Spark 架构简介
Spark 是一个 master/slave 架构的分布式系统,它的架构主要包含有
- Spark Driver
- Spark Executor
- Cluster
 %201.png)
%201.png)
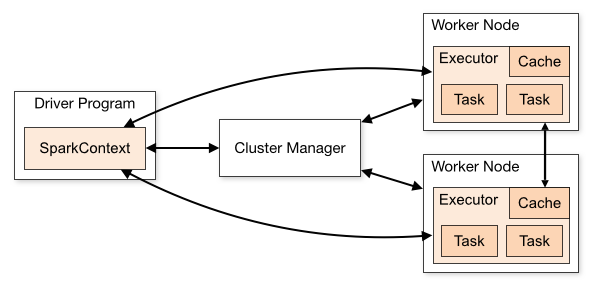
一个 Spark 集群一般拥有单个的 Driver 和多个的 Executor。Spark Driver 和 Executor 都是独立运行的 JVM 进程,它们可以运行在单台机器上,也可以运行在多台机器上。
Spark Driver
Spark Driver 是一个 Spark Application 的主入口,它可以用 Scala,Python 或者 R 进行编写。一个 Spark Driver 包含有一个 SparkContext,这是整个 Spark Application 中最核心的组件。同时,还包含有 DAGScheduler, TaskScheduler, BackendScheduler 和 BlockManager 等组件用于将用户代码转换为 Spark job 运行在集群当中。Spark Driver 的主要功能包括:
- 负责协调 Job 的运行和以及 Cluster Manager 进行交互。
- 将 RDD 转换为执行的 DAG 图,同时把 DAG 图分为不同的 Stage
- 将 Job 切割成更小的执行单元,Task,由 Executor 执行。
- 启动一个 HTTP Server,端口为 4040。这个 Web UI 会把 Spark Application 运行时的信息展示出来。
Spark Executor
Spark Executor 是 Task 的实际执行者。每个 Application 的 Executor 数量可以通过配置指定(Static Allocation)或者有 Spark 动态分配(Dynamic Allocation)。Executor 的主要功能包括:
- 负责所有的数据处理工作
- 用于读取和写入外部数据源
- 缓存着计算过程中的数据
Cluster Manager
严格上说 Cluster Manager 并不是 Spark 的一部分,而是一个外部的 Service(除了 Standalone)。Spark Driver 会和其进行交互用于从集群里获取资源(CPU,Memory 等)。目前 Spark 支持 4 种 Cluster Manager:
- Standalone:这是一种 Spark 自带的集群管理模式,设计也比较简单。
- Apache Mesos:Mesos 是一种通用的集群资源管理服务,用于管理 MapReduce 应用或者其他类型的应用。
- Hadoop YARN :YARN 是由 Hadoop 2.0 引入的集群资源管理服务。
- Kubernetes:Kubernetes 是一种管理 containerized 的应用的服务。Spark 2.3 以后引入了对 Kubernetes 的支持。
至于选择使用哪一种 Cluster Manager,完全取决于生产环境以及业务场景,并没有绝对的优劣。