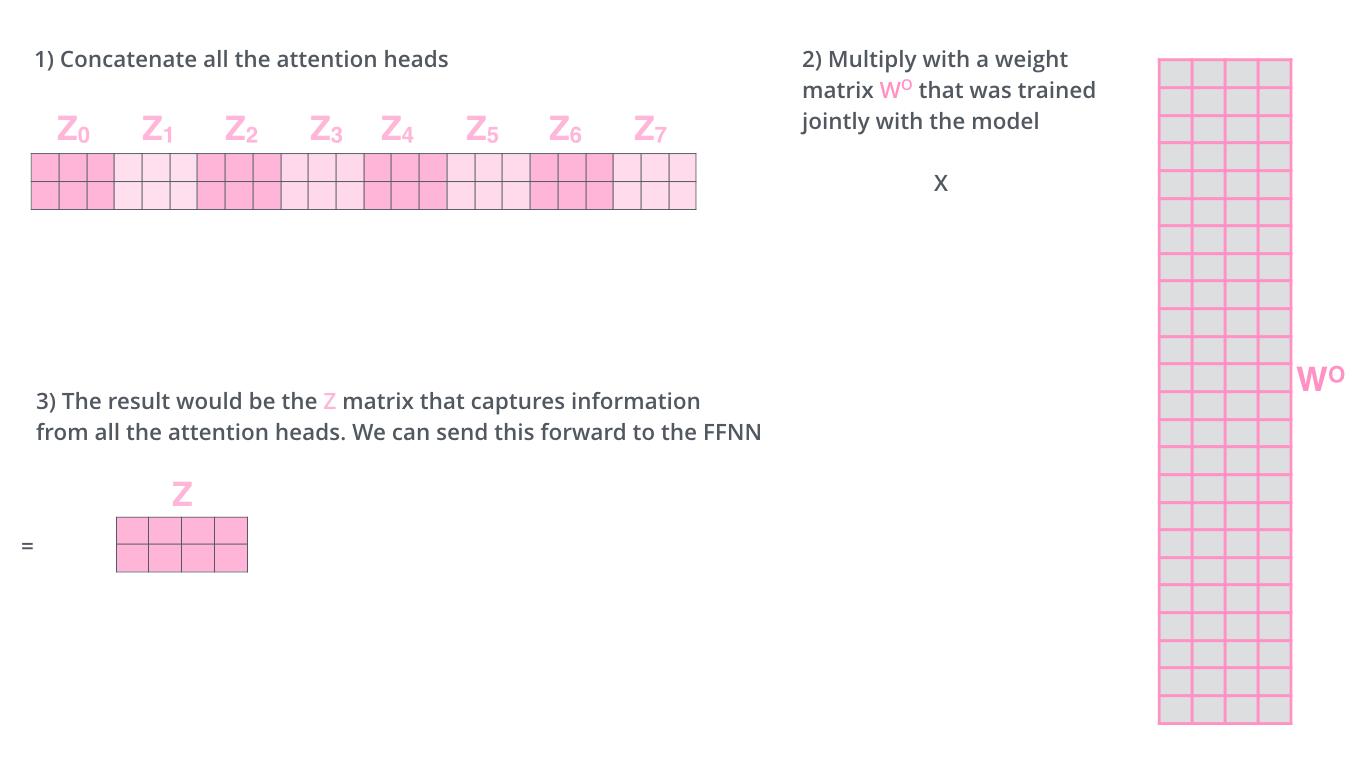
最后,多个注意力头的输出会拼接起来,通过一个线性层压缩为单个矩阵,便于后续处理。
位置编码(Positional Encoding)
由于自注意力机制本身没有考虑到单词的顺序,Transformer 引入了位置编码,为每个词嵌入向量添加位置信息。位置编码可以帮助模型理解词语之间的相对顺序。
残差连接(The Residuals)
每个编码器子层(如自注意力和前馈神经网络)都包含一个残差连接,也就是将输入绕过子层,与输出相加。这一机制帮助防止梯度消失问题,并通过层归一化(Layer Normalization)提高模型的数值稳定性。
解码器结构(Decoder)
解码器结构与编码器类似,由多层堆叠而成。解码器有一个独特的“编码器-解码器注意力”层,帮助解码器根据编码器的输出,参考输入序列,生成合理的输出。
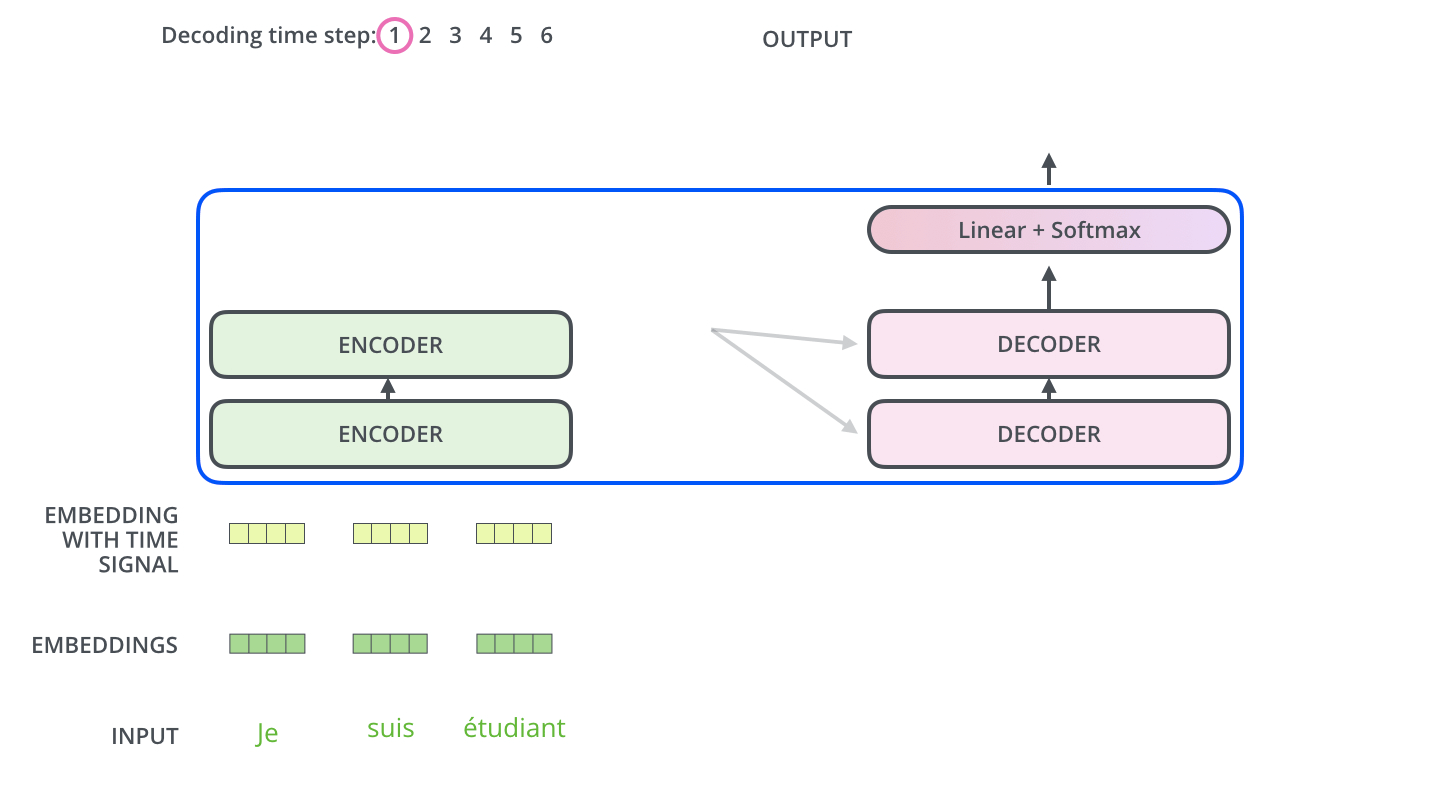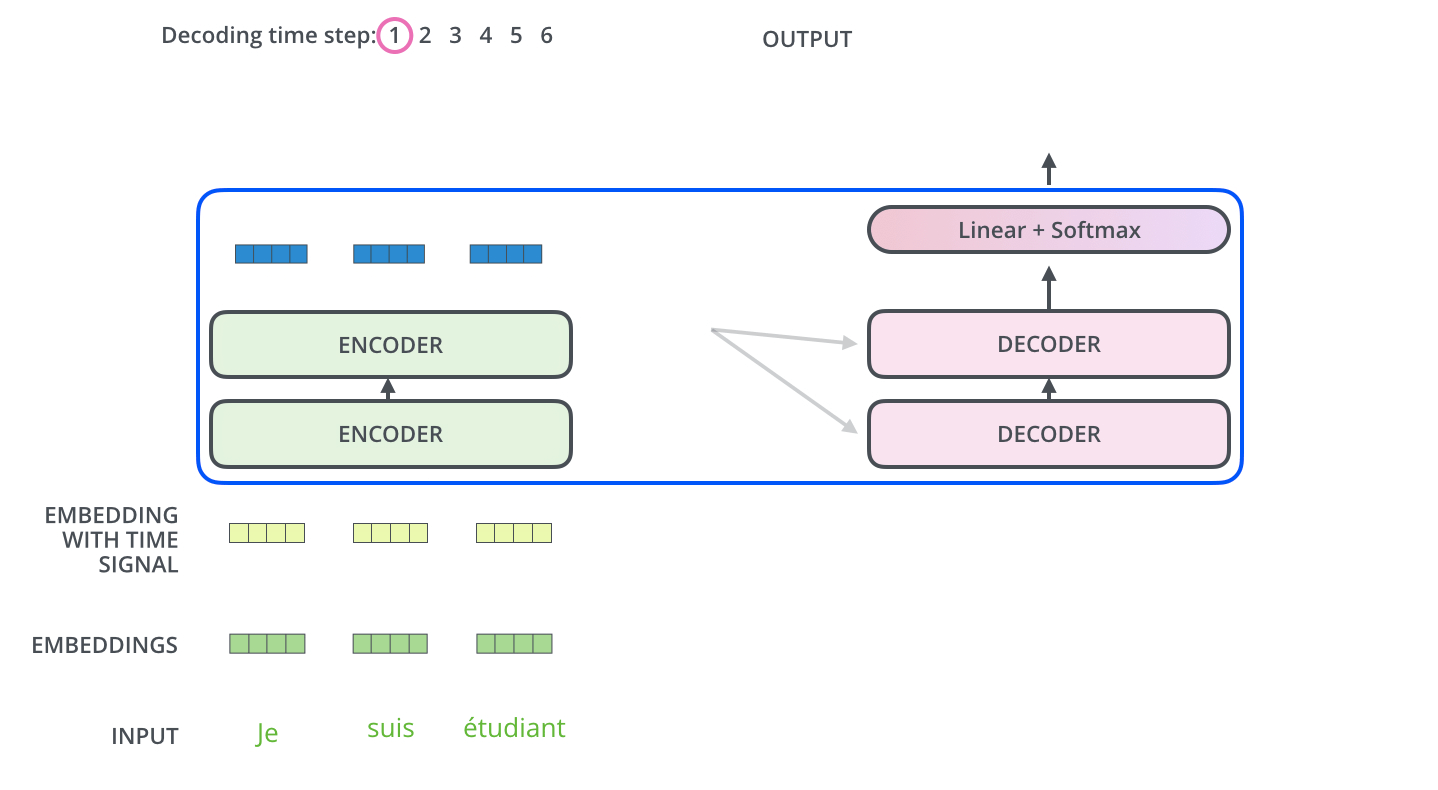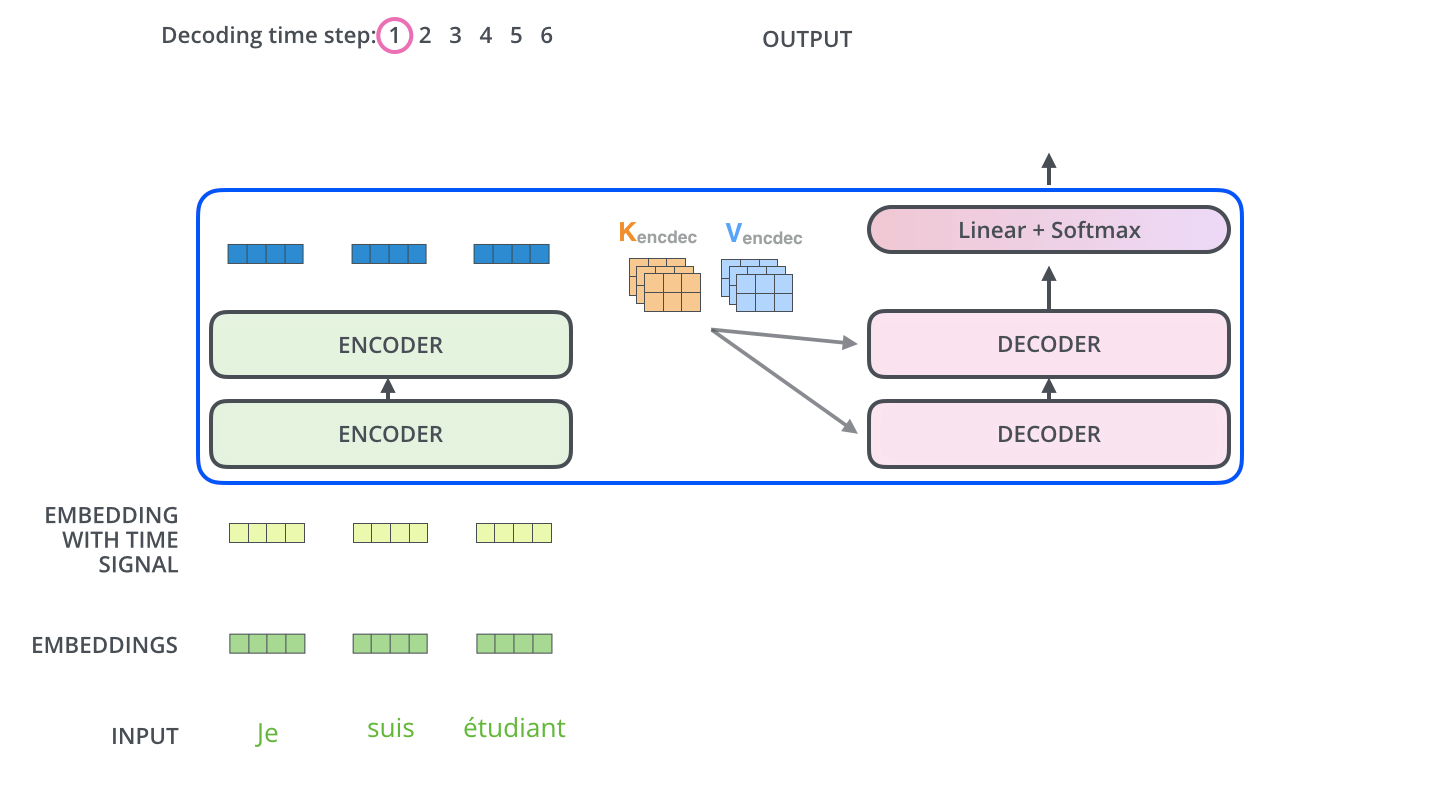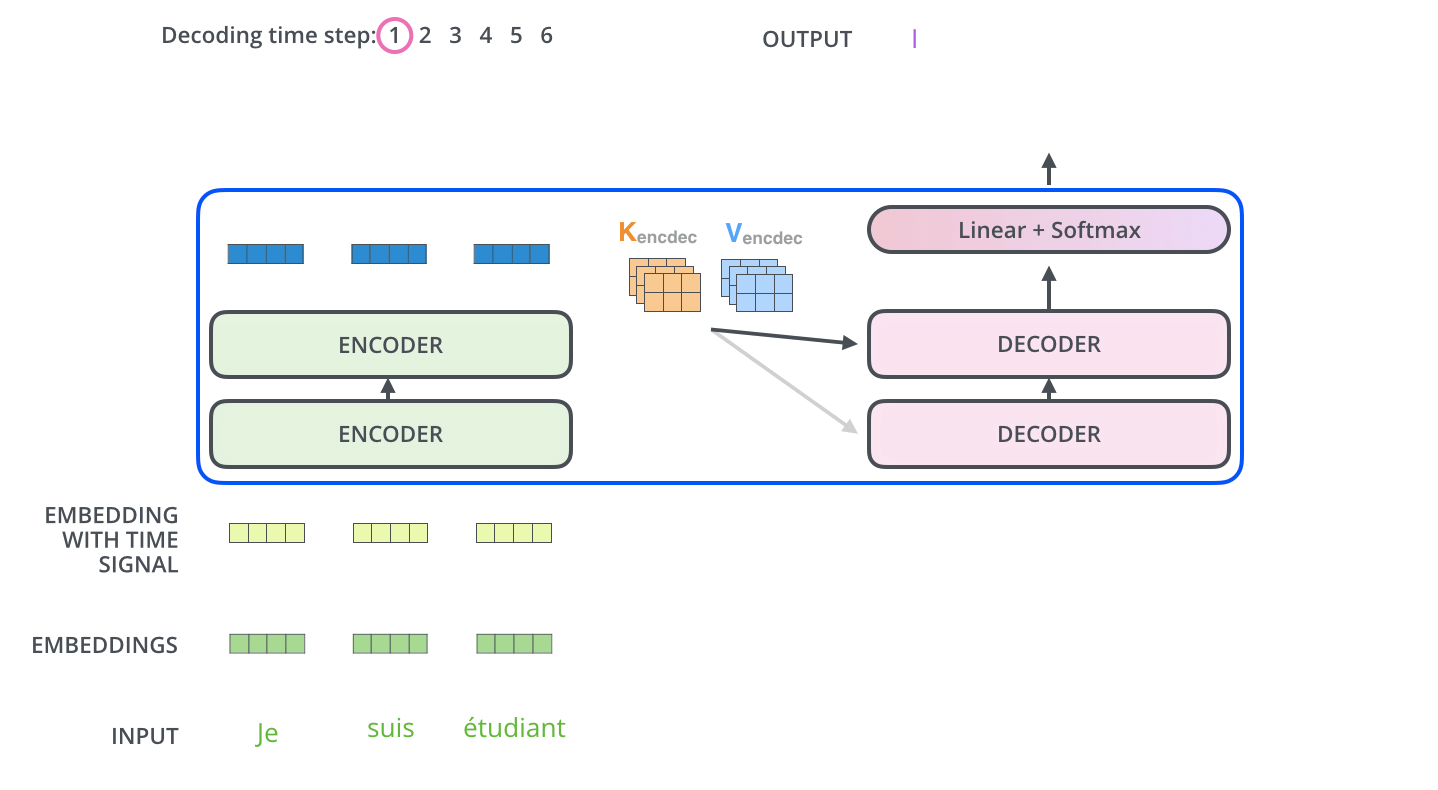
解码器在生成每个单词时,只能参考之前生成的单词,未来单词的信息会被遮蔽。这通过“遮盖机制”实现,确保模型不会看到将来要生成的单词。
解码器最终通过线性层和 Softmax 将输出转换为概率,选出最可能的词汇。
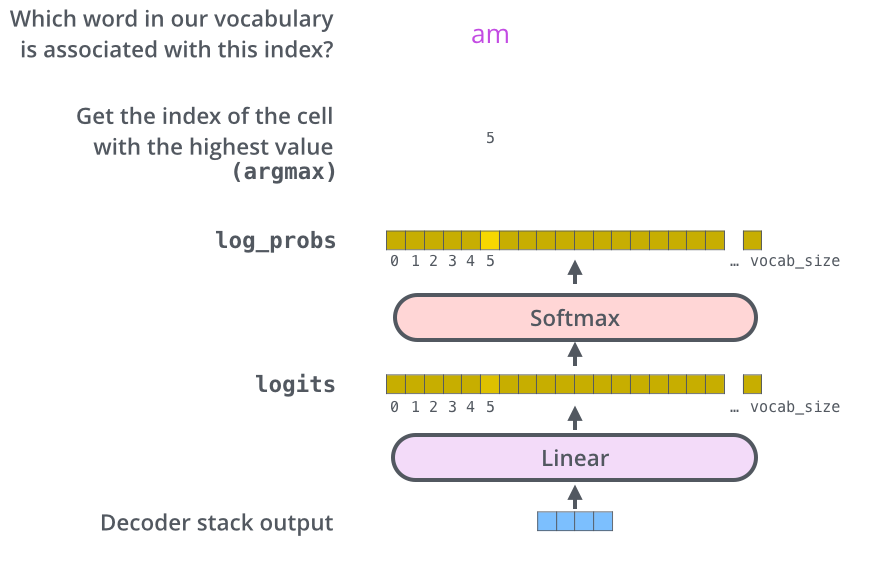
最后,我们再来看下论文中所绘制的 Transformer 整体模型架构。 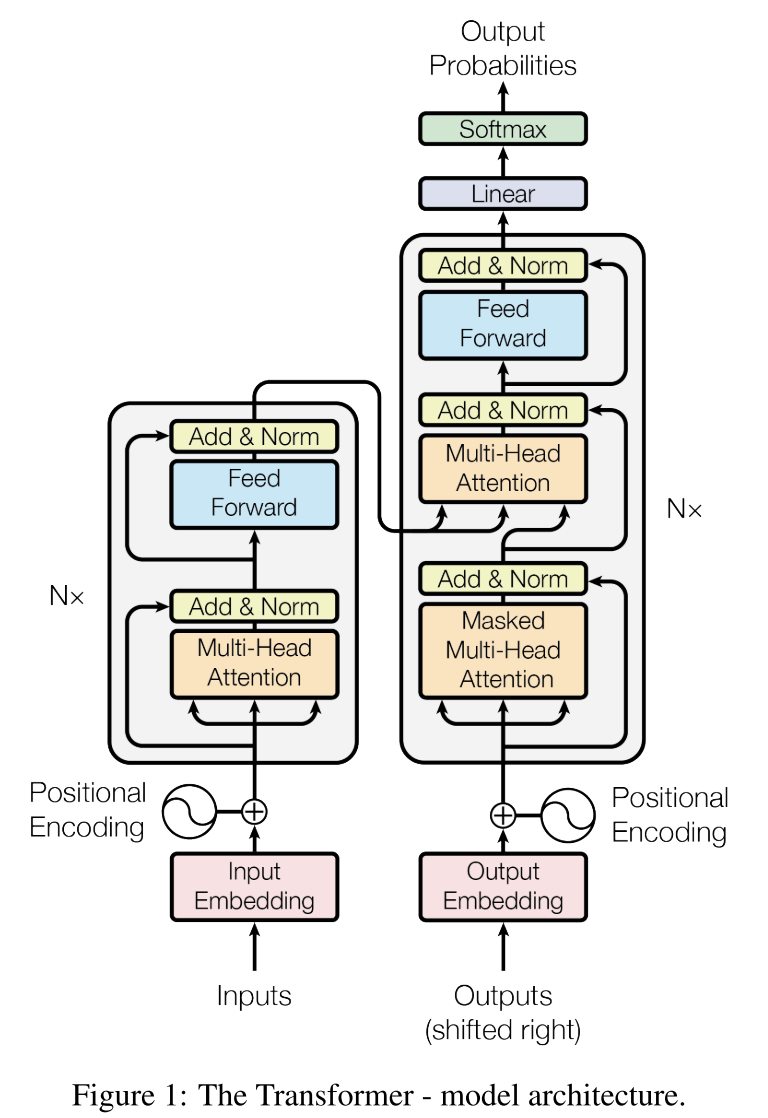
模型算力需求
训练 Transformer 模型的算力需求可以用以下公式估算:
C ≈ τT = 6PD |
- C 是总计算量,单位为 FLOPs。
- P 是模型参数数量。
- D 是数据集的大小(tokens 数量)。
- τ 是硬件的总计算能力(如 GPU 数量和 FLOPs)。
- T 是训练时间(秒)。
这些公式来源于 OpenAI’s scaling laws 和 DeepMind’s scaling laws。
模型显存需求
模型权重
Transformer 模型大多使用混合精度训练(fp16 + fp32 或 bf16 + fp32),这可以有效减少显存占用。
每个参数所需内存如下:
- int8:1 字节/参数
- fp16 和 bf16:2 字节/参数
- fp32:4 字节/参数
通常还会有约 20% 的额外开销。
推理显存估算
推理时所需内存大约为:
Total Memory(Inference) ≈ 1.2 × Model Memory |
训练显存估算
训练过程中所需的显存主要由以下部分组成:
- 模型内存:fp32 模型需要 4 字节/参数,fp16 模型需要 2 字节/参数。
- 优化器内存:AdamW 优化器通常需要 12 字节/参数,而使用像 bitsandbytes 的 8 位优化器可以将内存降至 6 字节/参数。
- 梯度内存:fp32 梯度需要 4 字节/参数,fp16 梯度则为 2 字节/参数。
- 激活内存:激活重计算可以减少内存开销,公式如下:

总的来说,训练所需显存为:
Total Memory(Training) = Model Memory + Optimizer Memory + Gradient Memory + Activation Memory |