概述
SGLang 是一款面向大语言模型(LLM)和视觉语言模型(VLM)的高性能推理框架,通过精心设计的后端运行时与前端语言协同工作,使模型交互更加高效且可控。其核心优势包括:
- 高效后端运行时:采用创新的 RadixAttention 技术实现前缀缓存,支持跳跃式受限解码、零开销 CPU 调度、连续批处理、令牌注意力(分页注意力)、张量并行、FlashInfer 内核、分块预填充以及多种量化技术(FP8/INT4/AWQ/GPTQ),显著提升推理效率。
- 灵活前端语言:提供直观且强大的 LLM 编程接口,支持链式生成调用、高级提示工程、复杂控制流、多模态输入、并行处理及外部系统交互。
- 广泛模型兼容性:支持多种主流生成式模型(Llama、Gemma、Mistral、QWen、DeepSeek、LLaVA 等)、嵌入模型(e5-mistral、gte)及奖励模型(Skywork),并提供简便的新模型扩展机制。
- 活跃开源生态:拥有蓬勃发展的社区支持,已获得广泛业界认可(截至 2025 年 3 月 17 日,GitHub 累计星标超过 12,000)。
SGLang 发展势头迅猛,本文基于论文《SGLang: Efficient Execution of Structured Language Model Programs》的内容,结合个人理解进行系统梳理。
整体架构
SGLang 的架构由两大核心部分组成:前端 SGLang Client 和后端 SGLang Runtime。

前端 SGLang Client
前端可视为一种专为 LLM 应用程序设计的领域特定语言(DSL),通过后端 SGLRuntime 执行实际的计算任务。

后端 SGLang Runtime
SGLang Runtime 类似于 vLLM,是一个集成了推理请求调度、KVCache 管理和 GPU 推理优化的全栈后端引擎。其核心技术亮点包括:
- RadixAttention:基于高效前缀缓存的注意力机制,优化 KVCache 访问模式,显著提升长序列推理速度,同时减少显存占用。
- Fast Constrained Decoding:革新性的受限解码加速技术,支持跳跃式推理(Jump-forward Decoding),减少冗余计算,提高生成效率,特别适合对输出格式有严格要求的应用场景。
- API Speculative Execution:通过先进的推测执行(Speculative Decoding)技术,预计算多个可能的解码路径,结合主模型高效验证,大幅减少推理时间,加快响应速度。
核心技术
RadixAttention
SGLang 通过创新的 RadixAttention 实现高效的 Prefix Caching,其关键实现要点如下:
- 智能缓存保留:每次请求完成后,当前请求的 KV Cache 不会立即释放,而是通过 RadixAttention 算法精心保留在 GPU 显存中。同时,RadixAttention 将序列 token 与 KV Cache 之间的映射关系存储在专用的 RadixTree 数据结构中。
- 高效缓存命中:新请求到达时,SGLang 调度器利用 RadixTree 执行前缀匹配算法,快速判断新请求是否能够复用已有缓存。一旦命中,调度器立即复用现有 KV Cache 处理该请求,显著减少计算开销。
- 智能缓存管理:考虑到 GPU 显存资源有限,缓存中的 KV Cache 需要合理管理。RadixAttention 采用经典的 LRU(Least Recently Used,最近最少使用)策略进行缓存淘汰,这一机制与操作系统内存管理中的页面置换算法相似,确保最有价值的缓存得到保留。
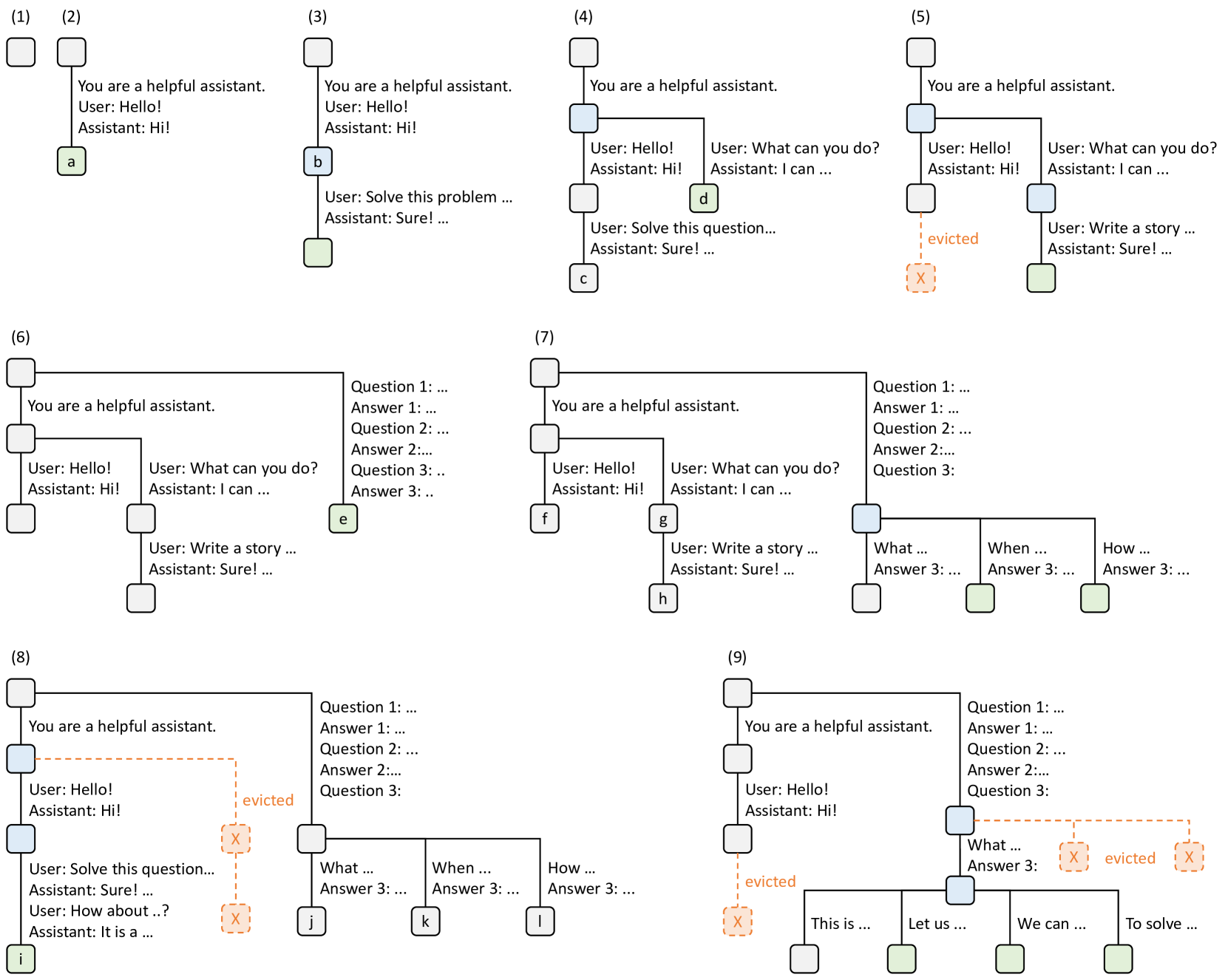
图例详解
- 节点颜色代表状态:
- 绿色:新加入的节点
- 蓝色:当前时间点正在访问的缓存节点
- 红色:根据 LRU 策略被淘汰的节点
- 边:表示子字符串或一系列 Token 序列
- 树结构:展示请求间的共享路径和分支操作
RadixTree 演变过程详解
- 步骤 (1):
- 初始状态:系统启动时 Radix 树为空
- 步骤 (2):
- 首次交互:用户发送消息 "Hello!"
- 系统响应:"Hi!"
- 结果:系统将完整对话(系统提示词 "You are a helpful assistant."、用户消息 "Hello!" 和助手回复 "Hi!")作为新节点(a)添加到树中
- 步骤 (3):
- 后续请求:系统接收到新的问题求解请求
- 前缀复用:系统识别并复用树中已有的前缀(第一轮对话的 KV Cache)
- 增量更新:将新一轮对话("Solve this problem...")附加为树中的新节点(b)
- 步骤 (4):
- 多会话管理:启动第二个独立聊天会话
- 智能节点拆分:系统将节点(b)拆分为两个节点,实现两个会话间系统提示词的高效共享
- 结构优化:添加新节点(c)和(d),形成分支结构
- 步骤 (5):
- 第二会话继续:用户请求 "Write a story"
- 资源管理:由于内存限制触发,系统根据 LRU 策略淘汰节点(c)
- 状态更新:新对话轮次附加在节点(d)之后
- 步骤 (6):
- 少样本学习请求:系统接收包含多个示例的复杂查询
- 结构调整:由于新请求与现有节点不共享前缀,系统执行根节点拆分
- 扩展操作:添加新节点(e)处理独立请求路径
- 步骤 (7):
- 批量少样本处理:系统接收多个包含相同少样本示例的查询
- 高效共享:将节点(e)智能拆分以实现少样本示例的共享
- 多分支创建:添加新节点(f)、(g)和(h)形成复杂树结构
- 步骤 (8):
- 会话连续性:系统接收第一个聊天会话的后续消息
- 动态资源调整:根据 LRU 策略,淘汰最近最少使用的第二个聊天会话相关节点(g)和(h)
- 状态更新:添加新节点(i)继续第一会话
- 步骤 (9):
- 高级采样功能:系统接收针对节点(j)中问题的多样化采样请求(如生成多个备选答案)
- 资源再平衡:为新任务腾出空间,系统淘汰节点(i)、(k)和(l)
- 功能扩展:树结构中新增专用于采样的分支路径
Fast Constrained Decoding
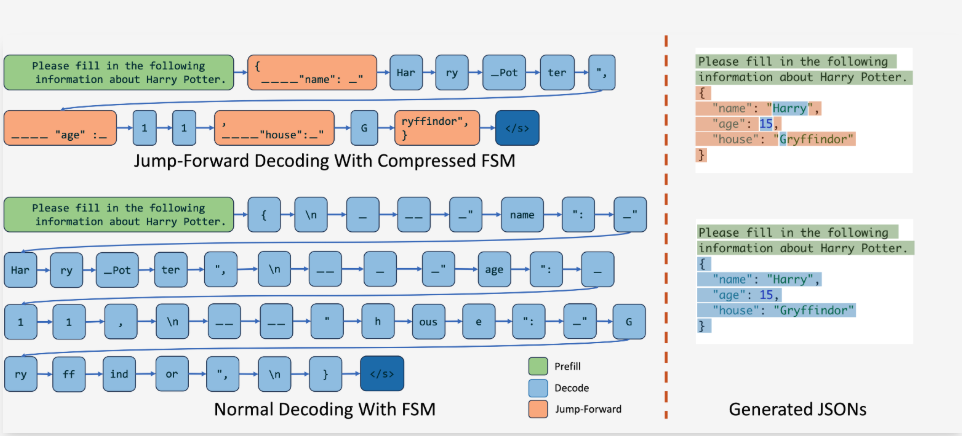
SGLang 创新性地提出了基于压缩有限状态机的跳跃式解码方法(Jump-Forward Decoding With a Compressed Finite State Machine),相比传统 FSM 实现,通过智能状态压缩和无效状态合并,实现了显著的性能提升。
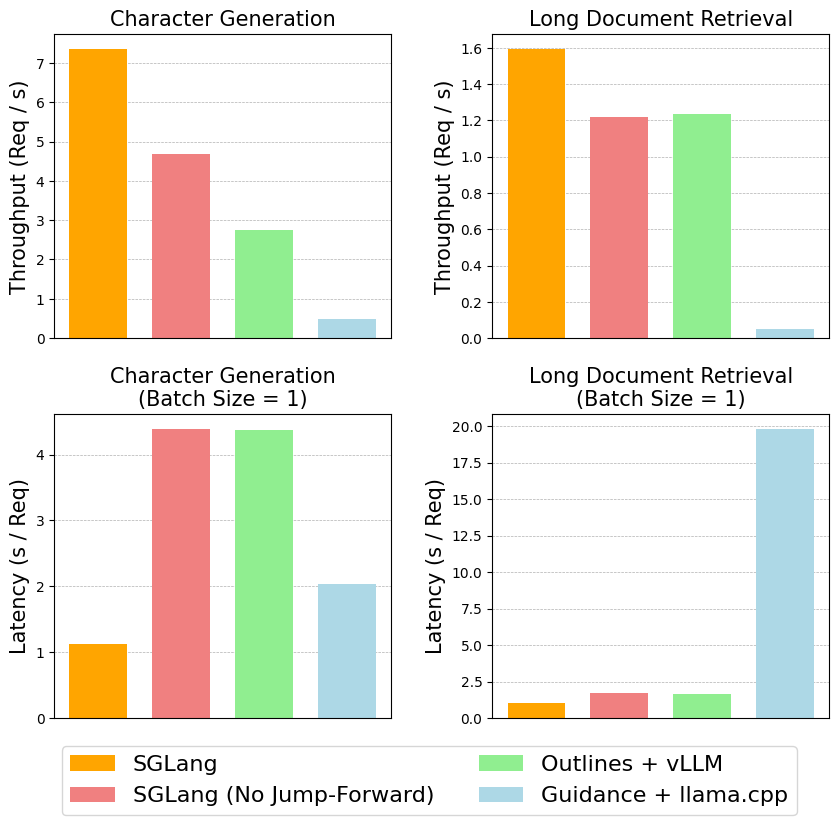
实验结果表明,SGLang 在受限解码任务上比 Outlines+vllm 和 Guidance+llama.cpp 速度提升了约 2.5 倍,展现出卓越的性能优势。
API Speculative Execution
SGLang 引入了创新的推测执行(speculative
execution)优化技术,有效减少 API
调用次数。例如,当程序需要模型生成角色描述时,通常采用多次调用模式:
s += context + "name:" + gen("name", stop="\n") + "job:" + gen("job", stop="\n")
在传统方法中,两个 gen 语句对应两次独立 API
调用,用户需要为上下文的输入 token 费用重复支付。
SGLang 的推测执行机制在首次调用时会智能地忽略停止条件,继续生成额外的 token。解释器会巧妙保留这些预生成的输出,并在后续调用中进行精确匹配和复用。通过精心设计的提示工程(prompt engineering),模型能够高概率地符合预期模板,从而节省后续 API 调用的延迟和输入成本,显著提升整体性能和经济性。
总结
SGLang 作为一个极具潜力的新一代推理引擎,由来自 UC Berkeley 的顶尖研究团队开发,展现出卓越的技术实力。相比 vLLM 目前较为庞大的代码库,SGLang 的实现更为简洁、优雅且易于扩展,非常适合企业进行深度定制和二次开发。
不过,值得一提的是,虽然其后端技术令人印象深刻,但前端的 DSL 设计仍有提升空间。要完全替代 LangChain 等成熟的 Agent 框架,SGLang 的 DSL 还需要进一步丰富功能和提升易用性。随着社区的不断壮大和技术的持续迭代,SGLang 有望在未来成为 LLM 推理领域的重要力量。