本文将从 AI 芯片的基础知识和 GPU 的基本概念入手,详细介绍 NVIDIA GPU 的工作原理和核心架构,最后深入探讨 NVIDIA GPU 从 Fermi 架构到 Hopper 架构的演进历史。通过这篇文章,您将全面了解 GPU 的基本功能、NVIDIA 的技术创新以及各代架构的显著特点和改进。这将帮助您更好地理解 GPU 在现代计算中的重要性,以及 NVIDIA 在推动图形处理和并行计算领域进步方面的关键作用。
AI 芯片基础
AI 芯片分类
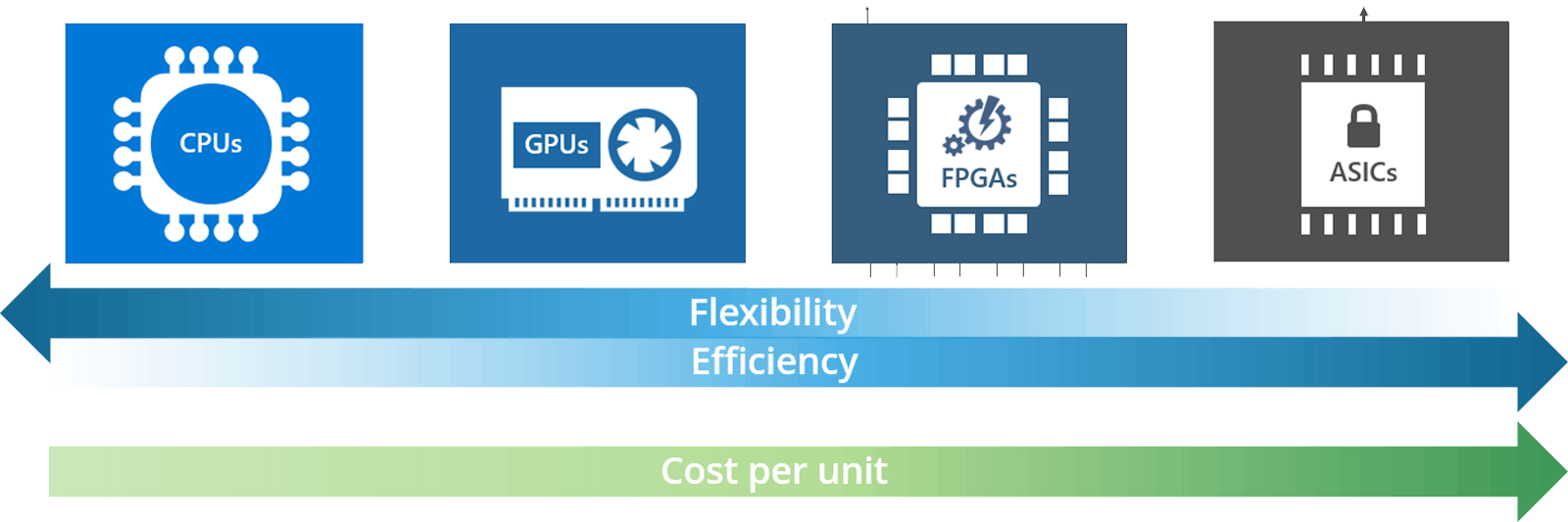
AI 芯片是专为人工智能应用设计的,GPU 是其中一种。按技术架构分为:
CPU:基于冯诺依曼架构的处理器,擅长逻辑控制和串行计算,但在复杂算法和并行操作方面较弱。
GPU(图形处理单元):最初用于图像处理。与 CPU 相比,GPU 在并行计算上具有显著优势,但无法独立工作,需要 CPU 控制,且功耗较高。
FPGA(现场可编程门阵列):用户可以通过更新配置文件自定义内部电路连接,具有硬件流水线并行和数据并行处理能力,适合深度学习推理阶段。
ASIC(专用集成电路):为特定需求设计和制造,具有更高的处理速度和更低的能耗,但研发周期长、成本高。神经网络处理单元(NPU)和 Tensor 处理单元(TPU)是典型的 ASIC 芯片。
数据位宽
在计算机科学中,整数和浮点数是两种基本的数据类型,可以用不同长度的比特表示,比特位宽决定了它们的表示范围和数据精度。
整数类型表示
有符号整数
有符号整数通常使用二进制补码表示,最高位为符号位,0 表示正数,1 表示负数。例如,32 位补码表示的 -5:
- 取绝对值 5 的二进制表示:0000 0000 0000 0000 0000 0000 0000 0101
- 逐位取反:1111 1111 1111 1111 1111 1111 1111 1010
- 加 1:1111 1111 1111 1111 1111 1111 1111 1011
无符号整数
无符号整数直接使用二进制表示法,不涉及符号位。32 位无符号整数的表示范围为 0 到 4294967295。
浮点数表示
浮点数通常采用 IEEE 754 标准。常见的有单精度和双精度浮点数。
单精度浮点数(32 位)
1 位符号位、8 位指数位(偏移量 127)、23 位尾数位。例如,-5.75 的单精度表示:
- 二进制表示:-101.11
- 规范化:-1.0111 × 2^2
- 符号位 S = 1
- 指数位 E = 2 + 127 = 129,二进制为 1000 0001
- 尾数位 M = 0111 0000 0000 0000 0000 000
双精度浮点数(64 位)
1 位符号位、11 位指数位(偏移量 1023)、52 位尾数位。例如,-5.75 的双精度表示:
- 二进制表示:-101.11
- 规范化:-1.0111 × 2^2
- 符号位 S = 1
- 指数位 E = 2 + 1023 = 1025,二进制为 100 0000 0001
- 尾数位 M = 0111 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
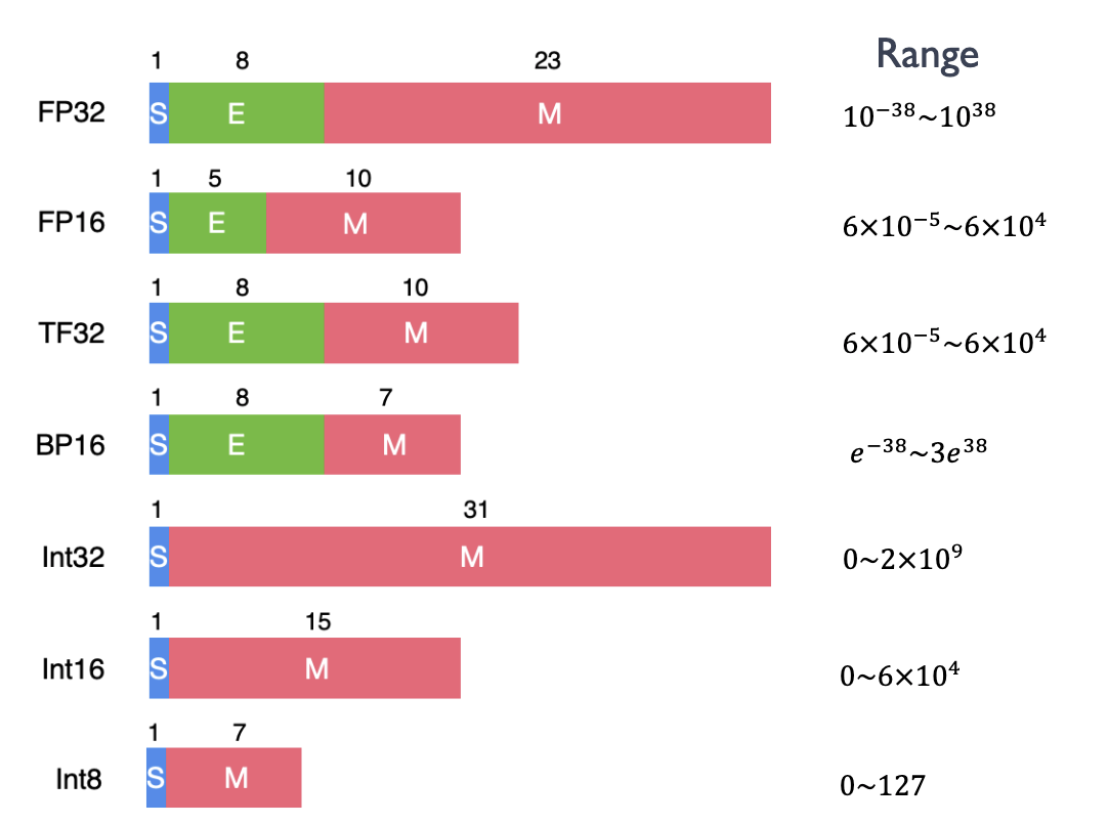
AI 数据类型
FP32: 单精度浮点数格式,常用于深度学习训练和推理。每个 FP32 数据占用 4 个字节。
TF32: 由 NVIDIA 在 A100 GPU 中引入的新数据类型,减少了 FP32 的小数部分精度位宽,提高计算速度。
FP16: 半精度浮点格式,广泛用于混合精度训练,提高计算效率。
BF16: 由 Google 开发的 16 位浮点格式,解决了 FP16 动态范围窄的问题,常用于大模型训练和微调。
FP8: 由 NVIDIA 在 H100 GPU 中引入的 8 位宽浮点数据类型,显著节省内存并提升吞吐量,适用于大型语言模型(LLM)。
Int: 整数数据类型,常用于特定 AI 模型应用场景,如 Int8 可有效提升计算效率并节省资源。
AI 芯片性能
衡量指标
衡量芯片性能的主要指标包括:
- 算力(Performance):衡量芯片处理能力的指标,算力越高,芯片执行任务的速度越快。
- OPS:每秒操作数。1 TOPS 代表处理器每秒进行一万亿次计算。
- OPS/W:每瓦特的运行性能。
- FLOPs:浮点运算次数,用来衡量模型计算复杂度。
- MACs:乘加累计操作,1 MACs 包含一个乘法操作与一个加法操作。
- MAC:内存占用量,用来衡量模型在运行时的内存占用情况。
- 功耗(Power):指芯片在执行任务时消耗的能量。低功耗对于移动设备和节能要求高的环境尤为重要。
- 面积(Area):芯片的物理大小。小型化的芯片通常可以提供更高的集成度和更好的性能。
- 吞吐量和时延:吞吐量指芯片在处理多个任务时的能力,而时延是芯片完成单个任务所需的时间。这两个指标决定了芯片在实际应用中的效率和响应速度。
- 精度:指芯片执行计算任务时的准确度。
- 可扩展性与灵活适用性:表示芯片的设计是否可以轻松扩展到不同的应用场景,并适应不断变化的需求。
屋顶线性模型(Roofline Model)
Roofline Model 提出了使用计算强度进行定量分析的方法,给出了模型在计算硬件上所能达到的理论计算性能上限公式。
计算硬件的两个指标:算力与带宽
- 算力:计算硬件的性能上限,指的是每秒钟所能完成的浮点运算数。
- 带宽:计算硬件的带宽上限,指的是每秒所能完成的内存交换量。
- 计算强度上限:算力与带宽的比值,描述单位内存交换最多进行的计算次数。
模型的两个指标:计算量与访存量
- 计算量:输入单个样本进行前向传播所需的浮点运算次数。
- 访存量:输入单个样本进行前向传播过程中发生的内存交换总量。
- 模型的计算强度:计算量除以访存量,表示每 Byte 内存交换用于的浮点运算次数。
- 模型的理论性能:模型在计算平台上所能达到的每秒浮点运算次数。
Roofline Model
Roofline Model 用于解决“计算量为 A 且访存量为 B 的模型在算力为 C 且带宽为 D 的计算硬件所能达到的理论性能上限 E 是多少”这个问题。模型如下图所示:
- 算力决定屋顶的高度。
- 带宽决定房檐的斜率。
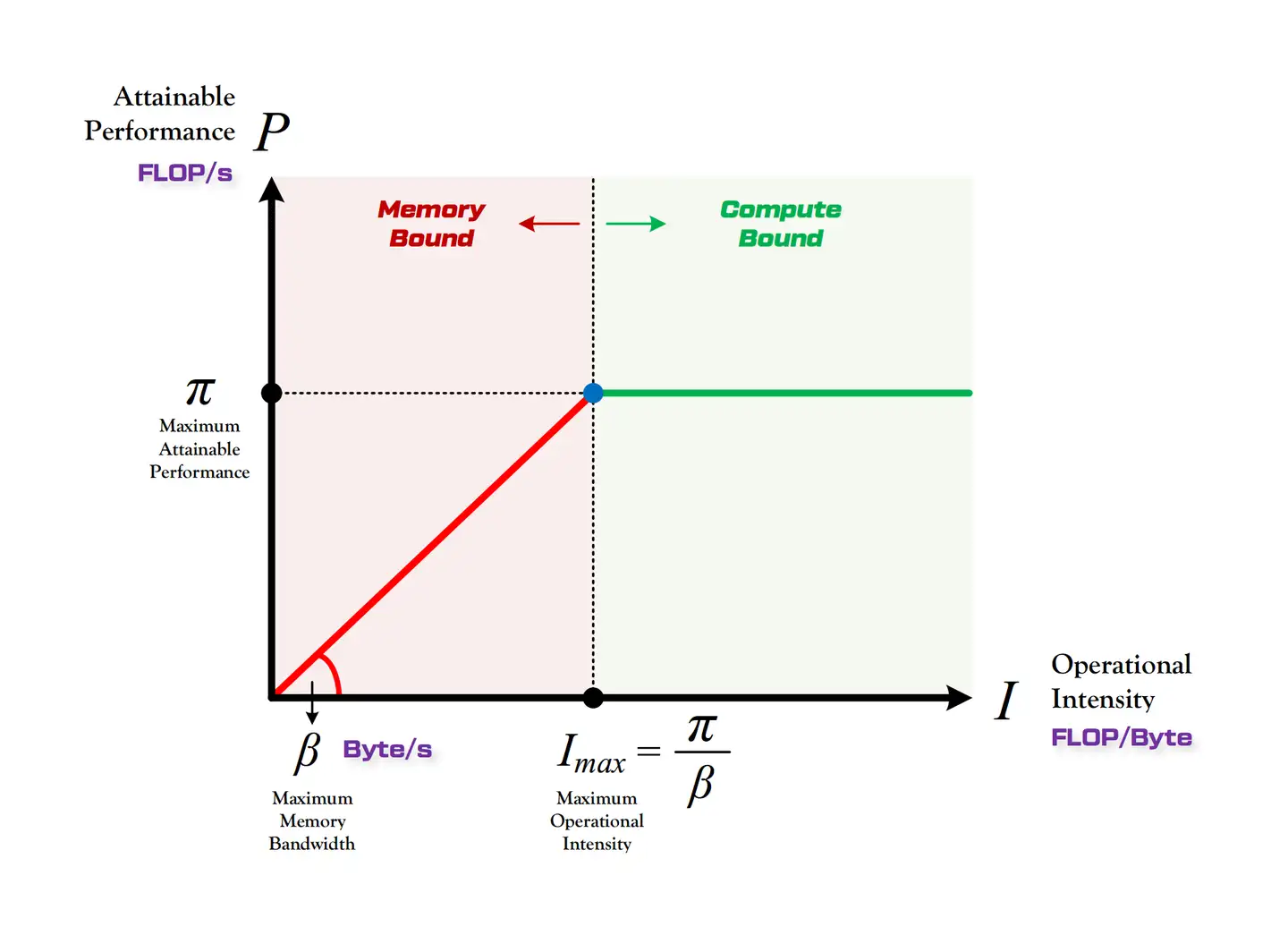
Roofline Model 划分出两个瓶颈区域:
- 计算瓶颈区域(Compute-Bound):理论性能最大只能等于计算平台的算力。
- 带宽瓶颈区域(Memory-Bound):理论性能由计算平台的带宽上限和模型的计算强度决定。
CPU VS GPU
在开始讨论 NVIDIA GPU 的详细内容之前,首先明确什么是 GPU,以及 GPU 和 CPU 的主要区别是什么。
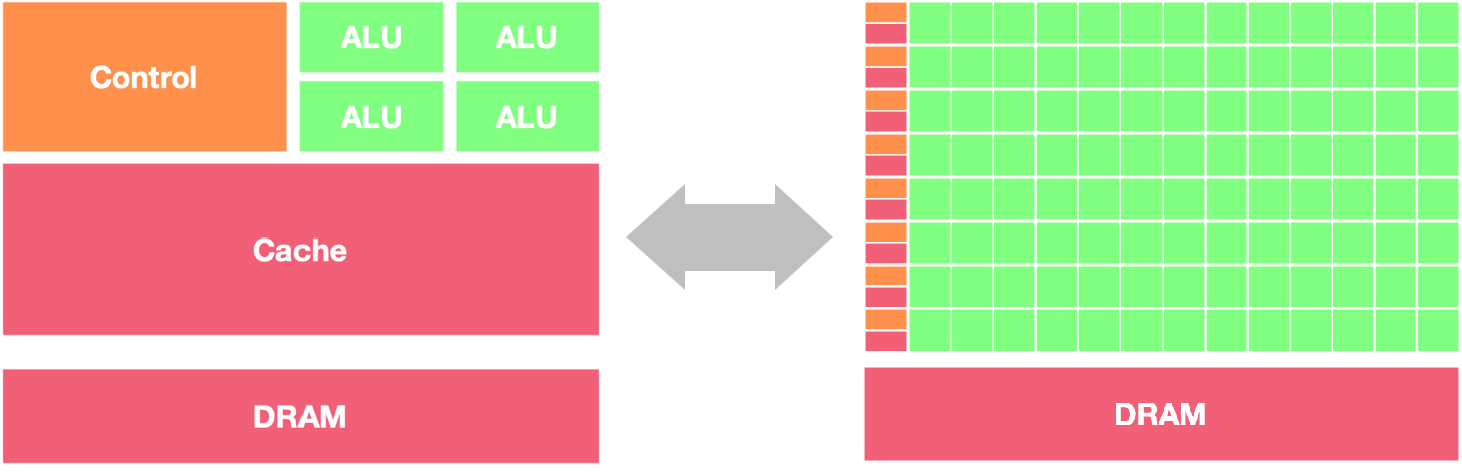
CPU 和 GPU 在架构方面的主要区别包括以下几点:
- 核心数量与结构:
- CPU: 通常具有较少的核心数(通常是 2 到 16 个核心,高端服务器 CPU 可能有几十个核心)。每个核心的设计更加复杂,拥有强大的单线程性能和较大的缓存,适合处理复杂的指令序列和任务切换。
- GPU: 拥有大量的核心(通常是数百到几千个),每个核心相对简单,适合执行大规模并行计算任务。GPU 的核心设计更注重并行计算能力,而不是单线程性能。
- 并行处理能力:
- CPU: 适合处理顺序的、复杂的计算任务,擅长单线程性能。CPU 可以高效处理复杂的逻辑、分支预测和任务调度。
- GPU: 设计用于处理大量简单的、并行的计算任务,如图形渲染和矩阵运算。GPU 的架构使其在处理大规模并行计算时具有显著优势,例如图形处理和深度学习。
- 缓存结构:
- CPU: 拥有多层次的缓存结构(L1、L2、L3 缓存),每个核心都有较大的私有缓存,以减少内存访问延迟。缓存设计更加复杂,旨在提高指令和数据访问速度。
- GPU: 缓存结构相对简单,主要依赖共享内存和寄存器来提高数据访问速度。GPU 的设计更加关注带宽和延迟的平衡,以支持高效的并行处理。
- 内存架构:
- CPU: 采用统一的内存架构,内存访问速度较高,延迟较低。CPU 与系统内存直接通信,适合处理需要频繁内存访问的任务。
- GPU: 通常具有专用的高带宽显存(如 GDDR5、GDDR6),与 CPU 系统内存分开。显存设计用于高吞吐量任务,如图形渲染和数据并行计算。
- 指令集和执行单元:
- CPU: 拥有复杂的指令集,支持多种操作,包括分支、跳转和复杂的算术运算。CPU 的执行单元复杂,支持多种任务类型。
- GPU: 指令集较为简单,主要针对并行计算和图形处理优化。执行单元设计为处理大量简单的算术运算,适合大规模数据并行处理。
GPU 基础概念
让我们先从 NVIDIA H100 的硬件架构入手,介绍 GPU 的一些基础概念。下图是 NVIDIA H100 的整体硬件架构图:
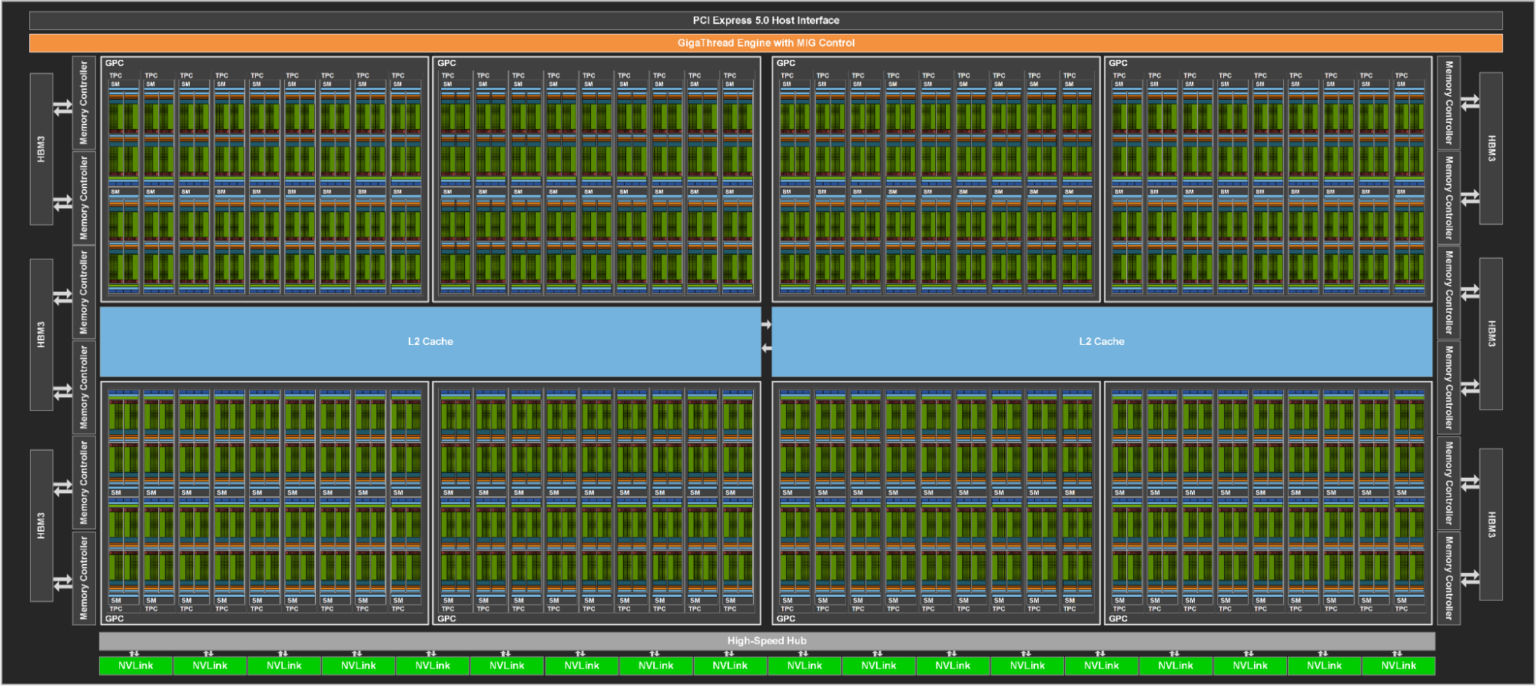
GPC(Graphics Processing Clusters)
GPC 负责处理图形渲染和计算任务。每个 GPC 包含多个 TPC,以及与其相关的专用硬件单元和缓存。
TPC(Texture Processing Clusters)
TPC 负责执行纹理采样和滤波操作,以从纹理数据中获取采样值,并应用于图形渲染中的相应像素。在 CUDA 计算中,每个 TPC 有两个 SM 处理计算任务。
SM(Streaming Multiprocessor)
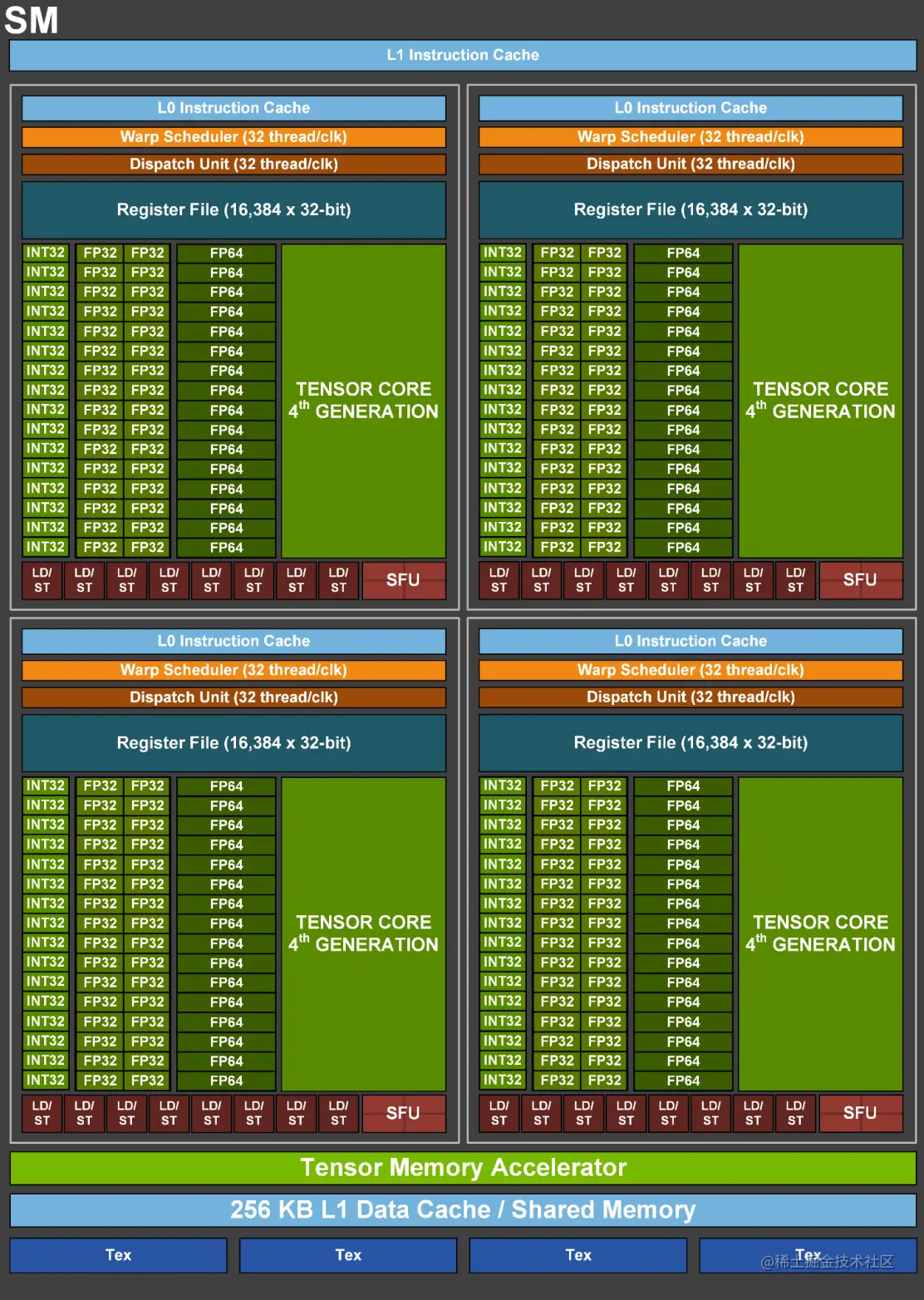
SM 是 GPU 的主要计算单元,负责执行并行计算任务。每个 SM 包含多个 CUDA 核心,可以同时执行多个线程块中的指令。SM 通过分配线程、调度指令和管理内存等操作,实现高效的并行计算。主要包括:
- L1 Cache/SMEM: L1 Cache 包含指令缓存和数据缓存,在 SM 内部存储最常用的指令和数据。每个 SM 独享一个 L1 Cache,提供低延迟和高带宽的访问。SMEM(共享内存)也集成在 SM 内,用于线程间的快速数据交换。
- WARP: WARP 指的是一组同时执行的线程。一个 Warp 包含 32 个并行线程,这 32 个线程以 SIMT(Single Instruction, Multiple Threads)模式执行同一条指令,但每个线程会使用各自的数据执行指令分支。
- Dispatch Unit: 从指令队列中获取和解码指令,协调指令的执行和调度,将其分派给适当的执行单元,以实现高效的并行计算。
- Register File: 用于存储临时数据、计算中间结果和变量,离计算单元最近,访问速度非常快。
- Tensor Core 和 Tensor Memory Accelerator: 主要用于加速 AI 计算负载中的矩阵乘法和累加(Matrix Multiply-Accumulate,MMA),显著提升深度学习和高性能计算的效率。
- Load/Store: 负责从和向内存读取和写入数据,确保数据在计算单元和存储单元之间的高效传输。
- SFU(Special Function Unit): 用于加速特定类型的计算操作,如三角函数、指数和对数等。
- Tex(Texture Unit): 纹理单元主要负责处理纹理的加载、采样、过滤等操作,用于图形渲染中对纹理的应用。这些单元可以在纹理数据中快速查找和过滤,从而加速图像渲染过程,提高渲染效率。
HBM(High-Bandwidth Memory)
HBM 是高带宽内存,也就是我们常说的显存。它通过将内存芯片直接堆叠在逻辑芯片上,提供了极高的带宽和更低的能耗,从而实现了高密度和高带宽的数据传输。
访问速度对比
通过上面的自顶向下分析,我们知道,对于 GPU 中的存储部分,访问速度由快到慢,计算部分从大到小排列为:
- 内存访问速度: L1 Cache/SMEM > L2 Cache > HBM
- 计算单元包含关系: GPC > TPC > SM > TensorCore, SFU, INT32, FP32...
计算强度
计算强度表示一段代码的计算时间复杂度与访存时间复杂度的比例。简单来讲,就是一个数据我访问一次需要做多少次运算。
对于 N 阶方阵的乘法操作,其计算时间复杂度为 O(N^3),访存时间复杂度为 O(N^2),其计算强度为 O(N)。
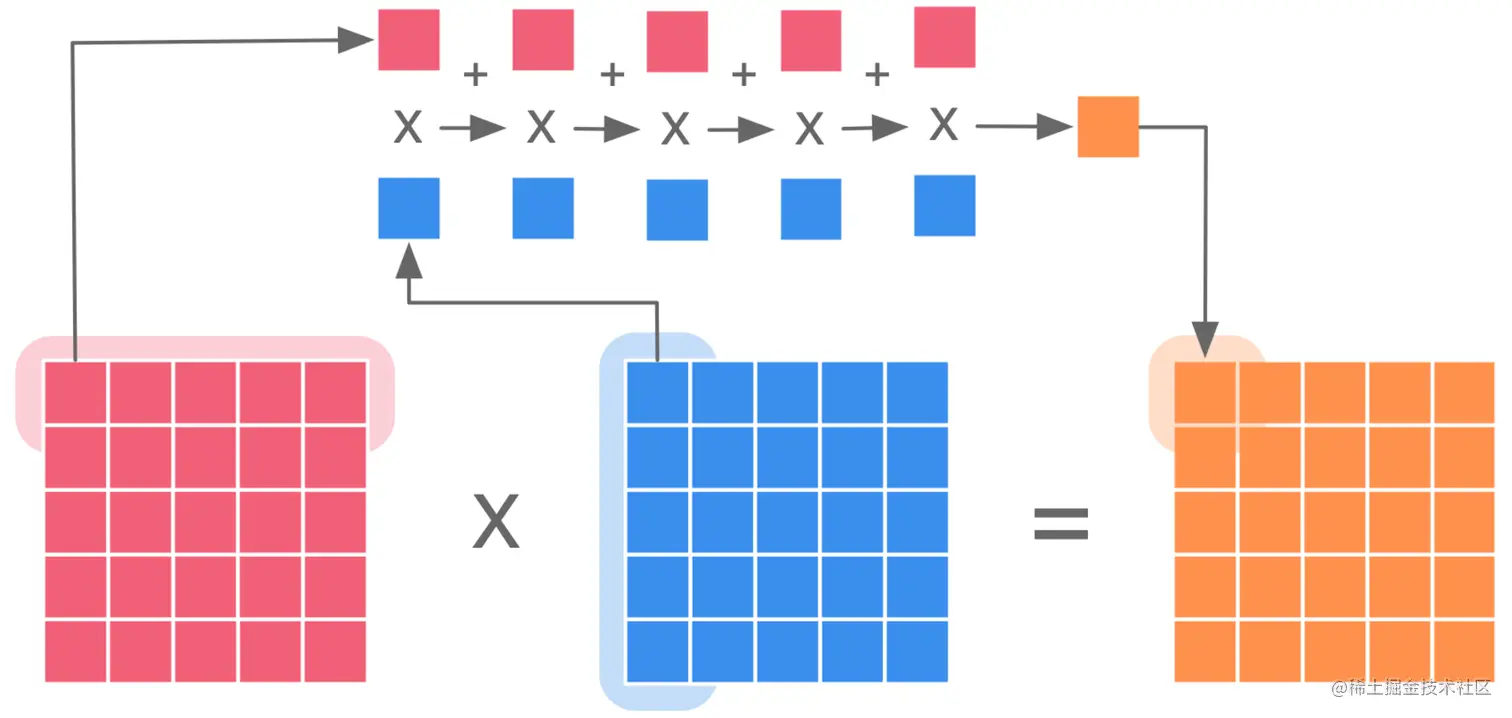

根据计算强度的定义可知,对于计算能力固定的一个设备,如果想让计算单元达到更高的利用率,则对于越慢的内存,我们需要算法的计算强度就越大,即访问一次内存,多进行几次运算。
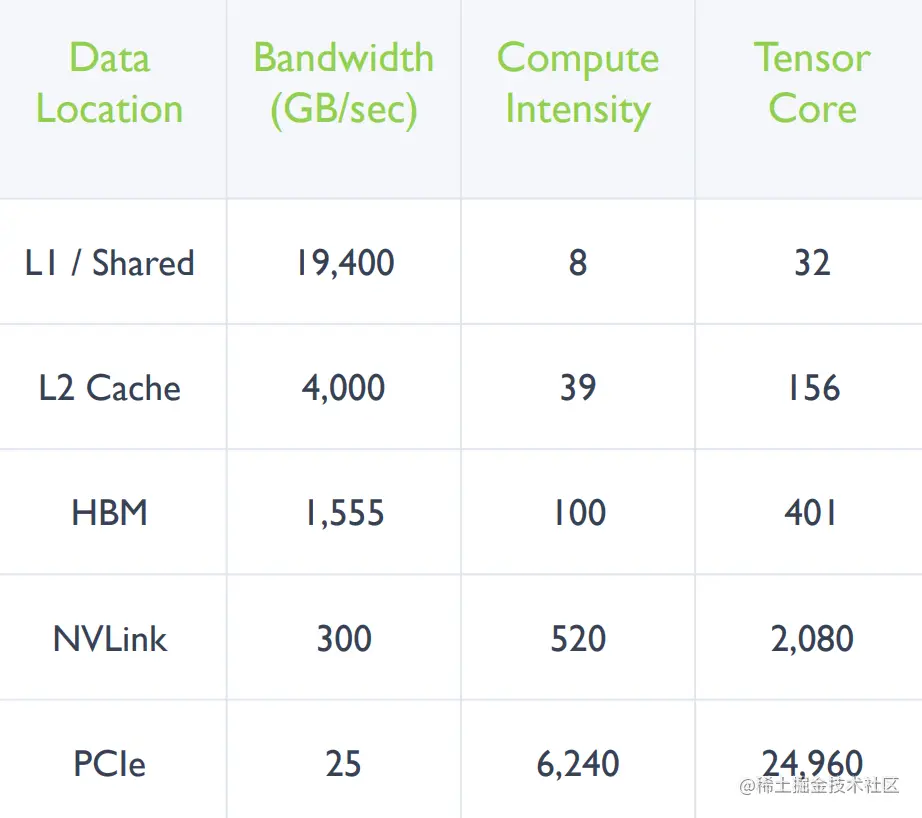
下图展示了当数据在 GPU 不同存储设备上时,计算单元达到最大利用率所需的计算强度。
GPU 工作原理
GPU 工作原理
GPU 的运行原理基于并行计算的思想,它可以同时执行大量的计算任务,从而提高计算效率。
在使用 GPU 进行计算时,我们需要将计算任务分解成多个线程,并将这些线程分配给 GPU 的处理器单元进行并发计算。GPU 的处理器单元可以同时处理多个线程,每个线程都可以独立地执行计算任务,从而实现高并发的计算。
同时,为了保证 GPU 的计算资源能够得到充分利用,我们还需要使用特殊的并行计算模型,如 CUDA(Compute Unified Device Architecture)等,来编写 GPU 计算所需要的程序。CUDA 提供了一系列的 API,可以让开发者在 GPU 上进行高效的并行计算,从而实现高效的数据处理和模型训练。
总的来说,GPU 的硬件组成和运行原理都是为了实现高效的并发计算和数据处理,从而提高计算效率和数据处理速度。随着深度学习和其他计算密集型应用的不断发展,GPU 的应用范围也越来越广泛,成为了现代计算机体系结构中不可或缺的一部分。
GPU 缓存机制
在 GPU 工作过程中,希望尽可能减少内存的时延、内存的搬运、还有内存的带宽等一系列内存相关的问题,其中缓存对于内存尤为重要。NVIDIA A100 内存结构中 HBM Memory 的大小是 80G,也就是 A100 的显存大小是 80G。
缓存的层次结构
下面以 NVIDIA A100 为例介绍缓存的层次结构。NVIDIA A100 的缓存层次结构包括以下几个层次:
- 寄存器文件(Register File):每个 SM(Streaming Multiprocessor)包含多个寄存器文件,寄存器用于存储线程私有的临时数据。A100 中的每个 SM 有 256KB 的寄存器文件。 - 寄存器访问速度非常快,但容量有限。
- L1 缓存/共享内存(L1 Cache/Shared Memory): - 每个 SM 配备了一个统一的 L1 缓存和共享内存。A100 的每个 SM 有 192KB 的 L1 缓存,可以配置为不同大小的共享内存和 L1 缓存组合。 - 共享内存是一种由线程块共享的高速内存,非常适合需要线程间通信的计算。 - L1 缓存则用于加速局部数据访问,减少全局内存访问延迟。
- L2 缓存: - A100 具有 40MB 的全局 L2 缓存,所有 SM 共享。 - L2 缓存主要用于减少对显存(DRAM)的访问延迟,提高全局内存访问的效率。
- 显存(HBM): - A100 的显存容量可以高达 80GB(HBM2e 内存)。 - 显存速度相对较慢,但容量大,主要用于存储大量数据和全局变量。
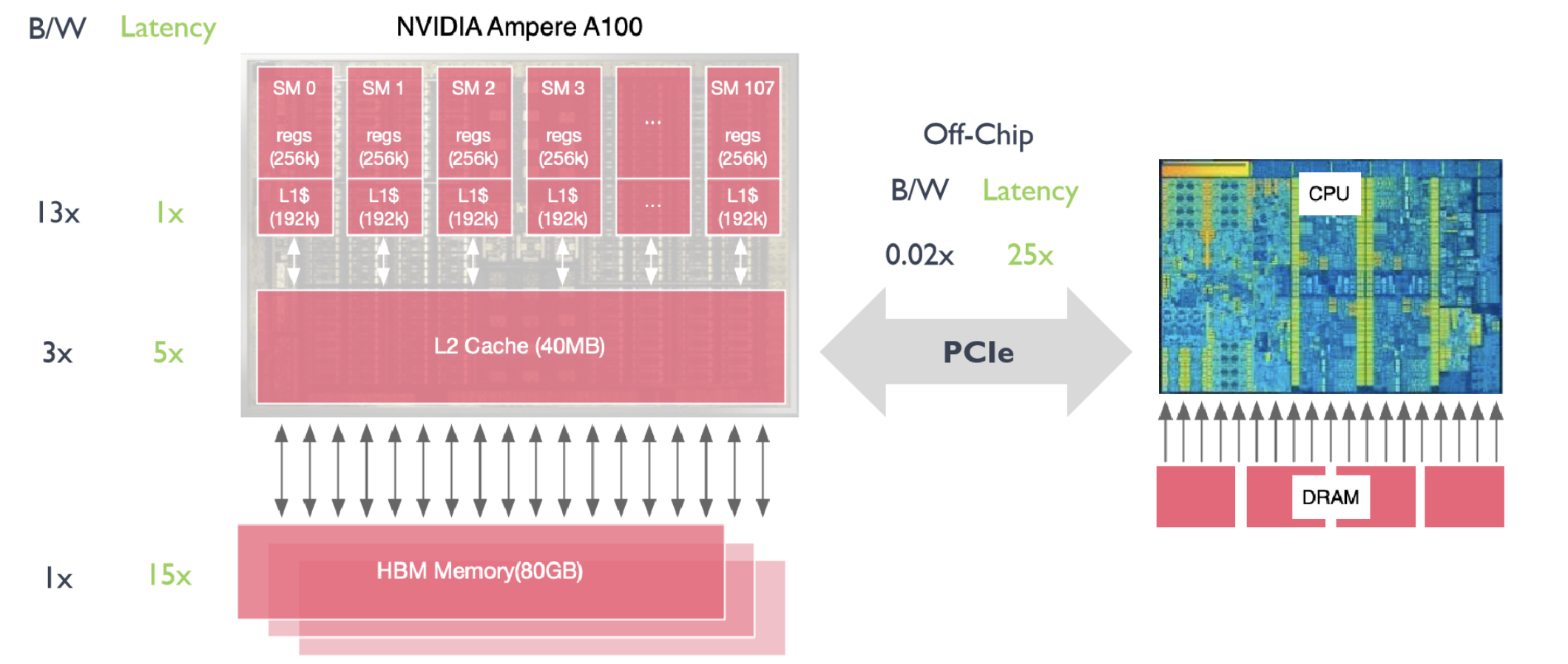
GPU 缓存的带宽和时延
带宽比较
在 GPU 中,内存带宽(bandwidth, B/W)是指数据可以被传输的速度。如果把主内存(HBM 内存)的带宽作为基准单位:
- L2 缓存的带宽是主内存的 3 倍。
- L1 缓存的带宽是主内存的 13 倍。
时延比较
在进行实际计算时,缓存的数据需要尽快使用完,然后读取下一批数据,这时会遇到时延(latency)问题。如果将 L1 缓存的时延作为基准单位:
- L2 缓存的时延是 L1 缓存的 5 倍。
- HBM 内存的时延是 L1 缓存的 15 倍。
CPU 和 GPU 之间的数据传输
假设我们用 CPU 将 DRAM(动态随机存取存储器)中的数据传输到 GPU 进行计算。由于较高的时延(比 L1 缓存高 25 倍),数据传输的速度会远低于计算的速度。因此,GPU 需要自己的高带宽内存 HBM(高带宽内存)来提高效率。GPU 和 CPU 之间的通信和数据传输主要通过 PCIe(外围组件互连)进行。
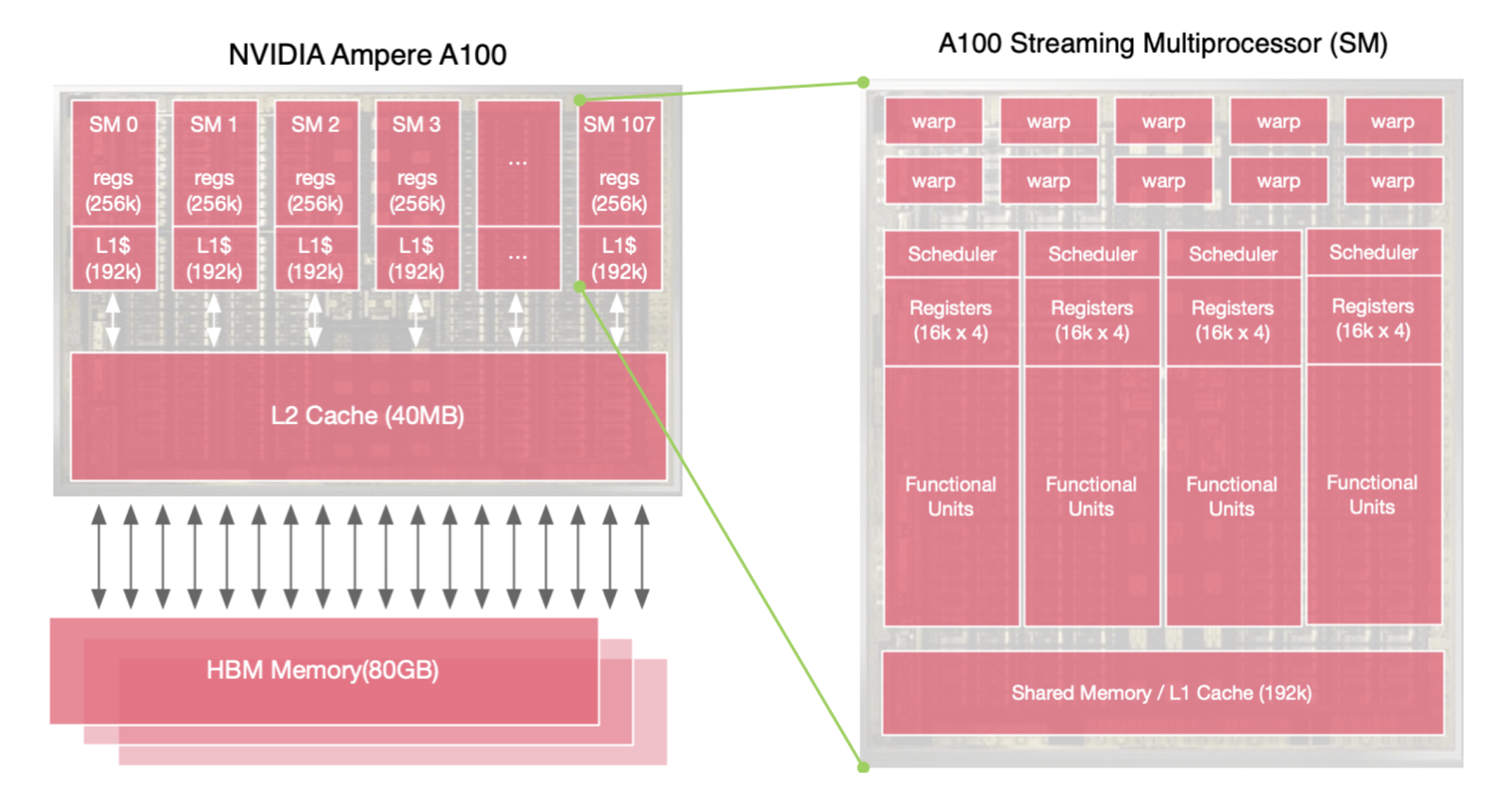
GPU 线程原理
GPU 的整体架构和单个 SM(流式多处理器)的架构是其设计的核心。SM 可以被看作是基本的运算单元,GPU 在一个时钟周期内可以执行多个 Warp。在一个 SM 中,有 64 个 Warp,其中每四个 Warp 可以单独并发执行。GPU 的设计者通过增加线程和 Warp 的数量来解决或掩盖延迟问题,而不是直接减少延迟时间。所以,在很多情况 SM 利用率能够更好地指示 GPU 的真实利用率。
为了能够处理更多的计算任务,GPU 的 SM 会选择超额配置线程。每个 SM 拥有 2048 个线程,整个 A100 具有超过 20 万个线程供程序使用。在实际场景中,程序通常无法用完所有线程,因此一些线程用于计算,一些线程负责数据搬运,还有一些线程在同步等待下一次计算。尽管很多时候 GPU 的算力利用率并不是非常高,但由于线程的超额配置,大多数应用程序不会感到速度缓慢。线程可以在不同的 Warp 上进行调度,确保高效处理各种任务。
GPU 架构解析
GPU 运算核心单元:TensorCore
GPU 计算单元的演变历程
在深入探讨 TensorCore 之前,先简要回顾一下 NVIDIA GPU 计算单元的演变历程。
- 在 Fermi 架构之前,处理核心被称为 Stream Processor(SPs)。这些 SPs 是用于执行并行计算任务的小型处理器,每个 SP 可以执行一个线程的计算任务。
- 在 Fermi 架构之后,NVIDIA 将处理核心更名为 CUDA Core,以强调其与 CUDA 编程模型的紧密集成。
- 2017 年推出的 Volta 架构,引入了张量核 Tensor Core 模块,用于执行融合乘法加法,标志着第一代 Tensor Core 核心的诞生。
TensorCore 工作原理
深度学习和机器学习中的许多任务都涉及大规模的矩阵运算,例如矩阵乘法(GEMM)和卷积(Conv)操作。这些运算通常需要大量的计算,并且在传统的 GPU 架构中,这些矩阵运算需要编码成 FMA(Fused-Multiply-Add)操作,再把结果从 ALU 到寄存器搬来搬去,每个浮点数计算都需要多个指令周期。这限制了 GPU 在处理这些任务时的效率,导致性能瓶颈。
Tensor Core 通过引入特殊的硬件单元来解决这个问题。它每周期能执行 4x4x4 GEMM,即 64 个 FMA。即每个 Tensor Core 提供了相当于 64 个 ALU,同时能耗上还有优势。
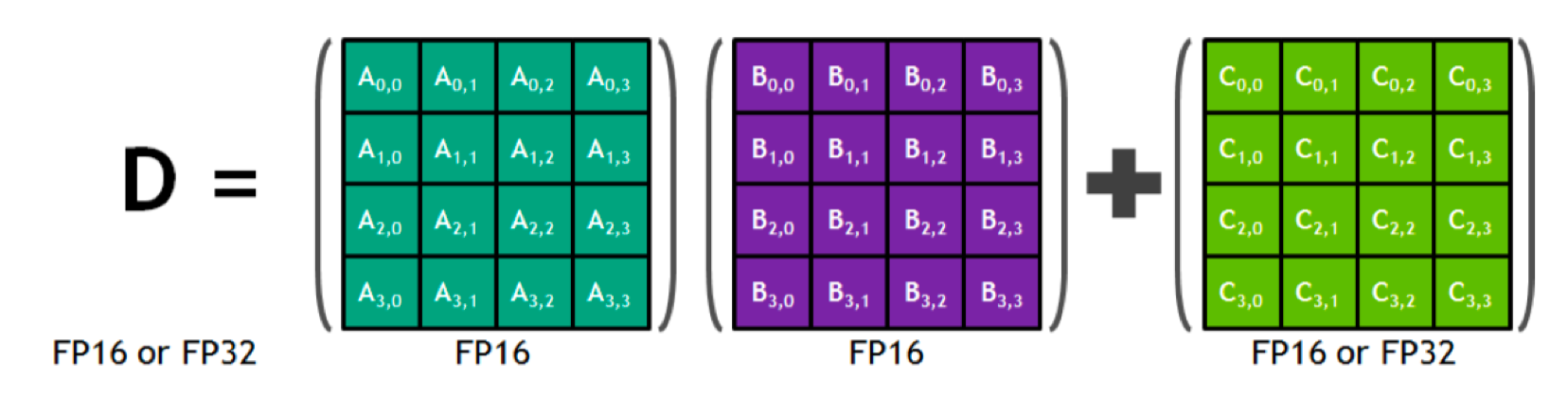
如上图所示,在执行运算 D=A*B+C,其中 A、B、C 和 D 是 4×4 矩阵。矩阵乘法输入 A 和 B 是 FP16 矩阵,而累加矩阵 C 和 D 可以是 FP16 或 FP32 矩阵。每个 Tensor Core 每个时钟周期执行 64 个 FP32 FMA 混合精度运算,一个 SM 中一共有 8 个 Tensor Core,所以每个时钟周期内总共执行 512 个浮点运算(8 个 Tensor Core × 64 个 FMA 操作/核)。
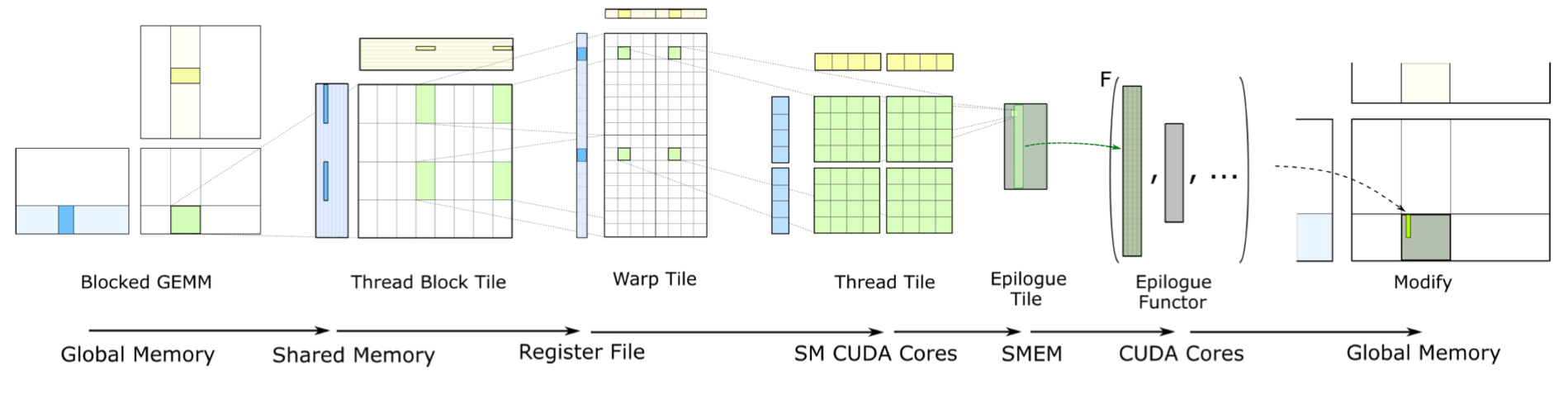
整个计算过程在硬件中运行如下:
GPU 通信:NVLink 和 NVSwitch
通信硬件
在机器内通信方面,有几种常见的硬件:
- 共享内存:多个处理器或线程可以访问相同的物理内存,这样它们可以通过读写内存中的数据来进行通信。共享内存适用于在同一台机器上进行并行计算的情况。
- PCIe(Peripheral Component Interconnect Express):PCIe 总线是连接计算设备的一种标准接口,通常用于连接 GPU、加速器卡或其他外部设备。通过 PCIe 总线,数据可以在不同的计算设备之间传输,以实现分布式计算。
- NVLink:NVLink 是一种由 NVIDIA 开发的高速互连技术,可实现 GPU 之间的直接通信。NVLink 可以提供比 PCIe 更高的带宽和更低的延迟,适用于要求更高通信性能的任务。
在机器间通信方面,常见的硬件包括:
- TCP/IP 网络:TCP/IP 协议是互联网通信的基础,它允许不同机器之间通过网络进行数据传输。在分布式计算中,可以使用 TCP/IP 网络进行机器间的通信和数据传输。
- RDMA(Remote Direct Memory Access)网络:RDMA 是一种高性能网络通信技术,它允许在不涉及 CPU 的情况下直接从一个内存区域传输数据到另一个内存区域。RDMA 网络通常用于构建高性能计算集群,提供低延迟和高吞吐量的数据传输。
NVLink 与 NVSwitch 简介
NVLink 和 NVSwitch 是英伟达推出的两项革命性技术,它们正在重新定义 CPU 与 GPU 以及 GPU 与 GPU 之间的协同工作和高效通信的方式。
- NVLink是一种先进的总线及其通信协议。NVLink 采用点对点结构、串列传输,用于中央处理器(CPU)与图形处理器(GPU)之间的连接,也可用于多个图形处理器(GPU)之间的相互连接。
- NVSwitch是一种高速互连技术,同时作为一块独立的 NVLink 芯片,其提供了高达 18 路 NVLink 的接口,可以在多个 GPU 之间实现高速数据传输。
NVLink
大模型通常有大量参数和复杂结构,需要处理大量数据。分布式训练将这些模型分成多个部分,由多个 GPU 或计算节点并行处理,每部分处理自己的数据子集。通过全局通信和参数同步进行梯度
传播,因此 GPU 之间的通信带宽非常重要。
在 NVLink 出现之前,GPU 之间通过 PCIe 总线进行数据交互。但 PCIe 存在带宽有限和延迟较高的问题。PCIe 4.0x16 的最大带宽是 64GB/s,而且在 GPU 之间传输数据时,需要通过 CPU 和主机内存,这会增加延迟并降低效率。然而,深度学习需要更高的带宽和更低的延迟,PCIe 无法满足需求。
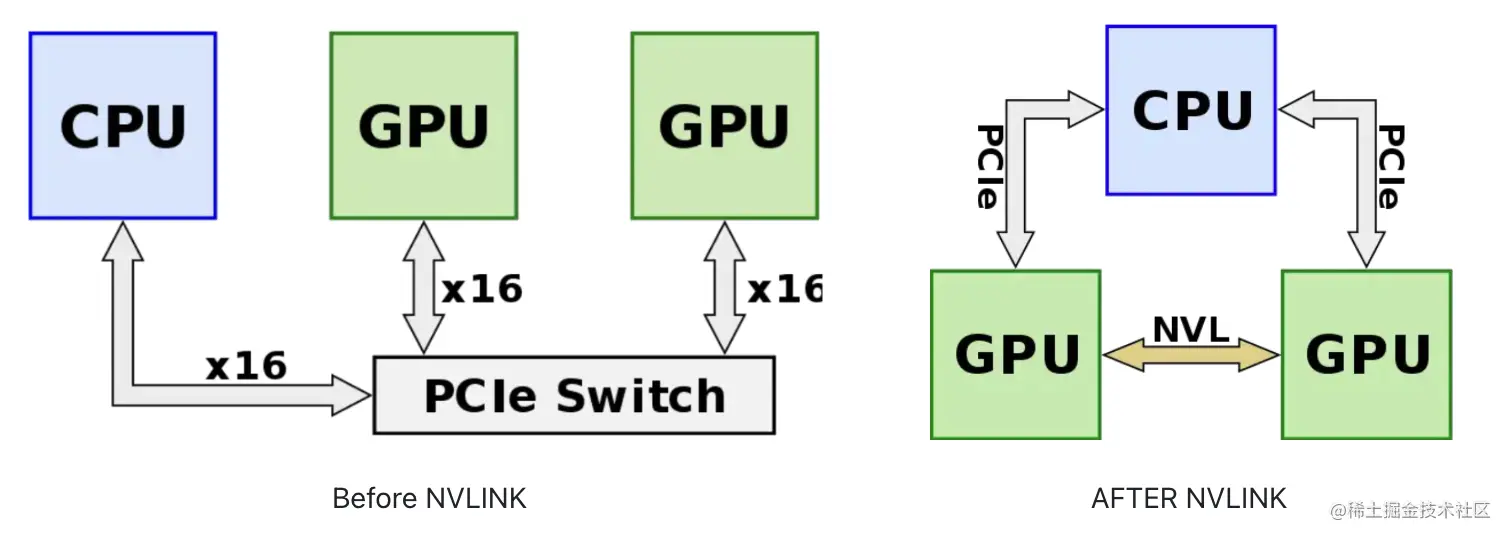
NVLink 提供高带宽、低延迟的通信通道,直接连接多个 GPU,实现快速高效的数据传输和共享。通过 NVLink,GPU 之间的数据交互可以直接进行,无需通过 CPU 和主机内存,大大减少了延迟和数据复制,提高了效率。NVLink 还提供了一致的内存空间,使多个 GPU 能共享同一内存,简化了程序设计和数据管理。
2022 年 10 月美国政府颁布的出口管制规定,出口至中国的芯片数据传输速率不得超过每秒 600GB 就是限制的这一部分,可以在很大程度上限制国内大模型的训练发展。所以 Nvidia 就通过降低 NVLINK 的速度,把 A100 砍成 A800,最大互联带宽到 400GB/s 的方式来符合政府的出口禁令。
NVSwitch
NVSwitch 是用于构建更大规模 GPU 集群的互连技术,可以支持数十个 GPU 之间的全互连通信。它适用于需要大规模并行计算和大数据处理的超级计算机和数据中心。
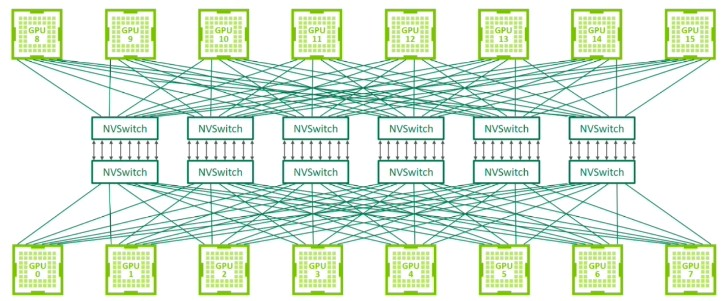
NVLink 和 NVSwitch 的区别可以理解为 NVLink 是解决小规模的 GPU 互联(2-8 个),而 NVSwitch 是为了解决大规模 GPU 互联的问题。
NVIDIA GPU 发展历程:从 Fermi 架构到 Hopper 架构
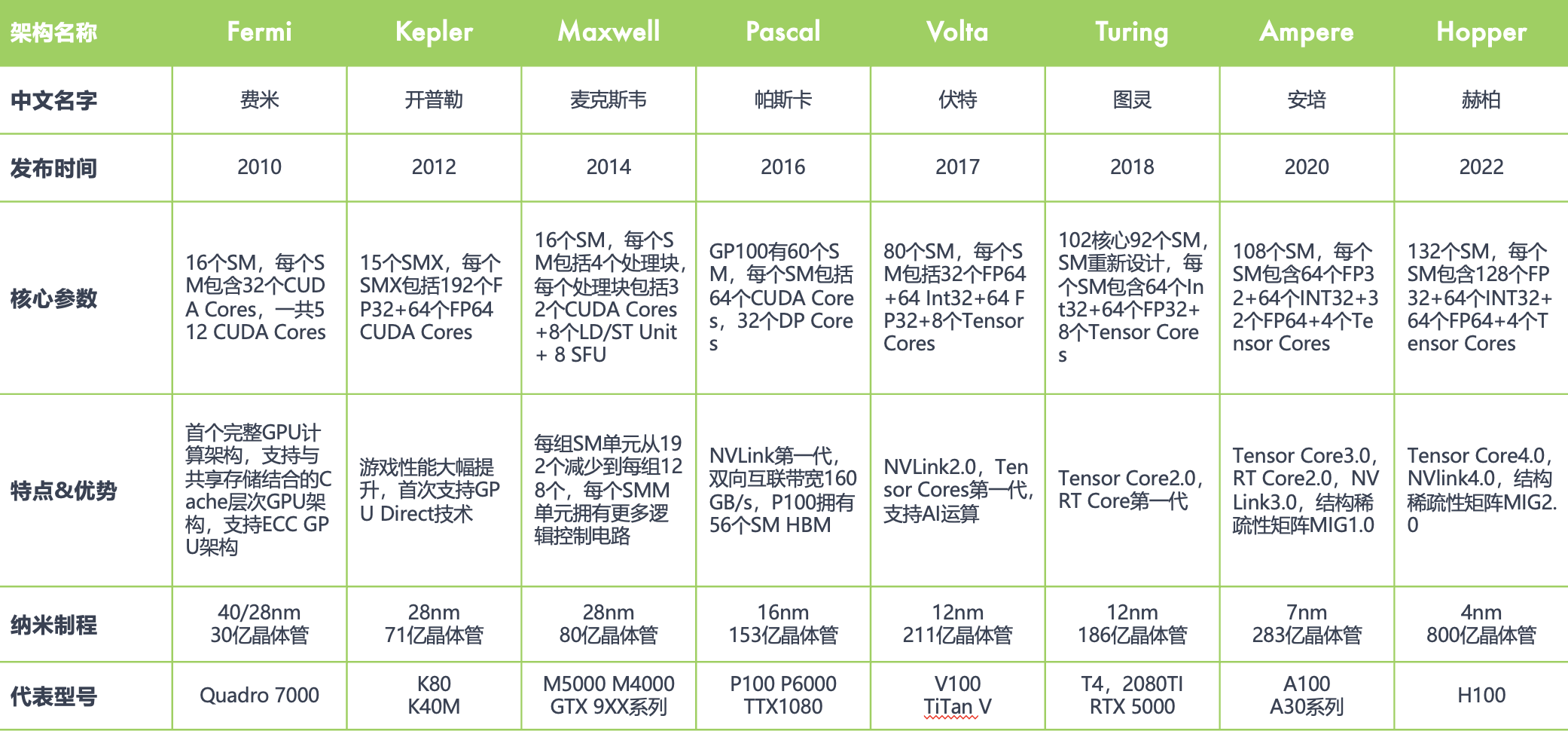
最后补充下关于 NVIDIA GPU 从 Fermi 架构到 Hopper 架构的整体发展历程。
参考资料
- AISystem/02Hardware/01Foundation at main · chenzomi12/AISystem · GitHub
- AISystem/02Hardware/02ChipBase at main · chenzomi12/AISystem · GitHub
- 如何评价人工智能芯片的优劣(一)衡量指标 - 知乎
- 如何评价人工智能芯片的优劣(二)屋顶线模型(Roofline model) - 知乎
- 如何评价人工智能芯片的优劣(三)评估工具和基准测试 - 知乎
- Roofline Model 与深度学习模型的性能分析
- GPU Arch:自顶向下分析 - 掘金
- AISystem/02Hardware/03GPUBase/01Works.md at main · chenzomi12/AISystem · GitHub
- AISystem/02Hardware/03GPUBase/03Concept.md at main · chenzomi12/AISystem · GitHub
- 深度了解 NVIDIA Ampere 架构 - NVIDIA 技术博客
- NVIDIA Hopper 深入研究架构 - NVIDIA 技术博客