概述
提示词工程(Prompt Engineering)是一种优化和设计提示词的过程,旨在更好地引导和控制生成式人工智能(如 GPT-4)的输出。这种技术在自然语言处理(NLP)和生成式模型领域中尤为重要,因为提示词的设计和优化可以显著影响生成模型的表现和输出质量。
大语言模型设置
在介绍提示词工程之前,我们需要先了解一下大语言模型的一些基本设置。通过配置一些参数,可以获得不同的提示结果。调整这些设置对于提高响应的可靠性至关重要。
以下是使用不同 LLM 提供商时常见的一些设置:
Temperature
Temperature 参数值越小,模型返回的结果越确定。调高该参数值,大语言模型可能会返回更随机的结果,从而带来更多样化或更具创造性的输出。在实际应用中,对于质量保障(QA)等任务,可以设置较低的 temperature 值,以促使模型返回更真实和简洁的结果。对于诗歌生成或其他创造性任务,可以适当调高 temperature 参数值。
Top_p
Top_p 也是用于控制模型返回结果的多样性。如果需要准确和事实性的答案,可以调低该参数值;如果希望答案更加多样化,则调高该参数值。通常建议只调整 temperature 或 top_p 其中一个参数,而不是同时调整两个。
Max Length
通过调整 max length 可以控制模型生成的 token 数量。指定 Max Length 有助于防止模型生成过长或不相关的响应,并有助于控制成本。
Stop Sequences
Stop sequence 是一个字符串,用于阻止模型继续生成 token。通过指定 stop sequences,可以控制模型响应的长度和结构。例如,可以添加 “11” 作为 stop sequence,来限制模型生成不超过 10 项的列表。
Frequency Penalty
Frequency penalty 是对生成的下一个 token 施加的惩罚,惩罚程度与 token 在响应和提示中出现的次数成正比。frequency penalty 越高,某个词再次出现的可能性就越小。通过对重复出现的 token 施加更高的惩罚,可以减少响应中单词的重复。
Presence Penalty
Presence penalty 也是对重复 token 施加的惩罚,但与 frequency penalty 不同的是,它对所有重复 token 的惩罚是相同的。出现两次的 token 和出现 10 次的 token 受到相同的惩罚。此设置可防止模型在响应中过于频繁地生成重复的词。如果希望模型生成多样化或创造性的文本,可以设置较高的 presence penalty;如果希望模型生成更专注的内容,可以设置较低的 presence penalty。
与 temperature 和 top_p 一样,通常建议只调整 frequency penalty 或 presence penalty 其中一个参数,而不是同时调整两个。
提示词工程简介
基本要素
提示词的基本要素可以分为:
- 指令/问题:明确要模型执行的特定任务或指令。
- 上下文:可选,包含外部信息或额外的上下文信息,引导语言模型更好地响应。
- 输入数据:可选,用户输入的内容或问题。
- 输出指示:可选,指定输出的类型或格式。
例如:
请将文本分为中性、否定或肯定 |
在上面的示例中, 指令是“请将文本分为中性、否定或肯定”; 上下文没有提供; 输入数据:“我觉得食物还可以。”; 输出指示为“情绪:”。
常见提示词示例
常见的提示词示例可以参考Prompt Engineering Guide中的提示词示例,文中给出了例如:文本概括、信息提取、问答、文本分类、对话、代码生成和推理等常见任务的示例。
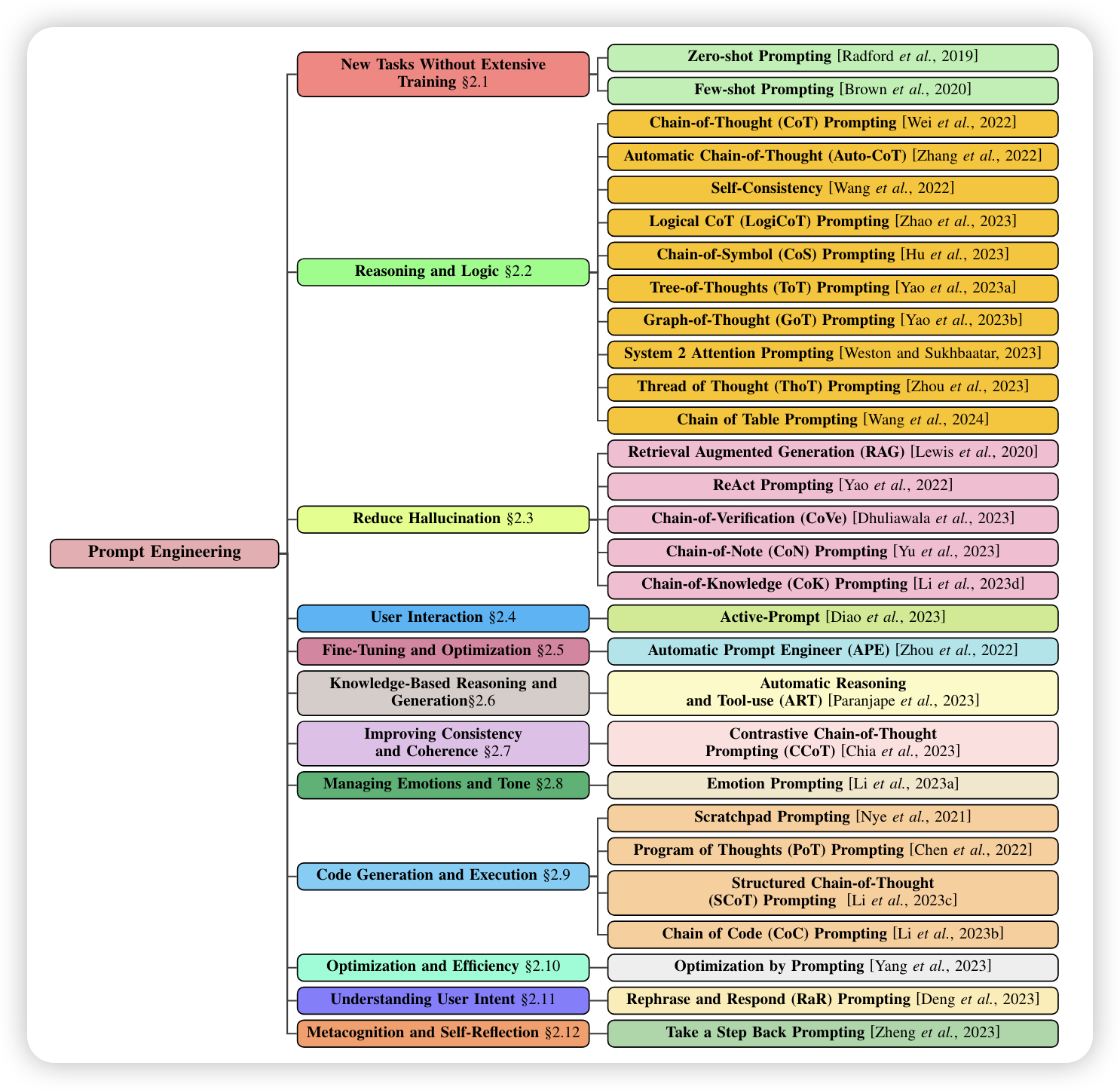
提示词工程高级技术
随着大模型技术的高速发展,提示词工程已经从一个单纯的大模型使用技巧,演变成了一个独立的研究方向,形成了自己的研究体系。越来越多的
AI
研究人员投入提示词工程的研究,通过提示词工程提升或者稳定大语言模型的回答结果。下图是论文A Systematic Survey of Prompt
Engineering in Large Language Models: Techniques and
Applications中整理的目前主流的提示词工程技术: