引言
在过去的几年中,人工智能(AI)领域经历了迅猛的发展,尤其是大型语言模型(LLMs)的崛起,引发了广泛的关注和讨论。2023 年,生成式 AI 的投资激增,达到了 252 亿美元,是 2022 年的九倍。这不仅反映了技术的进步,也预示着未来巨大的应用潜力。
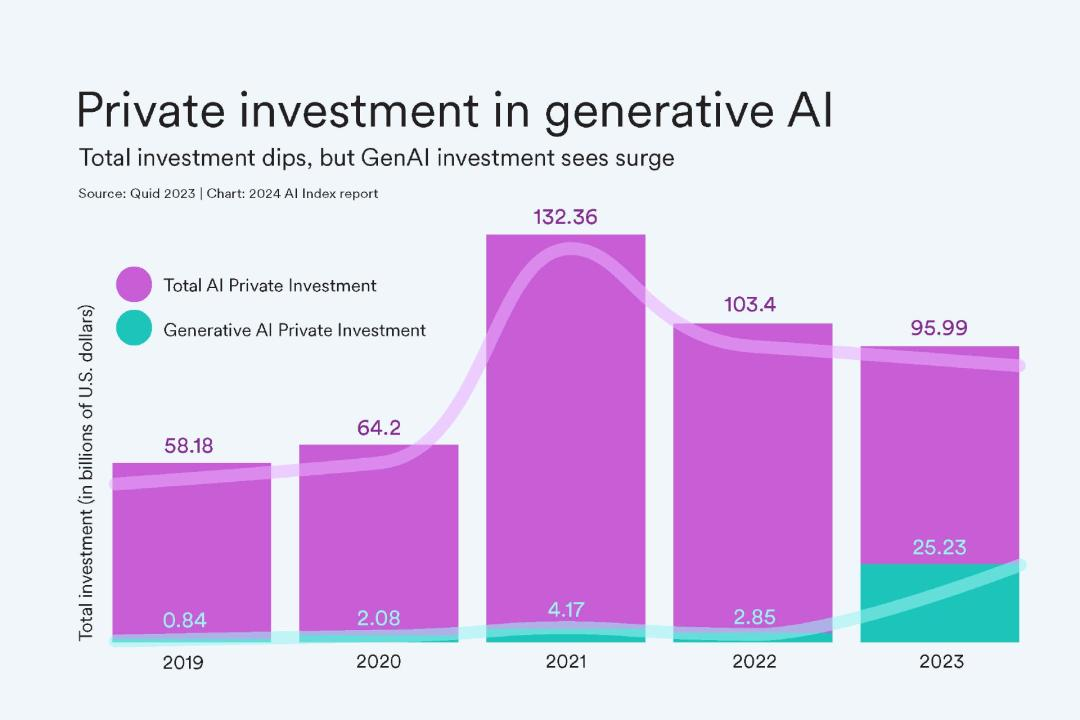
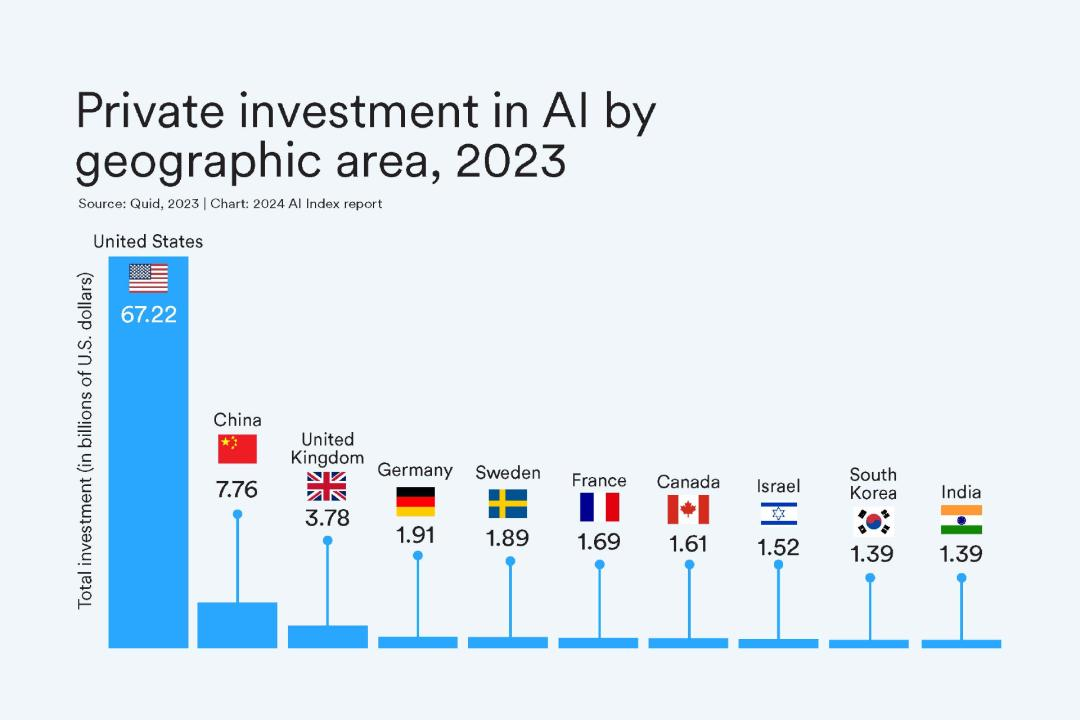
然而,随着技术的不断突破,AI 大模型的训练和推理成本也达到了前所未有的高度。例如,OpenAI 的 GPT-4 训练成本估计为 7800 万美元,而 Google 的 Gemini Ultra 更是高达 1.91 亿美元。尽管如此,这些技术进展正在推动 AI 在各个领域中的广泛应用和创新。
随着 AI 技术的不断进步,其对社会和行业的影响也越来越深远。本文将探讨 AI 大模型技术的变革及其对行业的影响,并对未来的发展趋势进行深入思考。
AI 大模型的技术变革和行业影响
近年来,AI 大模型(LLMs)技术取得了显著的进步,从基础模型架构到计算能力的提升,都经历了重要的变革。
大模型的定义与发展
AI 大模型(LLMs)是一类能够处理和生成自然语言的大型人工智能模型。这些模型经过大量数据训练,具备理解、生成和翻译文本的能力。自 2018 年 Transformer 架构引入以来,LLMs 的发展迅速。例如,OpenAI 的 GPT-4 和 Google 的 Gemini 是当前最先进的多模态模型,能够处理文本、图像,甚至音频。
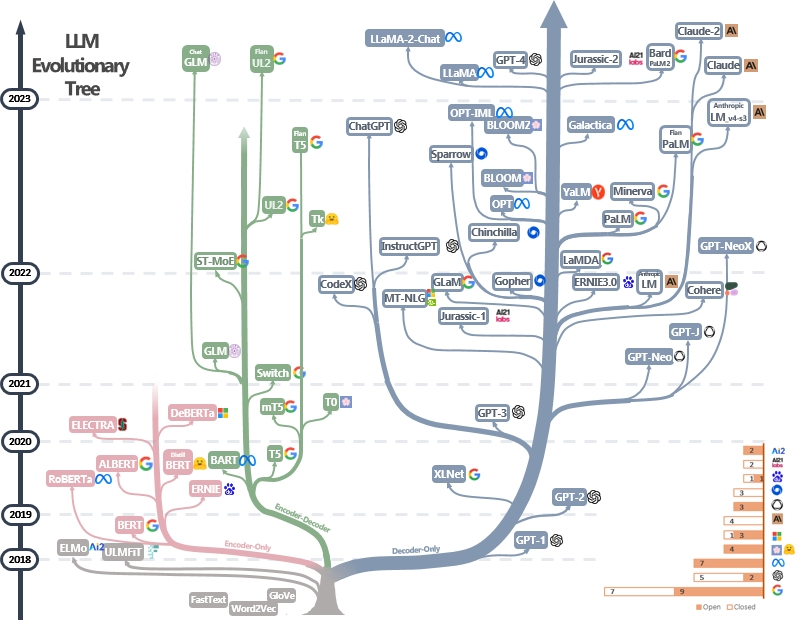
大模型的技术创新
Transformer 架构是现代 LLMs 的基础,其自注意力机制大大提升了模型处理长距离依赖关系的能力。随着研究的推进,Transformer 架构被不断优化,并在各类任务中表现出色。例如,GPT-4 在语言理解和生成方面表现优异,能够生成高质量的文本。此外,Google 的 Gemini 和其他多模态模型能够同时处理文本和视觉任务,大大扩展了 AI 的应用范围。这些模型在各种复杂任务中,如图像生成、代码生成和复杂推理等方面展示了卓越的性能。
为了满足这些模型的高性能需求,硬件技术也在快速发展。NVIDIA 最新发布的 GeForce RTX 40 系列显卡和 Blackwell B200 GPU 在性能上有显著提升。RTX 40 系列显卡不仅在游戏和内容创作中表现出色,还在 AI 任务中提供了强大的支持。Blackwell B200 GPU 相比之前的 H100 解决方案,训练性能提升了 4 倍,推理速度提高了 30 倍,并且能效提高了 25 倍。
大模型对产业链影响
上游产业:AI 硬件公司和云计算公司受益
AI 大模型的风口最直接的利好是 AI 硬件公司和云计算公司。就好像当年美国西部淘金时,买铲子和水的公司一样。从 OpenAI 发布 ChatGPT (2022 年 11 月 30 日)至今,NVIDIA 和 Microsoft 的股价分别上涨了 767.67%和 88.05%。NVIDIA 更是于 2023 年 6 月 18 日登顶市值全球第一的宝座。
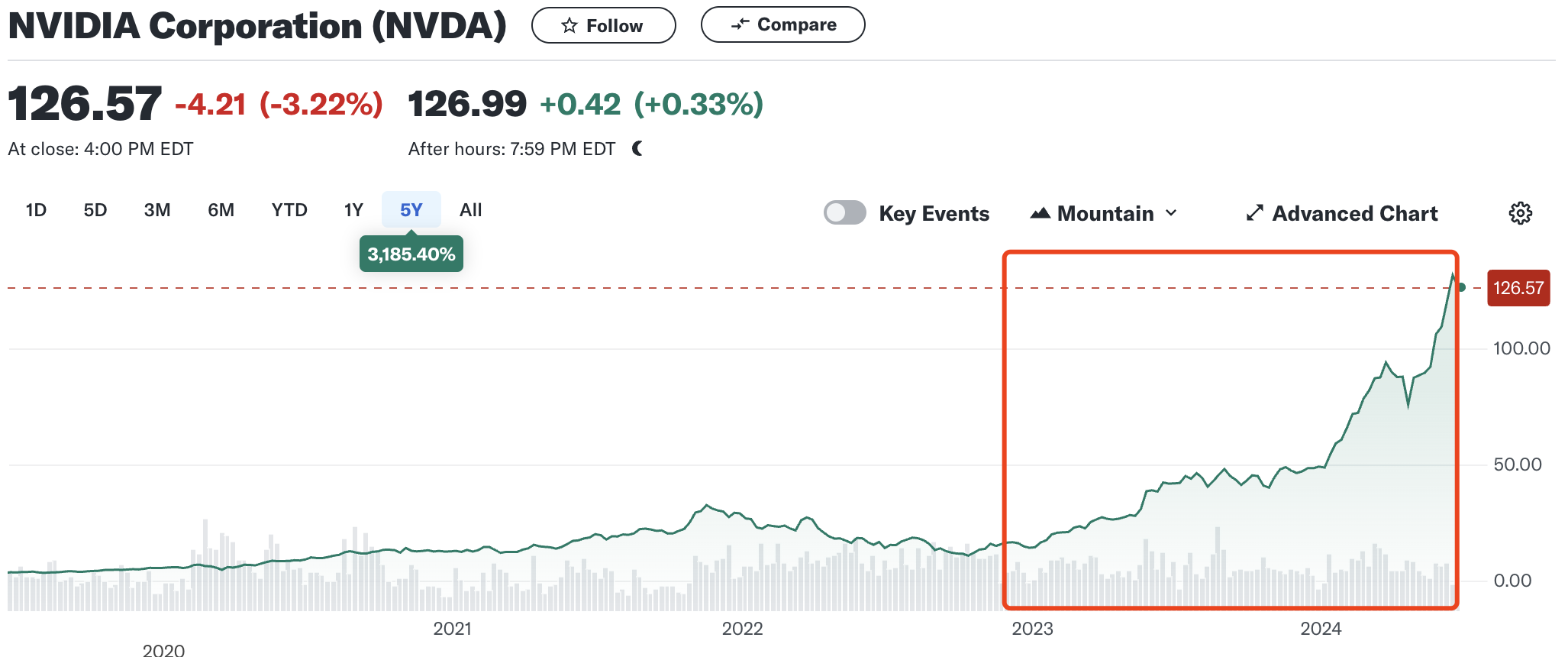
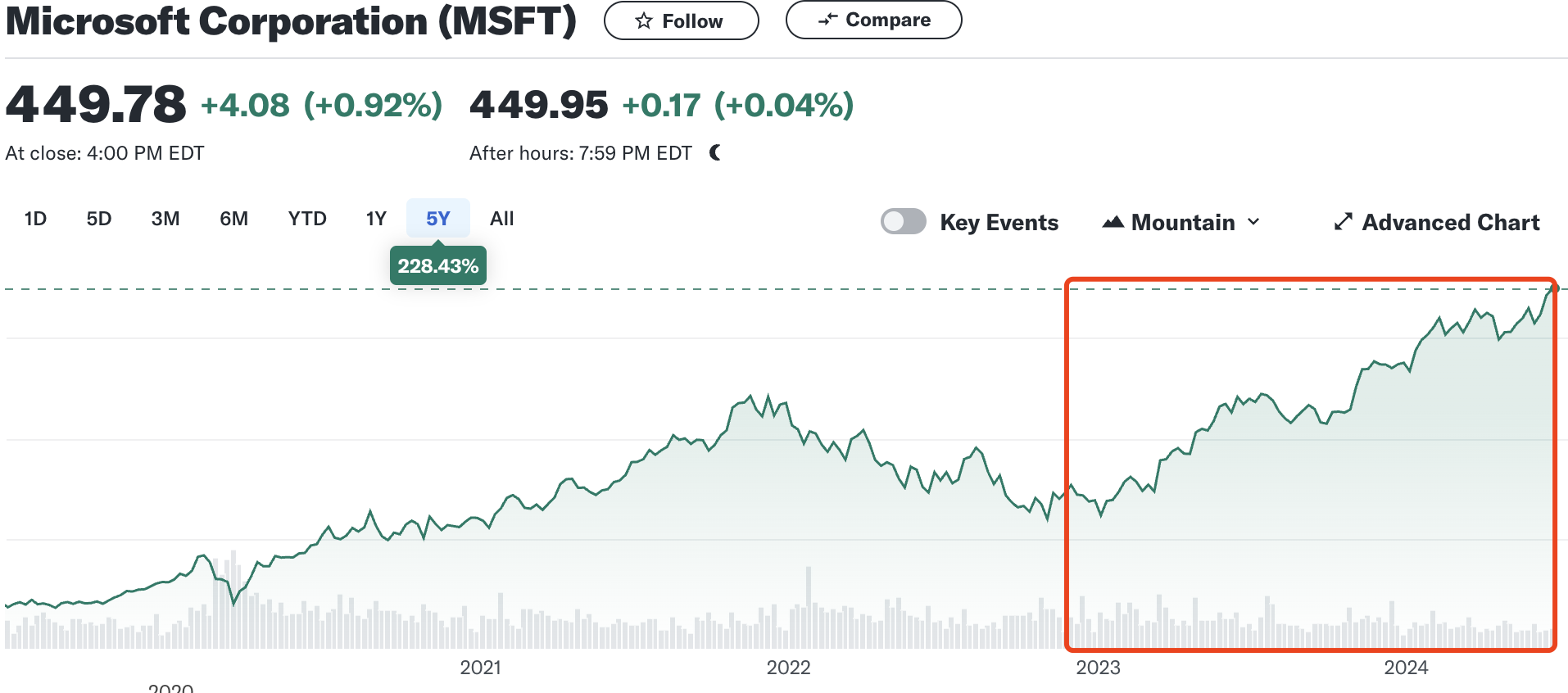
在以 ChatGPT 为代表的预训练大模型加速商业化落地,带来大量算力需求的同时,在国内以政府为主导的城市智能计算中心 AI 算力卡国产化进度较快,以华为昇腾为代表的 AI 计算卡,一度在国内一卡难求。
行业内:传统 AI 公司的优势逐渐减弱
在大模型技术的冲击下,传统 AI 公司的优势逐渐减弱。尽管这些公司迅速调整并自研大模型,但在资本市场上的表现平平。例如,商汤和云从科技在大模型风口下表现不佳。相反,以百川智能、智谱 AI、月之暗面、Minimax 和零一万物为代表的新兴 AI 公司正在快速发展。同时,大量资本涌入大模型赛道,国内的互联网大厂或发布自己的大模型,或通过投资形式参与大模型战场。
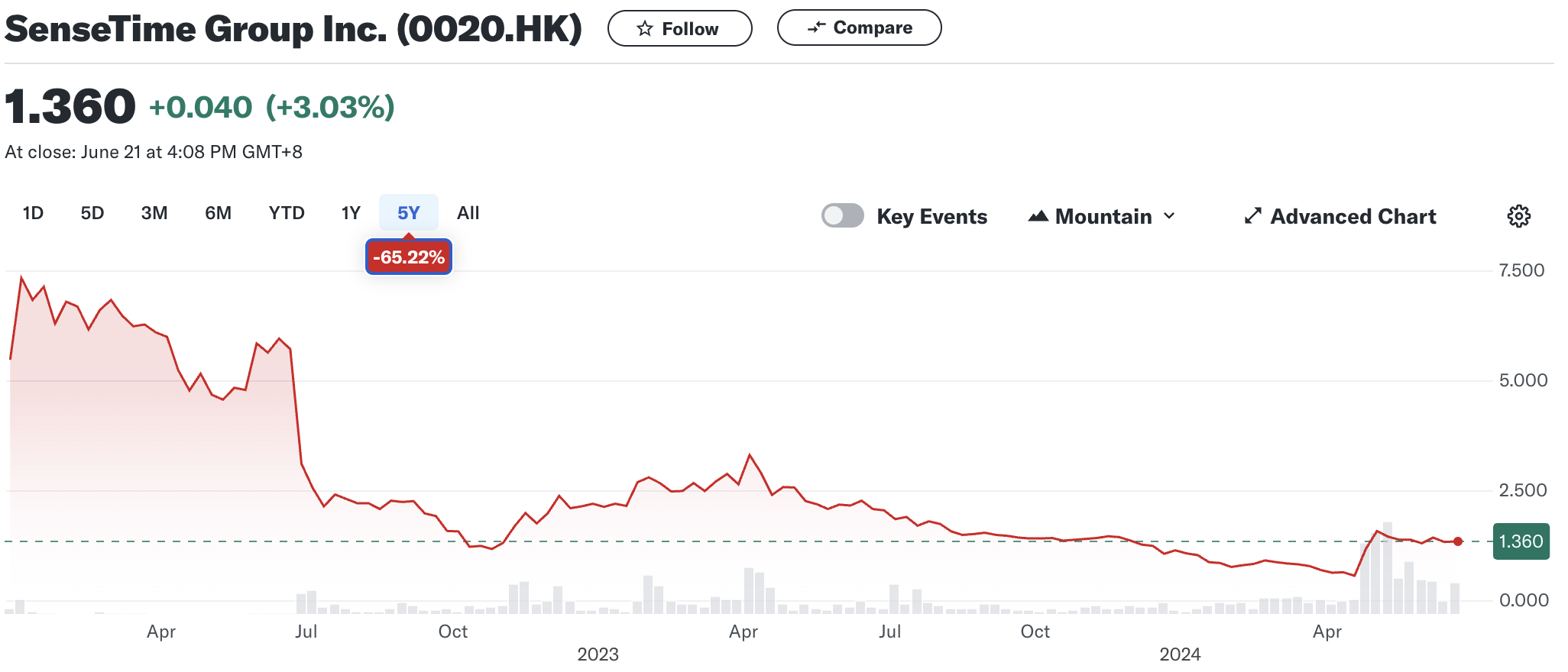
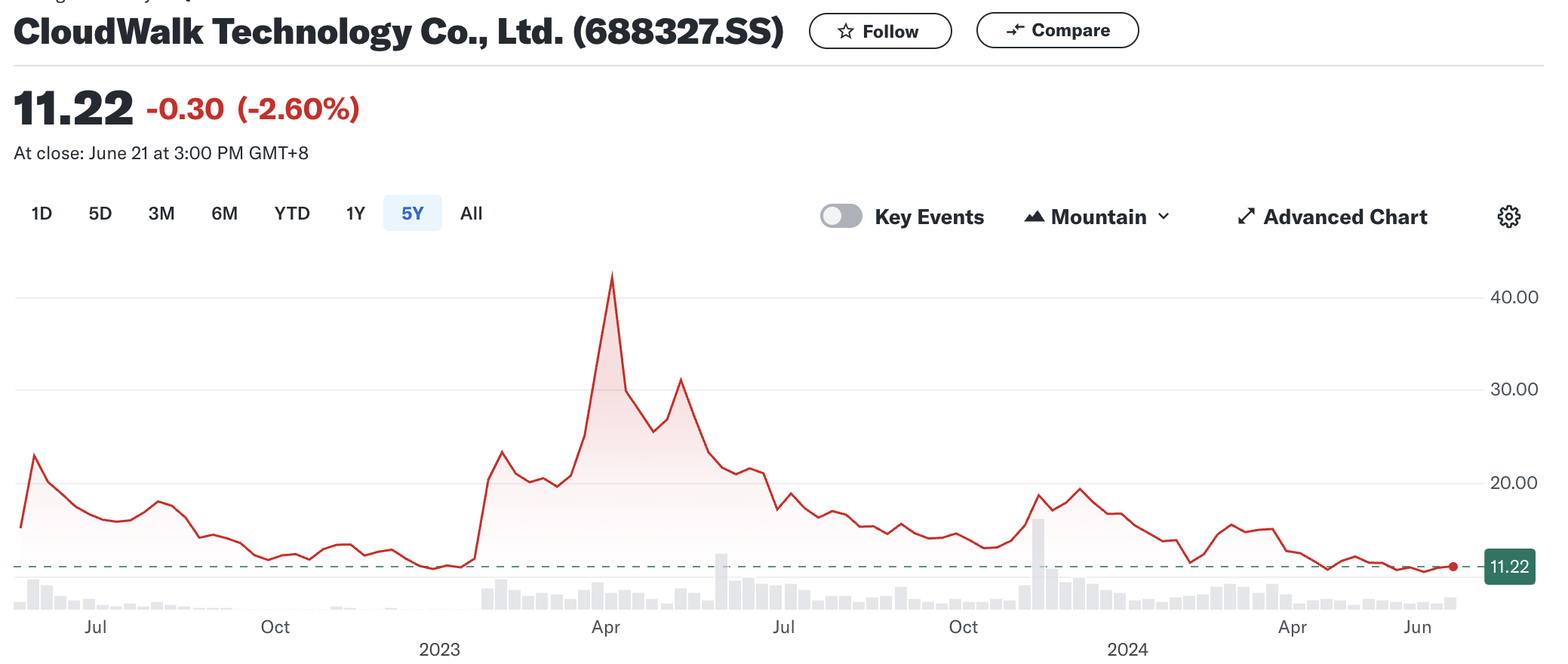
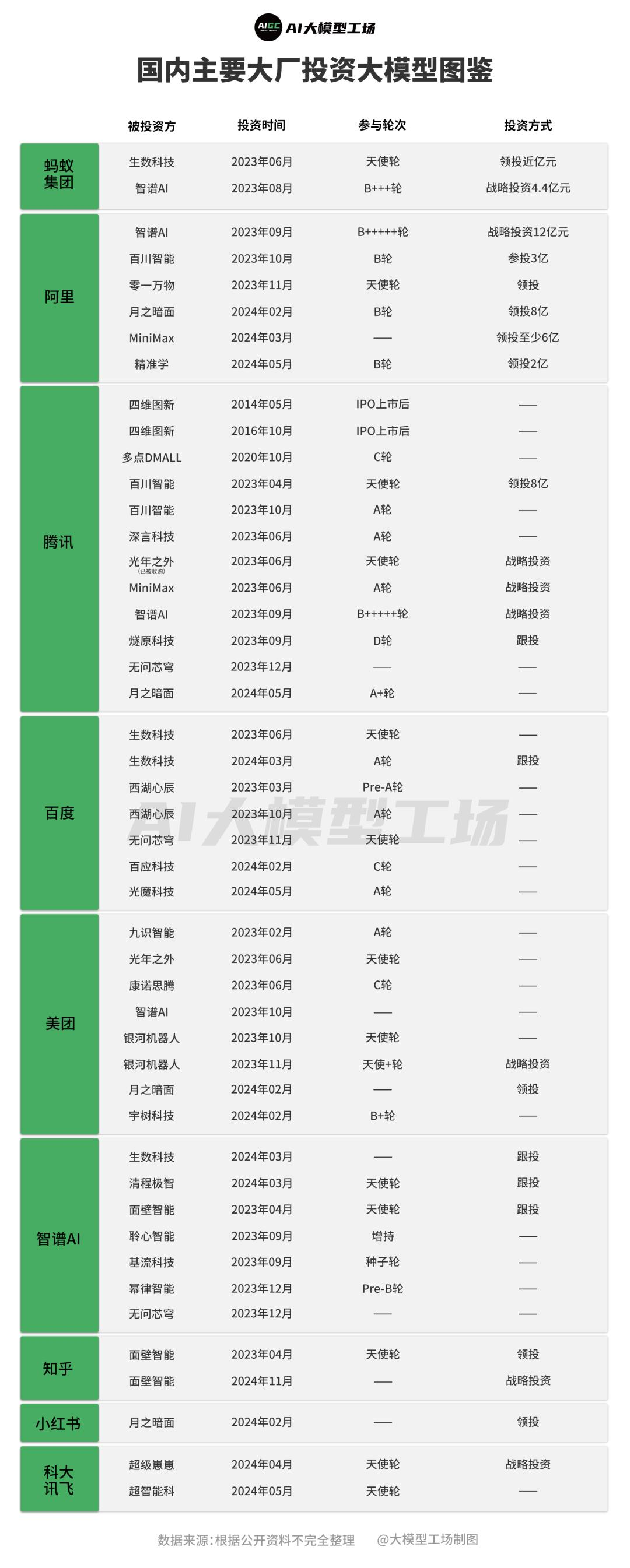
不过,传统 AI 公司也不会坐以待毙,目前看来基本可以分为三个路线:
- 回归小模型赛道,小模型的市场和业务还是会更明确一些,投入也 更可控。
- 发力视觉大模型的研发,毕竟传统 AI 公司在视觉领域的算法和基础建设积累还是足的。
- 放弃继续任何形式的自研大模型,全力投入 AI Agent 的研发。
下游产业:围绕 AIGC 的应用公司持续增多
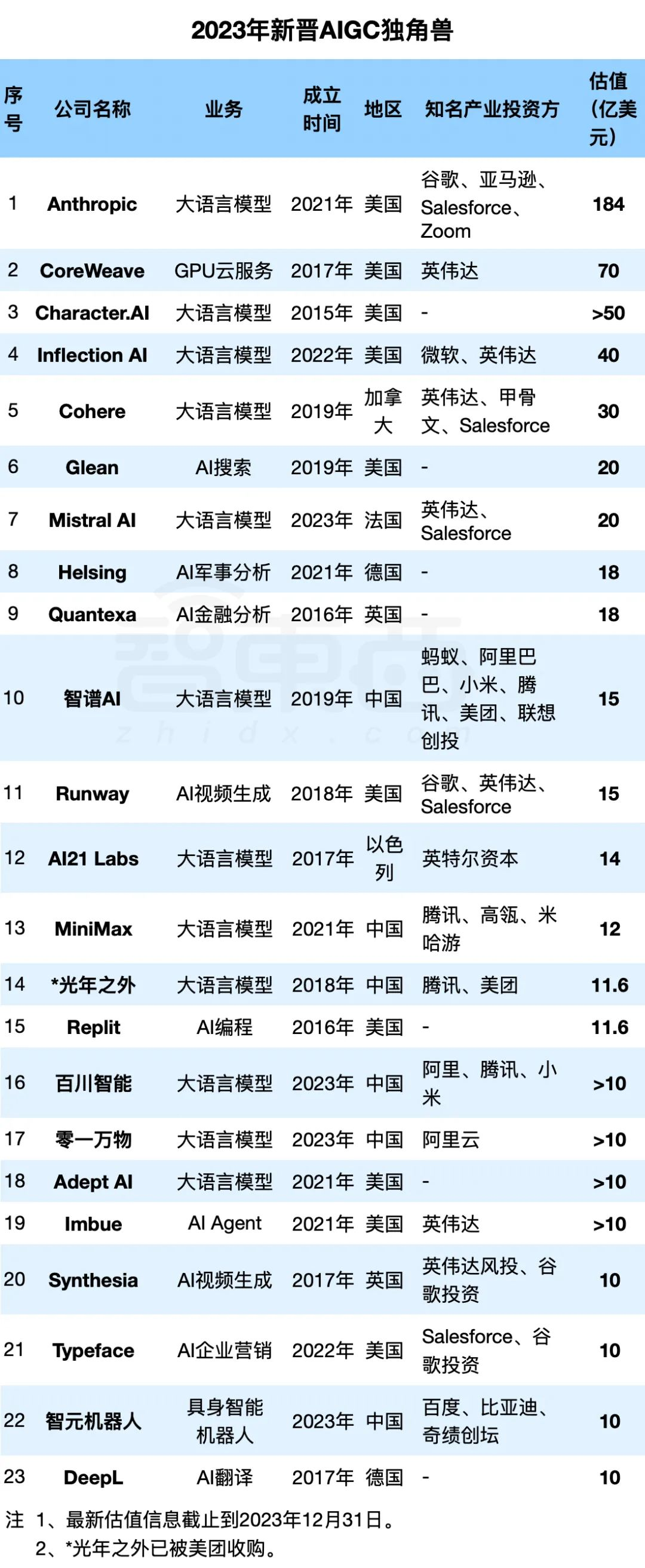
2023 年,生成式 AI 和大模型领域的新独角兽达 23 家,其中垂直行业研发公司有 10 家。而在 2023 年前,AIGC 应用的独角兽仅有 2 家(Midjourney 和 Jasper)。预计到 2024 年,AIGC 应用领域的独角兽将继续增加。
对 AI 行业的思考与未来展望
大模型训练成本持续增加,自研大模型将成为巨头的特权
目前自研大模型主要有三条路线(成本从高到低):
- 从零开始自行设计模型架构,使用大量数据和算力进行模型预训练。代表公司有 OpenAI(GPT-4)和 Google(Gemini)。
- 基于开源成熟的模型结构,少量修改模型架构,进行模型预训练。代表公司有阿里(Qwen)和零一万物(Yi 模型)。
- 基于开源的模型权重,用少量数据进行继续训练或微调。大部分大模型公司属于这一类。
随着数据壁垒逐步加深,高质量的免费数据将越来越少。同时,算力成本持续增加。目前一台 8 卡 NVIDIA A800 服务器的价格基本在 100 万到 150 万元之间,而这仅是一台服务器。一般进行预训练的集群规模都是二三十台到上百台不等。大型互联网公司的 GPU 集群甚至达到了万卡级别。因此,中小规模的 AI 公司未来基本很难有在自研大模型的牌桌上继续停留的资格了,更多是采用方案 3 利用垂直领域的数据进行模型的继续训练和微调。
大模型推理成本持续降低,利好大模型应用创新
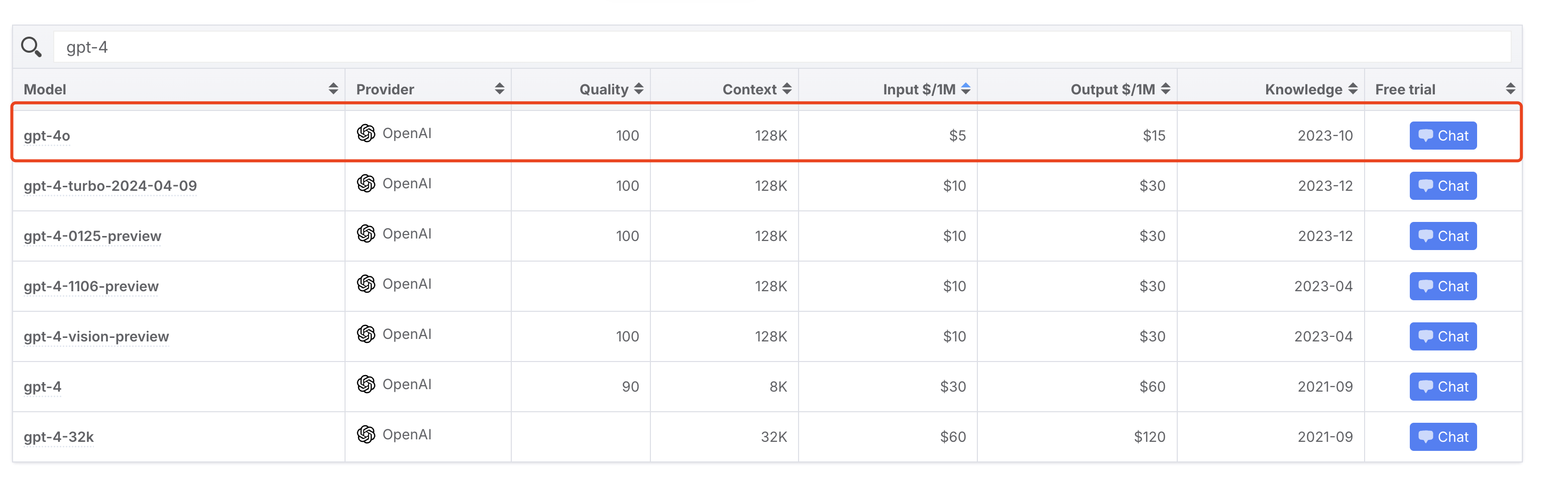
去年,OpenAI 的 GPT-4 API 的输入 token 价格为$30/1M token,输出 token 价格为$60/1M token,相当于 100 万个单词,价格 60 美元。截至 2024 年 6 月 14 日,OpenAI 最新的 GPT-4 价格为输入 token 价格$5/1M token,输出 token 价格$15/1M token,成本下降为原来的四分之一。
国内 API 价格竞争更加激烈。deepseek-v2 的 API 输入 token 价格$0.14/1M token,输出 token 价格$0.28/1M token,开启了国内大模型的价格战。以下是 2024 年 5 月 24 日智东西收集的数据。
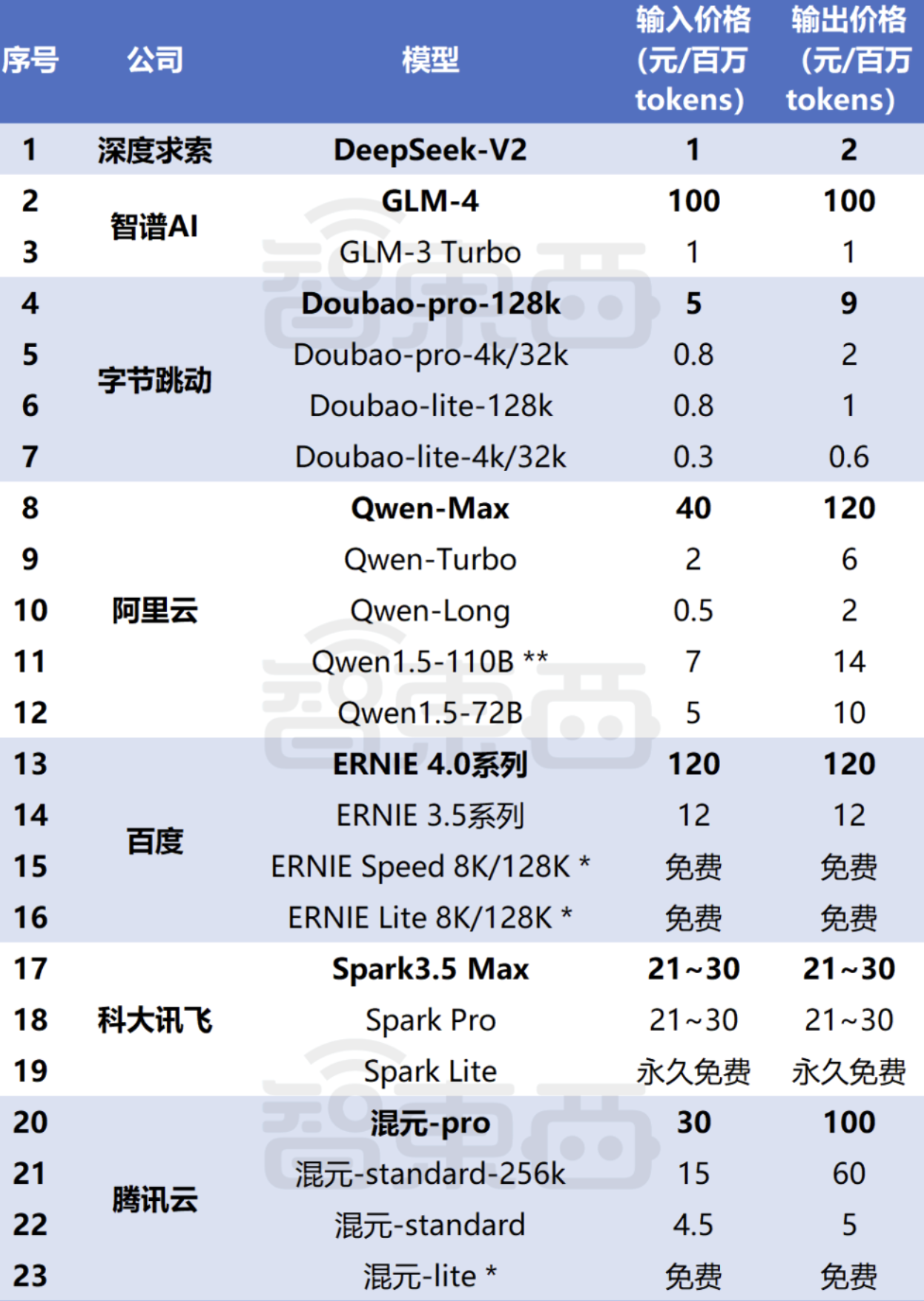
一方面是资本和大厂其他部门的补贴和输血,另一方面也得益于推理技术的提高(相比于训练技术,推理技术进步更快)。
推理 API 价格的持续降低,大大利好 AI Agent 的开发,尤其是类似 AutoGPT 或 MetaGPT 这种需要反复调用大模型 API 完成复杂应用的智能体。
大模型的 iPhone 时刻尚未到来
虽然 OpenAI 于 2024 年 1 月发布 GPT Store,当天就上线了超过 300 万个 GPTs。有业内人士认为大模型的 iPhone 时刻已经到来。然而,过去半年里,用户定制的 GPT 并没有出现杀手级应用,反而是微软宣布将在 7 月 14 日关闭 Copilot GPT 服务(类似 OpenAI 的 GPT Builder 和 GPT Store)。
我个人感觉 AI Agent 的能力还太弱,根本无法完成复杂的日常任务,总不能天天用大模型来写诗、聊天和读文档吧?
技术从来不决定工作和生活
在过去的一年多时间里,互联网充斥着大量渲染焦虑的信息,比如:"程序员很快要被 AI 取代了"。下面谈谈我的看法:
不可否认,AI 确实加速了程序员日常工作的效率,写代码已经离不开 ChatGPT 了,很多基础代码和文档都可以用 AI 快速生成。然而,时间久了会发现,AI 写代码是一个好手,但目前 AI 无法完成架构设计或根据实际业务给出具体的解决方案,甚至我还得非常认真地检查 AI 写的代码是否正确。所以,谁在给谁打工?
在我看来,AI 永远只是一个效率工具,它不会创造需求,也不会改变目的。例如,记录笔记这个需求,从古老的甲骨文到现在的语音输入和 AI 总结,需求和目的并没有变化,只有技术在不断进步。
最后
每个新时代一定会将一些公司推向全球市场的顶部。想想 PC 互联网时代的微软和 Google、移动互联网时代的苹果,现在是英伟达。所以新的时代要来了?
参考资料
- The current state of AI, according to Stanford's AI Index | World Economic Forum
- AI Index Report 2024 – Artificial Intelligence Index
- AI now beats humans at basic tasks — new benchmarks are needed, says major report
- GeForce At CES 2024: SUPER GPUs, 14 New RTX Games, Accelerating Gen AI, G-SYNC Innovations, RTX Remix Open Beta, Twitch Enhanced Broadcasting & More | GeForce News | NVIDIA
- Nvidia’s next-gen AI GPU is 4X faster than Hopper: Blackwell B200 GPU delivers up to 20 petaflops of compute and other massive improvements | Tom's Hardware
- ChatGPT 引爆算力需求!华为昇腾领跑 AI 超算,这些上市公司布局相关业务
- 2023 年冲出 23 家新晋 AIGC 独角兽:最高估值千亿,6 家来自中国-36 氪
- 微软 Copilot GPTs 下月停服!发布仅 3 个月,却因无法盈利斩杀_用户_Builder_消费者
关于作者:核动力蜗牛(微信公众号:yidooxyz,博客:异度部落格) 转载声明:本文版权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。