本文介绍的内容仅供学习和娱乐使用,不建议使用在生产环节
前言
偶然间,我读到了一篇名为《LLM4Decompile: Decompiling Binary Code with Large Language Models》的论文,介绍了如何使用大型语言模型(LLM)对二进制程序进行反编译。受此启发,我进行了一个简单的实验,复现了整个反编译过程。
使用 LLM 反编译 Hello World 程序
实验选取了 C++语言编写的 Hello World。大体流程如下: 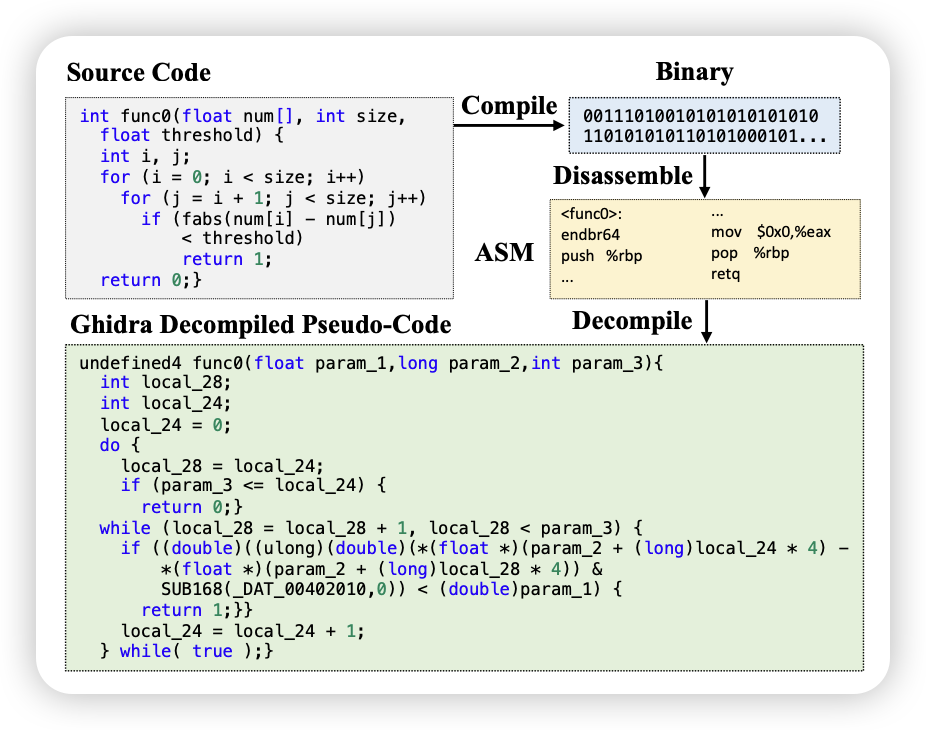
1.创建 helloworld.cpp 文件
|
2.编译程序并运行
g++ helloworld.cpp -o helloworld |
3.反编译得到汇编代码 这里选用的是 objdump 工具
objdump -d -M intel helloworld > helloworld.asm |
4.将得到汇编代码贴入 ChatGPT 中,并给出提示词
把下面的汇编还原成C++代码: |
下面是 ChatGPT 的返回: 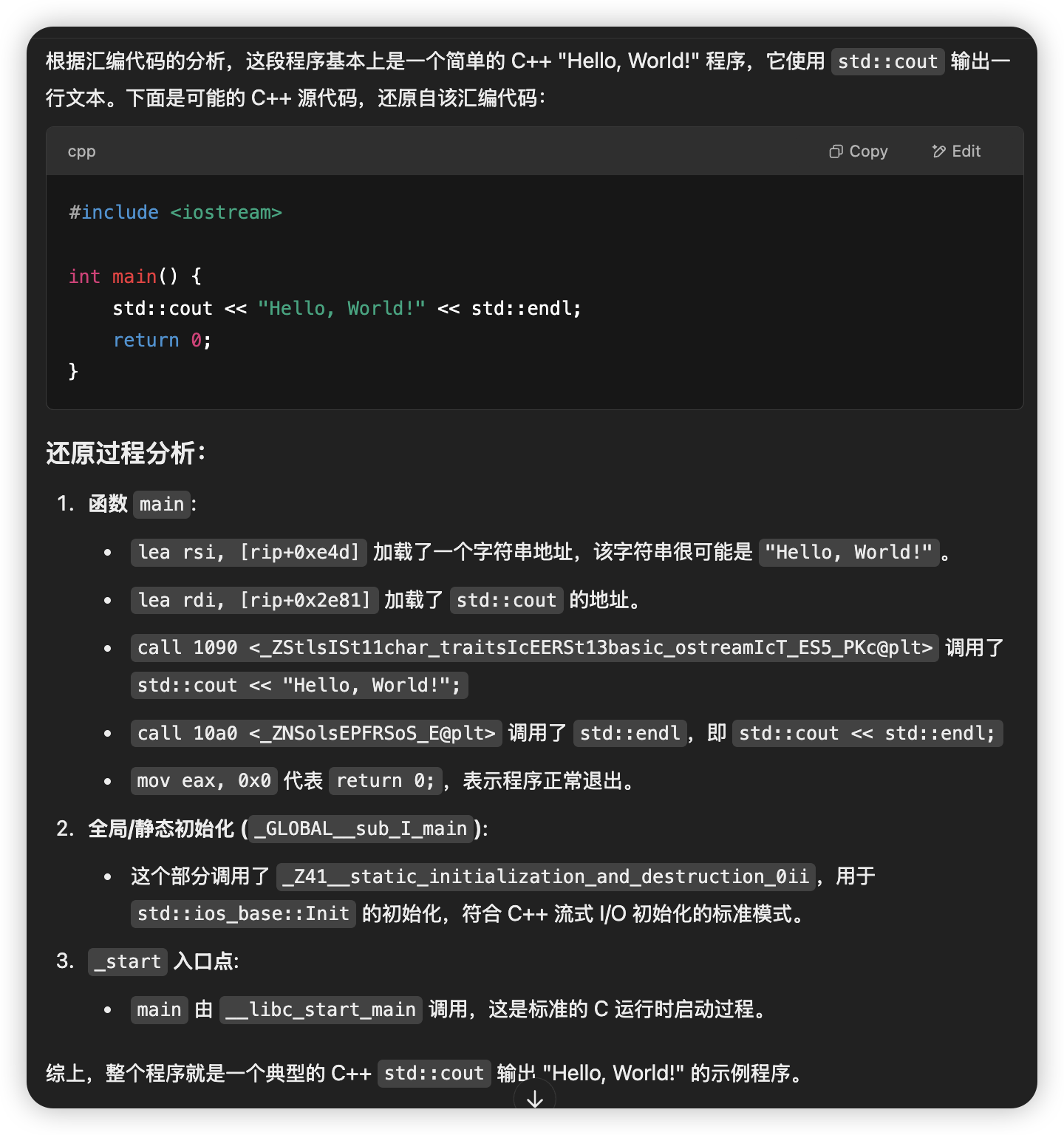
总结
尽管这个文本反编译程序相对简单,实验过程也不够严谨,但它确实简单地证明了 LLM 反编译代码的可行性。这启发了我们一些其他的思路,例如格式化混淆后的 JavaScript 文件、处理反编译后的 JAR 文件等等。